
Python中作用域的深入讲解
前言
作用域是指变量的生效范围,例如本地变量、全局变量描述的就是不同的生效范围。
python的变量作用域的规则非常简单,可以说是所有语言中最直观、最容易理解的作用域。
在开始介绍作用域之前,先抛一个问题:
x=1
def f():
x=3
g()
print("f:",x) # 3
def g():
print("g:",x) # 1
f()
print("main:",x) # 1
上面的代码将输出3、1、1。解释参见再述作用域规则。另外,个人建议,本文最后一小节内容尽量理解透彻。
python作用域规则简介
它有4个层次的作用域范围:内部嵌套函数、包含内部嵌套函数的函数自身、全局作用域、内置作用域。上面4个作用域的范围排序是按照从内到外,从小到大排序的。

其中:
- 内置作用域是预先定义好的,在
__builtins__模块中。这些名称主要是一些关键字,例如open、range、quit等 - 全局作用域是文件级别的,或者说是模块级别的,每个py文件中处于顶层的变量都是全局作用域范围内的变量
- 本地作用域是函数内部属于本函数的作用范围,因为函数可以嵌套函数,嵌套的内层函数有自身的内层范围
- 嵌套函数的本地作用域是属于内层函数的范围,不属于外层
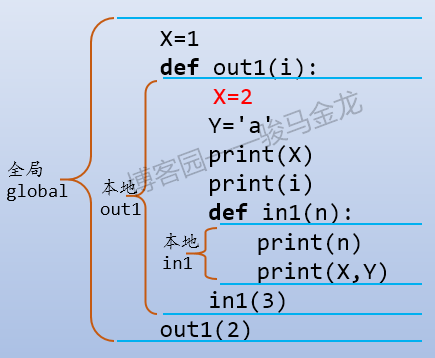
所以对于下面这段python代码来说,如果它处于a.py文件中,且没有嵌套在其它函数内:
X=1 def out1(i): X=2 Y='a' print(X) print(i) def in1(n): print(n) print(X,Y) in1(3) out1(2)
那么:
处于全局作用域范围的变量有:X、out1
处于out1本地作用域范围的变量有:i、X、Y、in1
处于嵌套在函数out1内部的函数in1的本地作用域范围的变量有:n
注意上面的函数名out1和in1也是一种变量。
如下图所示:
搜索规则
当在某个范围引用某个变量的时候,将从它所在的层次开始搜索变量是否存在,不存在则向外层继续搜索。搜索到了,则立即停止。
例如函数ab()中嵌套了一个函数cd(),cd()中有一个语句print(x),它将首先检查cd()函数的本地作用域内是否有x,如果没有则继续检查外部函数ab()的本地作用域范围内是否有x,如果没有则再次向外搜索全局范围内的变量x,如果还是没有,则继续搜索内置作用域,像"x"这种变量名,在内置作用域范围内是不存在的,所以最终没有搜索到,报错。如果一开始在cd()中就已经找到了变量x,就不会再搜索ab()范围以及更外层的范围。
所以,内层范围可以引用外层范围的变量,外层范围不包括内层范围的变量。
内置作用域
内置作用域主要是一些内置的函数名、内置的异常等关键字。例如open,range,quit等。
两种方式可以搜索内置作用域:一是直接导入builtins模块,二是让python自动搜索。导入builtins模块会让内置作用域内的变量直接置于当前文件的全局范围,自动搜索内置作用域则是最后的阶段进行搜索。
一般来说无需手动导入builtins模块,不过可以看看这个模块中包含了哪些内置变量。
>>> import builtins >>> dir(builtins) ['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', ............... 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
变量掩盖和修改规则
如果在函数内部引用了一个和全局变量同名的变量,且不是重新定义、重新赋值(其实python中没有变量声明的概念,只有赋值的概念),那么函数内部引用的是全局变量。
例如,下面的函数g()中,print函数中的变量x并未在g()中单独定义或赋值,所以这个x引用的是全局变量x,它将输出值3。
x=3 def g(): print(x) # 引用全局变量x
如果函数内部重新赋值了一个和全局变量名称相同的变量,则这个变量是本地变量,它会掩盖全局变量。注意是掩盖而非覆盖,掩盖的意思是出了函数的范围(函数退出),全局变量就会恢复。或者换句话说,在函数内部看到的是本地变量x=2,在函数外部看到的是全局变量x=3。
例如:下面的g()中重新声明了x,这个x称为g()的本地变量,全局变量x=3暂时被掩盖(当然,这是对该函数来说的掩盖)。
x=3 def g(): x=2 # 定义并赋值本地变量x print(x) # 引用本地变量x
