
Windows下Node爬虫神器Puppeteer安装记
对于爬虫,相信大家并不陌生。当希望得到一些网站的数据并做一些有趣的事时,必不可少要爬取网页,用到爬虫。而目前网络上也有很多爬虫的教程资料,不过又尤以python语言居多。想来自己是做web的,就希望以js的方式解决问题,于是希望利用nodejs。今天介绍一款node的爬虫利器:Puppeteer。
Puppeteer正如其名“木偶”,它允许我们像牵线木偶一样操纵它。它是一个建立在DevTools协议上的提供控制无头Chrome或Chromium的高级接口的Node库。官网上对其应用举了几个例子:
- - 生成网页的截屏(目前仅支持支持jpeg、png格式)和pdf文件
- - 爬取SPA和异步渲染网页
- - 自动表单提交、键盘输入、UI测试等
- - 创建最新的自动测试环境,也就是说可以使用最新的浏览器特性
- - 捕获站点的时间线以帮助分析性能问题
Puppeteer本质上是一个headless chrome。无头浏览器,相信如果大家做爬虫肯定有所耳闻。其实就是一个没有UI界面的浏览器,它包含了浏览器应该具有的功能,通常做web测试用,不过做爬虫也是没问题的。PhantomJS就提供这样的功能,基于webkit内核,已经有好几年历史了。不过因为Puppeteer有背景(谷歌Chrome团队开发),我最后还是选择了Puppeteer。它们之间的不同点是后者只关注于Chromium或Chrome。这也导致了最坑的一点是总是绑定最新版本的Chromium。
上面说到Puppeteer会绑定最新版本的Chromium,这意味着每次使用npm i puppeteer安装使用它时都会下载最新版本的Chromium,该版本在Windows上大约是130Mb。本来下载npm包就很不易,还要下载一个一百多兆的东西更是难上加难了。当然可以使用cnpm,下图是我下载的一个界面。可以看到下载了55分钟,这固然有我网络慢的问题,但是能不下载Chromium就尽量不下载了吧。
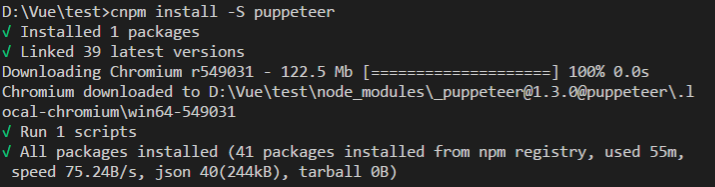
官网讲到可以通过设置环境变量或配置npm config的方式避免下载。但设置环境变量我一直没有成功,所以接下来讲解配置npm config的方式。PUPPETEER_SKIP_CHROMIUM_DOWNLOAD参数可以避免下载,所以可以在安装puppeteer之前使用下面的命令:
npm config set puppeteer_skip_chromium_download = 1
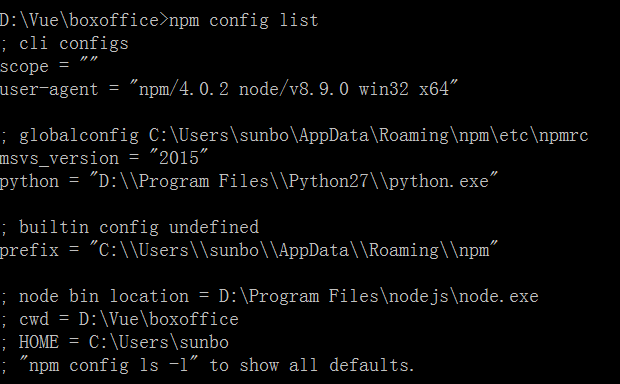
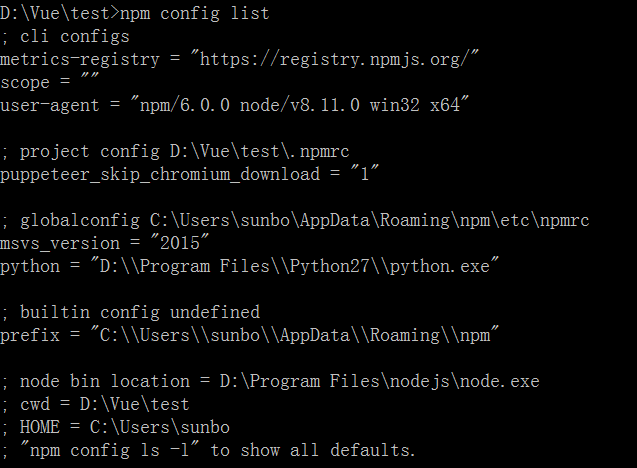
但这样每次都要敲这个命令总不是办法,所以可以将其写入.npmrc文件中。npm官网讲到有四个影响npm配置的文件,分别是:项目配置文件(/path/to/my/project/.npmrc)、用户配置文件 (~/.npmrc)、全局配置文件($PREFIX/etc/npmrc)、npm内置配置文件(/path/to/npm/npmrc)。可以使用npm config list来查看影响npm的配置文件有哪些。不过这里面有个问题,就是上面的介绍文档是针对npm最新的6.0版本的。而一般随nodejs下载的npm版本没有这么高,只是npm4.x,导致项目中的配置文件不生效。可以从下面两张图片看到两种版本的npm的配置文件的不同(上面一张:npm4.0.2,下面一张npm6.0),可以看到后者多出一个project config列表。
身为强迫症的我,当然希望直接在项目目录中更改配置文件了,所以使用下面的命令安装最新版本的npm:
npm install npm@latest -g
然后在项目目录下建立.npmrc文件,输入以下配置命令:
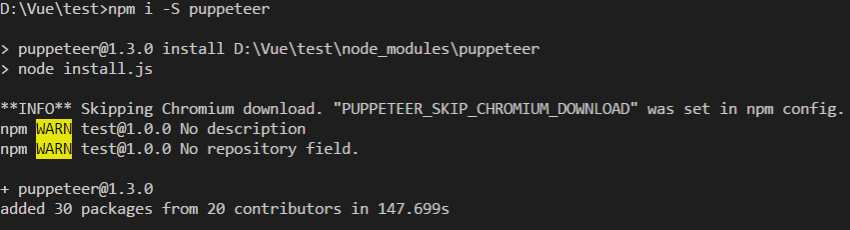
puppeteer_skip_chromium_download = 1
这样配置之后,就可以跳过下载了,如图所示:
接着就可以使用它了,以官网的例子为例:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
以为这样就完了吗?不,虽然跳过下载的事情解决了,但是因为没有下载会导致puppeteer无法得知要使用的Chrome或Chromium在哪里,所以还需要指明启动路径。修改一下:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
// headless: false,//不使用无头chrome模式
executablePath: 'C:\\Users\\sunbo\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe',//path to your chrome
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
