
详解Ubuntu16.04下Hadoop 2.7.3的安装与配置
一、Java环境搭建
(1)下载JDK并解压(当前操作系统为Ubuntu16.04,jdk版本为jdk-8u111-Linux-x64.tar.gz)
新建/usr/java目录,切换到jdk-8u111-linux-x64.tar.gz所在目录,将这个文件解压缩到/usr/java目录下。
tar -zxvf jdk-8u101-linux-x64.tar.gz -C /usr/java/
(2)设置环境变量
修改.bashrc,在最后一行写入下列内容。
sudo vim ~/.bashrc
export JAVA_HOME=/usr/java/jdk1.8.0_111 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$PATH

运行如下命令使环境变量生效。
source ~/.bashrc
打开profile文件,插入java环境配置节。
sudo vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_111 export JAVA_BIN=$JAVA_HOME/bin export JAVA_LIB=$JAVA_HOME/lib export CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar export PATH=$JAVA_HOME/bin:$PATH

打开environment 文件,追加jdk目录和jdk下的lib的目录,如下所示。
sudo vim /etc/environment
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/usr/java/jdk1.8.0_111/lib:/usr/java/jdk1.8.0_111"

使配置生效
source /etc/environment
验证java环境是否配置成功
java -version
二、安装ssh-server并实现免密码登录
(1)下载ssh-server
sudo apt-get install openssh-server
(2)启动ssh
sudo /etc/init.d/ssh start
(3)查看ssh服务是否启动,如果有显示相关ssh字样则表示成功。
ps -ef|grep ssh

(4)设置免密码登录
使用如下命令,一直回车,直到生成了rsa。
ssh-keygen -t rsa
导入authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试是否免密码登录localhost
ssh localhost
关闭防火墙
ufw disable
三、安装Hadoop单机模式和伪分布模式。
(1)下载hadoop-2.7.3.tar.gz,解压到/usr/local(单机模式搭建)。
sudo tar zxvf hadoop-2.7.3.tar.gz -C /usr/local
切换到/usr/local下,将hadoop-2.7.3重命名为hadoop,并给/usr/local/hadoop设置访问权限。
cd /usr/local sudo mv hadoop-2.7.3 hadoop sudo chmod 777 /usr/local/hadoop
(2)配置.bashrc文件
sudo vim ~/.bashrc
(如果没有安装vim,请用 sudo apt install vim 安装。)
在文件末尾追加下面内容,然后保存。
#HADOOP VARIABLES START export JAVA_HOME=/usr/java/jdk1.8.0_111 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END
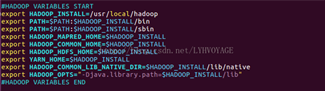
执行下面命令,使添加的环境变量生效:
source ~/.bashrc
(3)hadoop配置 (伪分布模式搭建)
配置hadoop-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
# The java implementation to use. export JAVA_HOME=/usr/java/jdk1.8.0_111 export HADOOP=/usr/local/hadoop export PATH=$PATH:/usr/local/hadoop/bin

配置yarn-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/ JAVA_HOME=/usr/java/jdk1.8.0_111

配置core-site.xml,在home目录下创建 /home/lyh/hadoop_tmp目录,然后在core-site.xml中添加下列内容。
sudo mkdir /home/lyh/hadoop_tmp
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/lyh/hadoop_tmp</value>
</property>
</configuration>

配置hdfs-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
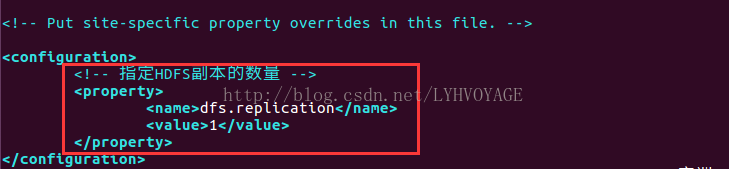
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置yarn-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
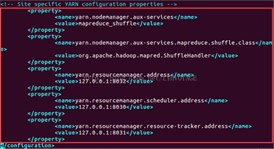
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>127.0.0.1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>127.0.0.1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>127.0.0.1:8031</value>
</property>
</configuration>
(4)关机重启系统。
四、测试Hadoop是否安装并配置成功。
(1)验证Hadoop单机模式安装完成
hadoop version
能够显示Hadoop的版本号即可说明单机模式已经配置完成。
(2)启动hdfs使用为分布模式。
格式化namenode
hdfs namenode -format
有 "……has been successfully formatted" 等字样出现即说明格式化成功。注意:每次格式化都会生成一个namenode对应的ID,多次格式化之后,如果不改变datanode对应的ID号,运行wordcount向input中上传文件时会失败。
启动hdfs
start-all.sh
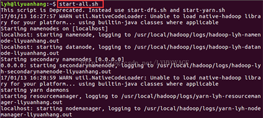
显示进程
jps