python是一种解释性语言,读一行解释一行,读了下一行就忘记前一行(详细见下文)。所以在使用变量之前必须先进行变量的定义(声明)。
例如下面是错误的:
def g(): print(x) x=3 g()
错误信息:
UnboundLocalError: local variable 'x' referenced
before assignment
这个很好理解,但是下面和同名的全局变量混合的时候,就不那么容易理解了:
x=1 def g(): print(x) x=2 g()
这里也会报错,而不是输出x=1或2。
这里需要解释一下,虽说python是逐行解释的。但每个函数属于一个区块,这个区块范围是一次性解释的,并不会读一行忘记一行,而是一直读,读完整个区块再解释。所以,读完整个g()区块后,首先就记住了重新定义了本地变量x=2,于是g()中所有使用变量x的时候,都是本地变量x,所以print(x)中的x也是本地变量,但这违反了使用变量前先赋值的规则,所以也会报错。
因此,在函数内修改和全局变量同名的变量前,必须先修改,再使用该变量。所以,上面的代码中,x=2必须放在print的前面:
x=1 def g(): x=2 print(x) g()
所以,对于函数来说,也必须先定义函数,再调用函数。下面是错误的:
g() def g(): x=2 print(x)
报错信息:
NameError: name 'g' is not defined
但是下面的代码中,f()中先调用了g(),然后才定义g(),为什么能执行呢:
x=1
def f():
x=3
g()
print("f:",x) # 3
def g():
print("g:",x) # 1
f()
print("main:",x) # 1
实际上并非是先调用了g(),python解释到def f()区块的时候,只是声明这一个函数,并非调用这个函数,真正调用f()的时候是在def g()区块的后面,所以实际上是先声明完f()和g()之后,再调用f()和g()的。
但如果把f()放在def f()和def g()的中间,将会报错,因为调用f()函数的时候,def g()还没解释到,也就是说g()还没有声明。
x=1
def f():
x=3
g()
print("f:",x)
f() # 报错
def g():
print("g:",x)
更容易犯错的一种情况是边赋值,边使用。下面的代码是错误的:
x=3 def f1(): x += 3 print(x) f1()
因为x += 3也是赋值操作,函数内部只要是赋值操作就表示声明为本地变量。它首先计算x=x+3右边的x+3,然后将结果赋值给左边的变量x,但计算x+3的时候变量x并未定义,所以它是错误的。错误信息:
UnboundLocalError: local variable 'x' referenced before assignment
关于全局变量
关于python中的全局变量:
- 每个py文件(模块)都有一个自己的全局范围
- 文件内部顶层的,不在def区块内部的变量,都是全局变量
- def内部声明(赋值)的变量默认是本地变量,要想让其变成全局变量,需要使用global关键字声明
- def内部如果没有声明(赋值)某变量,则引用的这个变量是全局变量
默认情况下,下面f()中的x变量是全局变量:
x=2 def f(): print(x) f() # 输出2
默认情况下,下面f()中的x变量是本地变量:
x=2 def f(): x=3 print(x) f() # 输出3 print(x) # 输出2
global关键字
如果想要在def的内部修改全局变量,就需要使用global关键字声明变量:
x=2 def f(): global x x=3 print(x) f() # 输出3 print(x) # 输出3
global可以声明一个或多个变量为全局变量,多个变量使用逗号隔开,也可以声明事先不存在的变量为全局变量:
x=2 def f(): global x,y x,y = 3,4 print(x,y) f() print(x,y)
不能global中直接赋值。所以下面的是错的:
global x=2
注意,global不是声明变量,在变量赋值之前,变量是一定不存在的,就算是被global修饰了也一样不存在,所以下面的代码是错的。实际上,global有点类似于声明变量的名称空间,而非变量。
x=2 def f(): global x,y print(y)
报错信息:
NameError: name 'y' is not defined
必须在print(y)之前(不能是之后)加上y的赋值语句,才表示它的存在。
x=2 def f(): global x,y y=3 print(y)
global修饰的变量必须在它的赋值之前,所以下面的是错的,因为y=2首先将它声明为本地变量了。
def f(): y=2 global y
全局变量的不安全性
考虑下面这个问题:
x=2 def f(): global x x=3 def g(): global x x=4 f()或g() print(x)
这时,函数f()和g()的调用顺序决定了print输出的全局变量x的值。因为全局变量是共享的,如果多线程同时执行这段代码,就不知道是谁先谁后修改,导致print(x)的值随机性。这是多线程不安全特性。因此,如果允许,应尽量不要将函数内部的变量修饰为全局变量。
访问其它模块中的全局变量
python中一个文件一个模块,在模块1中可以导入模块2中的属性(例如全局变量)。
例如,b.py文件中:
x=3
a.py文件中:
import b print(b.x) b.x=4
上面的a.py中导入了b.py模块,通过b.x可以访问、修改这个来自于b.py中的全局变量x。
这是极不安全的,因为谁也不知道是否有其他的模块也在修改b.x。
所以,没有人会去直接修改其它模块的属性,如果要修改,基本上都会通过类似面向对象中的setter函数进行修改。只需在b.py中定义一个函数,以后在其它文件中使用这个函数修改即可。
b.py文件中:
x=3 def setx(n) global x x=n
a.py文件中:
import b b.setx(54) # 将b.x变量设置为54
其它访问全局变量的方法
上面通过import导入模块文件,就可以获取这个模块中属性的访问权。实际上,也可以在当前模块文件中使用import mod_name导入当前模块,其中mod_name为当前文件名,这样就可以在函数内部直接访问全局变量,而无需使用global关键字。
除了import mod_name可以导入当前模块,使用sys模块的modules()函数也可以导入:sys.modules['mod_name'] 。
例如,在b.py文件中:
x=3
def f():
global x
x += 2
def f1():
x=4 # 本地变量
def f2():
x=4 # 本地变量
import b
b.x += 2 # 全局变量
def f3():
x=4 # 本地变量
import sys
glob = sys.modules['b']
glob.x += 2 # 全局变量
def test():
print("aaa",x) # 输出3
f();f1();f2();f3()
print("bbb",x) # 输出9
在a.py文件中:
import b b.test()
nonlocal关键字
当函数进行嵌套的时候,内层函数的作用域是最内层的,它的外层是外层函数的作用域。内层函数和外层函数的关系类似于本地作用域与全局作用域的关系:
(1).内层函数中赋值的变量是属于内层、不属于外层的本地变量
(2).内层函数中使用的未在当前内层函数中赋值的变量是属于外层、全局的变量
例如,下面的嵌套代码中,f2()中print(x,y)的x是属于外层函数f1()的本地变量,而y则是属于内层函数自身的本地变量,外层函数f1()无法访问属于内层函数的y。
x=3 def f1(): x=4 def f2(): y=5 print(x,y) f2() f1()
nonlocal语句可以修饰内层函数中的变量使其成为它上一层函数的变量。它的用法和global基本相同,修饰多个变量的时候,需要逗号隔开。但和global有一点不同,global修饰的变量可能事先并未存在于全局作用域内,但nonlocal修饰的变量必须已经存在于上层或上上层(或更多层)函数,不能只存在于全局(见下面示例)。
例如下面的代码片段中嵌套了2次,其中f3()中的x使用nonlocal修饰,使得这个x变成它上一层作用域f2()中的x变量。
x=3
def f1():
x=4 # f1的本地变量
def f2():
x=5 # f2的本地变量
def f3():
nonlocal x # f2的本地变量
print("f3:",x) # 输出5
x=6
f3()
print("f2:",x) # 被修改,输出6
f2()
f1()
上面的代码将输出:
f3: 5
f2: 6
如果将上面的f2()中的x=5删除,会如何?