在浏览器中输入http://localhost:50070/,出现如下页面
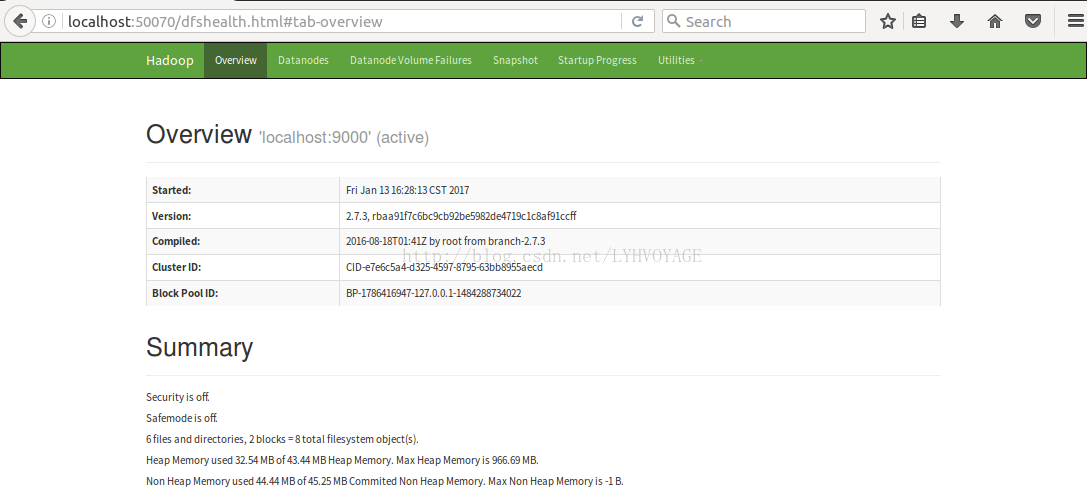
输入 http://localhost:8088/,出现如下页面
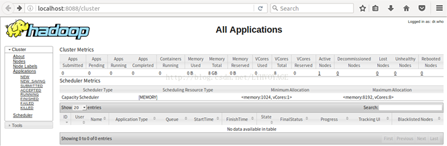
则说明伪分布安装配置成功了。
停止hdfs
stop-all.sh
五、运行wordcount
(1)启动hdfs。
start-all.sh
(2)查看hdfs底下包含的文件目录
hadoop dfs -ls /
如果是第一次运行hdfs,则什么都不会显示。

(3)在hdfs中创建一个文件目录input,将/usr/local/hadoop/README.txt上传至input中。
hdfs dfs -mkdir /input hadoop fs -put /usr/local/hadoop/README.txt /input


(4)执行以下命令运行wordcount,并将结果输出到output中。
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output