x=3
def f1():
x=4
def f2():
def f3():
nonlocal x # f1()的本地
print("f3:",x) # 输出4
x=6 # 修改f1()的本地
f3()
print("f2:",x) # 输出6
f2()
print("f1:",x) # 输出6
f1()
注意,上面f3()中的nonlocal将x修饰为f1()的本地变量,因为f3()的上一层f2()中没有变量x,所以f2()继承了f1()的变量x,使得f3()修改上一层f2()中的变量,等价于修改f1()中的变量x。
但如果把f1()中的x=4也删除,那么将报错,因为nonlocal无法将变量修饰为全局范围。
所以,nonlocal默认将内层函数中的变量修饰为上一层函数的作用域范围,如果上一层函数中不存在该变量,则修饰为上上层、上上上层直到顶层函数,但不能修饰为全局作用域范围。
同样的,只要在内层函数中赋值,就表示声明这个变量的作用域为内层函数作用域范围。所以,下面的代码是错误的:
x=3 def f1(): x=4 def f2(): print(x) x=3 f2() f1()
下面的代码也是错的:
x=3 def f1(): x=4 def f2(): x += 3 print(x) f2() f1()
错误信息:
UnboundLocalError: local variable 'x' referenced before assignment
至于原因,前文已经解释的很清楚。
访问外层函数变量的其它方法
在以前的版本中,还没有nonlocal关键字,这时如果要保存外层函数的变量,就需要使用函数参数默认值的方式定义内层函数。
x=3
def f1():
x=4
def f2(x=x):
x += 3
print("f2:",x)
x=5
f2()
print("f1:",x)
f1()
输出:
f2: 7
f1: 5
上面的f2(x=x)中,等号右边的x来自于f1()中x=4,然后将其赋值给f2()的本地作用域变量x。注意,python的作用域是词法作用域,函数区块的定义位置决定了它看到的变量。所以,尽管调用f2()之前再次对x进行了赋值,f2()函数调用时,f2(x=x)等号右边的x早已经赋值给左边的本地变量x了。它们的关系如下图所示:

避免函数嵌套
一般来说,函数嵌套都只用于闭包(工厂函数),而且是结合匿名函数(lambda)实现的闭包。其它时候,函数嵌套一般都可以改写为非嵌套模式。
例如,下面的嵌套函数:
def f1(): x=3 def f2(): nonlocal x print(x) f2() f1()
可以改写为:
def f1(): x=3 f2(x) def f2(x): print(x) f1()
当函数位于循环结构中,且这个函数引用了循环控制变量,那么结果可能会出乎意料。
本来以匿名函数(lambda)来解释更清晰,但因为尚未介绍匿名函数,所以这里采用命名函数为例。
下面的代码中,将5个函数作为列表的元素保存到列表list1中。
def f1(): list1 = [] for i in range(5): def n(x): return i+x list1.append(n) return list1 mylist = f1() for i in mylist: print(i) print(mylist[0](2)) print(mylist[2](2))
结果:
<function f1.<locals>.n at 0x02F93660>
<function f1.<locals>.n at 0x02F934B0>
<function f1.<locals>.n at 0x02F936A8>
<function f1.<locals>.n at 0x02F93738>
<function f1.<locals>.n at 0x02F93780>
6
6
从结果中可以看到mylist[0](2)和mylist[2](2)的执行结果是一样的,不仅如此,mylist[N](2)的结果也全都一样。换句话说,保存到列表中的各个函数n()中所引用的循环控制变量"i"并没有因为循环的迭代而改变,而且列表中所有函数保存的i的值都是循环的最后一个元素i=4。
(注:对于此现象,各语言基本都是如此,本节稍作解释,真正的本质原因在本文的最后一节做了额外的补充解释代码块细述)。
先看下面的例子:
def f1(): for i in range(5): def n(): print(i) return n f1()()
结果输出4。可见,print(i)的值并没有随循环的迭代过程而改变。
究其原因,是因为def n()只是函数的声明,它不会去查找i的值是多少,所以不会将i的值替换到函数n()的i变量,而是直接保存变量i的地址,当循环结束时,i指向最后一个元素i=4的地址。
当开始调用n()的时候,即f1()(),才会真正开始查找i的值,这时候i指向的正是i=4。
这就像下面的代码一样,在还没有开始调用f()的时候,f()内部的x一直都只是指向它所看见的变量x,而这个x是全局作用域范围。当真正开始调用f()的时候,才会去定位x的指向。
x=3 def f(): print(x)
回到上面循环中的嵌套函数,如果要保证循环的迭代能作用到其内部的函数中,可以采用默认参数值的方式进行赋值:
def f1(): list1 = [] for i in range(5): def n(x,i=i): return i+x list1.append(n) return list1
上面def n(x,i=i)中的i=i是设置默认参数值,等号右边的i是函数声明时就查找并替换完成的,所以每次循环迭代过程中,等号右边的i都不同,等号左边的参数i的默认值就不同。
python的作用域是词法作用域,这意味着函数的定义位置决定了它所看见的变量。除了词法作用域,还有动态作用域,动态作用域意味着函数的调用位置决定了它所看见的变量。关于词法、动态作用域,本文不多做解释,想要了解的话,可以参考一文搞懂:词法作用域、动态作用域、回调函数、闭包
下面是本文开头的问题:
x=1
def f():
x=3
g()
print("f:",x) # 3
def g():
print("g:",x) # 1
f()
print("main:",x) # 1
对于python的这段代码来说,这里有两个值得注意的地方:
- 调用函数之前,理论上要先定义好函数,但这里g()的调用似乎看上去比g()的定义更先
- f()中调用g()时,为什么g()输出的是1而不是3
第一个问题在前文已经解释过了,再解释一遍:虽然f()里面有g()的调用语句,但def f()只是声明,但在调用f()之前,是不会去调用g()的。所以,只要f()的调用语句在def g()之后,就是正确的。
第二个问题,python是词法作用域,所以:
(1).首先声明def f(),在此期间会创建一个本地变量x,并且print("f:",x)中的x指向这个本地变量;
(2).然后声明g(),在此期间,g()的定义语句不在f()内部,而是在全局范围,所以它看见的是x是全局x,所以print("g:",x)中的x指向全局变量x;
当调用f()的时候,执行到g()时,g()中所指向的是全局范围的x,而非f()段中的x。所以,输出1。
再看一个嵌套在函数内部的示例:
x=3 def f1(): x=4 def f2(): print(x) x=5 f2() f1() # 输出5
这里的问题是f2()中的print为什么不输出4,而是输出5。
其实也很容易理解,因为def f2()是定义在f1()内部的,所以f2()看见的x是f1()中的x,也就是说print(x)中的x指向的是f1()中的x。但在调用f2()之前,重新赋值了x=5,等到调用f2()的时候,根据x的指向,将找到新的x的值。
也就是说,前面的示例中,有两个独立的变量x:全局的和f()本地的。后面这个示例中只有一个变量x,属于f()。
代码块可以使得一段python代码作为一个单元、一个整体执行。以下是 官方手册 的描述。
A Python program is constructed from code blocks. A block is a piece of Python program text that is executed as a unit. The following are blocks: a module, a function body, and a class definition. Each command typed interactively is a block. A script file (a file given as standard input to the interpreter or specified as a command line argument to the interpreter) is a code block. A script command (a command specified on the interpreter command line with the ‘-c' option) is a code block. The string argument passed to the built-in functions eval() and exec() is a code block.
所以,有以下几种类型的代码块:
- 模块文件是一个代码块
- 函数体是一个代码块
- class的定义是一个代码块
- 交互式(python idle)的每一个命令行都是一个独立的代码块
- 脚本文件是一个代码块
- 脚本命令是一个代码块(python -c "xxx")
- eval()和exec()中的内容也都有各自的代码块
代码块的作用是组织代码,同时意味着退出代码区块范围就退出了作用域范围。例如退出函数区块,就退出了函数的作用域,使得函数内的本地变量无法被函数的外界访问。
此外,python是解释性语言,读一行解释一行,这意味着每读一行就忘记前一行。但实际上更严格的说法是读一个代码块解释一个代码块,这意味着读代码块中的内容时,是暂时记住属于这个代码块中所读内容的,读完整个代码块后再以统筹的形式解释这个代码块。
先说明读一行解释一行的情况,也就是每一行都属于一个代码块,这个只能通过python的交互式工具idle工具来测试:
>>> x=2000 >>> y=2000 >>> x is y False >>> x=2000;y=2000 >>> x is y True
理论上分号是语句的分隔符,并不会影响结果。但为什么第一个x is y为False,而第二个x is y为True?