出现类似上图的页面说明wordcount运行成功。注意:请将图中红色线框中的内容替换为自己的hadoop-mapreduce-examples-2.7.3.jar文件的路径信息。
(5)执行成功后output 目录底下会生成两个文件 _SUCCESS 成功标志的文件,里面没有内容。 一个是 part-r-00000 ,通过以下命令查看执行的结果,如下图。
hadoop fs -cat /output/part-r-00000
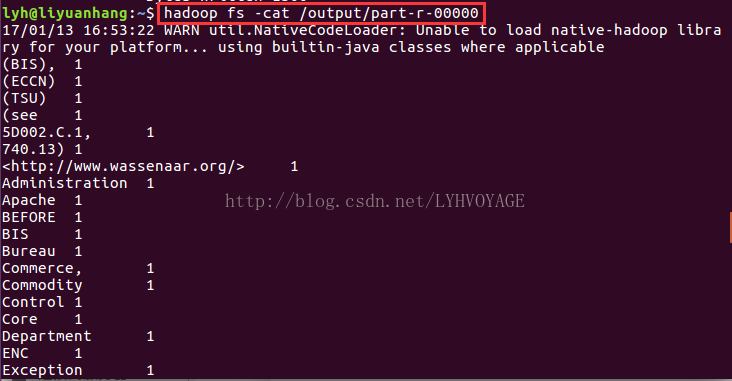
附:hdfs常用命令
hadoop fs -mkdir /tmp/input 在HDFS上新建文件夹 hadoop fs -put input1.txt /tmp/input 把本地文件input1.txt传到HDFS的/tmp/input目录下 hadoop fs -get input1.txt /tmp/input/input1.txt 把HDFS文件拉到本地 hadoop fs -ls /tmp/output 列出HDFS的某目录 hadoop fs -cat /tmp/ouput/output1.txt 查看HDFS上的文件 hadoop fs -rmr /home/less/hadoop/tmp/output 删除HDFS上的目录 hadoop dfsadmin -report 查看HDFS状态,比如有哪些datanode,每个datanode的情况 hadoop dfsadmin -safemode leave 离开安全模式 hadoop dfsadmin -safemode enter 进入安全模式
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了宝塔面板Linux版的命令大全,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了宝塔面板Linux版的命令大全,需要的朋友可以参考下2020-06-06 对象被创建后,使用完毕不是立即销毁回收对象,而是将对象放到一个容器保存起来,下次使用的时候不用创建对象,而是从容器中直接获取,这篇文章主要介绍了利用Apache Common将java对象“池化”,需要的朋友可以参考下2022-06-06
对象被创建后,使用完毕不是立即销毁回收对象,而是将对象放到一个容器保存起来,下次使用的时候不用创建对象,而是从容器中直接获取,这篇文章主要介绍了利用Apache Common将java对象“池化”,需要的朋友可以参考下2022-06-06 这篇文章主要介绍了怎样给centos系统扩展磁盘分区的实现方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-12-12
这篇文章主要介绍了怎样给centos系统扩展磁盘分区的实现方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-12-12 GDB是GNU开源组织发布的一个强大的UNIX下的程序调试工具。不管是调试Linux内核空间的驱动还是调试用户空间的应用程序,掌握gdb的用法都是必须。而且,调试内核和调试应用程序时使用的gdb命令是完全相同的2021-06-06
GDB是GNU开源组织发布的一个强大的UNIX下的程序调试工具。不管是调试Linux内核空间的驱动还是调试用户空间的应用程序,掌握gdb的用法都是必须。而且,调试内核和调试应用程序时使用的gdb命令是完全相同的2021-06-06
ubuntu 16.04 LTS 安装mongodb 3.2.8教程
本篇文章主要介绍了ubuntu 16.04 LTS 安装mongodb 3.2.8教程,具有一定的参考价值,有需要的可以了解一下。2017-04-04 这篇文章主要介绍了linux下常用的四种web数据同步方法,并且说明了每个方法的功能与优势,需要的朋友可以参考下2013-09-09
这篇文章主要介绍了linux下常用的四种web数据同步方法,并且说明了每个方法的功能与优势,需要的朋友可以参考下2013-09-09 Linux 系统提供了一个非常易于使用的命令来分割文件,要将文件分割为多个文件块,只需使用 split 命令。这篇文章主要介绍了使用 split 命令分割 Linux 文件,需要的朋友可以参考下2019-12-12
Linux 系统提供了一个非常易于使用的命令来分割文件,要将文件分割为多个文件块,只需使用 split 命令。这篇文章主要介绍了使用 split 命令分割 Linux 文件,需要的朋友可以参考下2019-12-12 现有Chinanet ip 126个,不可能分给所有的用户使用。通过架设代理服务器来实现让所有用户使用网络资源是最简单并且相对安全和可靠的方法。2011-06-06
现有Chinanet ip 126个,不可能分给所有的用户使用。通过架设代理服务器来实现让所有用户使用网络资源是最简单并且相对安全和可靠的方法。2011-06-06
Centos修改DNS重启或重启network服务后丢失问题解决方法
这篇文章主要介绍了Centos修改DNS重启或重启network服务后丢失问题解决方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-12-12
Linux使用watch命令监控Docker容器状态的操作方法
在现代的开发和运维环境中,容器化技术已经成为一种重要的趋势,而Docker作为最流行的容器化平台之一,Linux中的watch命令就是一个非常有用的工具,它可以帮助我们定期执行指定的命令,并全屏显示输出,本文给大家介绍了在Linux中使用watch命令监控Docker容器状态2024-10-10










最新评论