首先分析第一个x is y。由于交互式工具idle中每一个命令都是一个单独的语句块,这使得解释完x=2000后立刻就忘记了2000这个数值对象,同时忘记的还有x变量本身。然后再读取解释y=2000,因为不记得刚才解释的x=2000,所以会在内存中重新创建一个数值结构用来保存2000这个数值,然后用y指向它。换句话说,x和y所指向的2000在内存中是不同的数据对象,所以x is y为False。
下面的x is y返回True:
>>> x=2000;y=2000 >>> x is y True
因为python按行解释,一个命令是一个代码块。对于x=2000;y=2000,python首先读取这一整行,发现x和y的数值对象都是2000,于是做个简单优化,等价于x,y=2000,2000,这意味着它们属于一个代码块内,由于都是2000,所以只会在内存中创建一个数据对象,然后x和y都引用这个数据对象。所以,x is y返回True。
idle工具中每个命令都是独立的代码块,但是py文件却是一个完整的代码块,其内还可以嵌套其它代码块(如函数、exec()等)。所以,如果上面的分行赋值语句放在py文件中,得到的结果将是True。
例如:
x = 2000 y = 2000 print(x is y) # True def f1(): z=2000 z1=2000 print(x is z) # False print(z is z1) # True f1()
python先读取x=2000,并在内存中创建一个属于全局作用域的2000数据对象,再解释y=2000的时候,发现这个全局对象2000已经存在了(因为x和y同处于全局代码块内),所以不会再额外创建新的2000对象。这里反映出来的结果是"同一个代码块内,虽然仍然是读一行解释一行,但在退出这个代码块之前,不会忘记这个代码块中的内容,而且会统筹安排这个代码块"。
同理def f1()内的代码块,因为z是本地作用域的变量,更标准的是处于不同代码块内,所以会在本地作用域内存区创建新的数据对象2000,所以x is z返回False。根据前面的解释,z1 is z返回True。
再回顾前文多次出现的一个异常:
x = 3 def f1(): print(x) x=4 f1()
报错信息:
UnboundLocalError: local variable 'x' referenced before assignment
当执行到def语句的时候,因为def声明函数,函数体是一个代码块,所以按照代码块的方式读取属于这个代码块中的内容。首先读取print(x),但并不会直接解释,而是会记住它,并继续向下读取,于是读取x=4,这意味着x是一个本地变量。然后统筹安排整个代码块,将print(x)的x认为是本地变量而非全局变量。注意,直到def退出的时候都还没有进行x的赋值,而是记录了本地变量x,赋值操作是在函数调用的时候进行的。当调用函数f()的时候,发现print(x)中的x是本地变量,但因为还没有赋值,所以报错。
但是再看下面的,为什么又返回True?
>>> x=256 >>> y=256 >>> x is y True
因为Python在启动的时候就在内存中预先为常用的较小整数值(-5到256)创建好了对象,因为它们使用的非常频繁(有些在python的内部已经使用了)。所以,对于这个范围内的整数,都是直接引用,不会再在内存中额外创建新的数值对象,所以x is y总是返回true。甚至,这些小值整数可以跨作用域:
x = 3 def f1(): y=3 print(x is y) # True f1()
再看前文循环内的函数的问题。
def f1(): for i in range(5): def n(): print(i) return n f1()()
前面对现象已经解释过,内部函数n()中print(i)的i不会随循环的迭代而改变,而是固定的值i=4。
python首先解释def f1()的代码块,会记录属于这个代码块作用域内的变量i和n,但i和n都不会赋值,也就是说暂时并不知道变量n是一个函数变量。
同理,当需要解释def n()代码块的时候,将记住这个代码块涉及到的变量i,只不过这个变量i是属于外层函数的,但不管如何,这个代码块记住了i,且记住了它是外部函数作用域的。
注意,函数的声明过程中,所有涉及到变量i的作用域内都不会对i进行赋值,仅仅只是保存了这个i变量名,只有在调用函数的时候才会进行赋值操作。
当开始调用f1()的时候,开始执行函数体中的代码,于是开始循环迭代,且多次声明函数n(),每一次迭代生成的n()都会让原先已记录的变量n指向这个新声明的函数体(相当于赋值的操作,只不过是变量n引用的对象是函数体结构,而不是一般的数据对象),由于只是在循环中声明函数n(),并没有进行调用,所以不会对n()中的i进行赋值操作。而且,每次循环迭代都会让变量n指向新的函数体,使得先前迭代过程中定义的函数被丢弃(覆盖),所以最终只记住了最后一轮循环时声明的函数n(),并且i=4。
当调用f1()()时,表示调用f1()中返回的函数n(),直到这个时候才会对n()内的i进行赋值,赋值时将搜索它的外层函数f1()作用域,发现这个作用域内的i指向内存中的数值4,于是最终输出4。
再看下面的代码:
def f1(): for i in range(5): def n(): print(i) n() return n f1()
输出结果:
0
1
2
3
4
调用f1()的时候,执行循环的迭代,每次迭代时都会调用n(),意味着每次迭代都要对n()中的i进行赋值。
另外注意,前面说过,函数的默认参数是在函数声明时进行赋值的,所以下面的列表L中每个元素所代表的函数,它们的变量i都指向不同的数值对象。
def f1(): L = [] for i in range(5): def n(i=i): print(i) L.append(n) return L f1()[0]() f1()[1]() f1()[2]() f1()[3]() f1()[4]()
执行结果:
0
1
2
3
4
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
相关文章

Django Docker容器化部署之Django-Docker本地部署
这篇文章主要介绍了Django Docker容器化部署之Django-Docker本地部署,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-10-10 很多软件在运行时会自动创建一些备份文件,在程序退出后又不自动删除备份文件,随着文件数量的增加,每隔一段时间就要清理一下。2011-03-03
很多软件在运行时会自动创建一些备份文件,在程序退出后又不自动删除备份文件,随着文件数量的增加,每隔一段时间就要清理一下。2011-03-03 偏函数(Partial function)是Python的functools模块提供的一个很有用的功能,它允许我们通过固定部分参数或关键字参数来创建一个新的函数,这篇文章主要给大家介绍了关于Python偏函数介绍及用法举例详解的相关资料,需要的朋友可以参考下2024-04-04
偏函数(Partial function)是Python的functools模块提供的一个很有用的功能,它允许我们通过固定部分参数或关键字参数来创建一个新的函数,这篇文章主要给大家介绍了关于Python偏函数介绍及用法举例详解的相关资料,需要的朋友可以参考下2024-04-04
对python中数据集划分函数StratifiedShuffleSplit的使用详解
今天小编就为大家分享一篇对python中数据集划分函数StratifiedShuffleSplit的使用详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12 这篇文章主要介绍了python实现对excel中需要的数据的单元格填充颜色,文章围绕主题展开详细单元格填充介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-06-06
这篇文章主要介绍了python实现对excel中需要的数据的单元格填充颜色,文章围绕主题展开详细单元格填充介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-06-06
python GUI库图形界面开发之PyQt5信号与槽机制、自定义信号基础介绍
这篇文章主要介绍了python GUI库图形界面开发之PyQt5信号与槽机制基础介绍,需要的朋友可以参考下2020-02-02 这篇文章主要介绍了matlab输出数据为excel文件的问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08
这篇文章主要介绍了matlab输出数据为excel文件的问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08 这篇文章主要介绍了Python 远程开关机的方法,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-11-11
这篇文章主要介绍了Python 远程开关机的方法,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-11-11 这篇文章主要介绍了Python opencv医学处理的实现过程,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-05-05
这篇文章主要介绍了Python opencv医学处理的实现过程,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-05-05 这篇文章主要介绍了Pandas0.25来了千万别错过这10大好用的新功能,都有哪些新功能,文中给大家详细介绍,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了Pandas0.25来了千万别错过这10大好用的新功能,都有哪些新功能,文中给大家详细介绍,需要的朋友可以参考下2019-08-08










最新评论