更改executablePath参数指向你本地chrome所在目录,注意一定要指向chrome.exe才能正常使用。headless参数也是挺有趣的,如果其值为false,就会真的为我们启动一个chrome进程,让我们可以可视化整个程序运行的过程。
好了,安装配置好就可以尽情享受Puppeteer带给我们的美好世界了。最后说一点,官网例子使用async/await和promise,所以有必要了解这些异步知识,这些东西运用好,简直打开了异步编程的新世界。祝好运!!!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 通过npm package manager来安装和管理包是我们最为常见的方式之一,本文将从浅入深地带大家剖析一下npm install的执行过程,感兴趣的可以学习一下2023-05-05
通过npm package manager来安装和管理包是我们最为常见的方式之一,本文将从浅入深地带大家剖析一下npm install的执行过程,感兴趣的可以学习一下2023-05-05 这篇文章主要介绍了简单了解node npm cnpm的具体使用方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-02-02
这篇文章主要介绍了简单了解node npm cnpm的具体使用方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-02-02 在平时的使用中常会遇到这样的场景,手上有多个前端项目,每个项目使用的Nodejs的版本都不太一致,下面这篇文章主要给大家介绍了关于安装多版本node的完整步骤,需要的朋友可以参考下2024-01-01
在平时的使用中常会遇到这样的场景,手上有多个前端项目,每个项目使用的Nodejs的版本都不太一致,下面这篇文章主要给大家介绍了关于安装多版本node的完整步骤,需要的朋友可以参考下2024-01-01 在开发中经常需要获取form表单的数据,这篇文章主要给大家介绍了关于nodejs获取表单数据的三种方法,方法分别是form表单传递、ajax请求传递以及表单序列化,需要的朋友可以参考下2021-06-06
在开发中经常需要获取form表单的数据,这篇文章主要给大家介绍了关于nodejs获取表单数据的三种方法,方法分别是form表单传递、ajax请求传递以及表单序列化,需要的朋友可以参考下2021-06-06 这篇文章主要介绍了初学者如何快速搭建Express开发系统,结合实例形式详细分析了express框架搭建的具体步骤与相关注意事项,需要的朋友可以参考下2023-05-05
这篇文章主要介绍了初学者如何快速搭建Express开发系统,结合实例形式详细分析了express框架搭建的具体步骤与相关注意事项,需要的朋友可以参考下2023-05-05 这篇文章主要为大家详细介绍了node.js实现学生档案管理,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-05-05
这篇文章主要为大家详细介绍了node.js实现学生档案管理,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-05-05 这篇文章主要为大家详细介绍了NodeJs使用webpack打包项目的方法,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2022-02-02
这篇文章主要为大家详细介绍了NodeJs使用webpack打包项目的方法,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2022-02-02 EventEmitter 是 Node.js 中的一个核心模块,它提供了一种实现事件驱动编程的机制,它是一个基于观察者模式的类,用于在应用程序中处理事件和触发事件,这篇文章主要介绍了Node.js中的EventEmitter类介绍,需要的朋友可以参考下2023-12-12
EventEmitter 是 Node.js 中的一个核心模块,它提供了一种实现事件驱动编程的机制,它是一个基于观察者模式的类,用于在应用程序中处理事件和触发事件,这篇文章主要介绍了Node.js中的EventEmitter类介绍,需要的朋友可以参考下2023-12-12
nodejs的http和https下载远程资源post数据实例
这篇文章主要为大家介绍了nodejs的http和https下载远程资源post数据实例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-09-09 本文将以一个超小型web项目,来详细介绍如何使用NodeJS基础的http, fs, path, url等模块提供的API来搭建一个简单的web服务器。具有很好的参考价值。下面跟着小编一起来看下吧2017-04-04
本文将以一个超小型web项目,来详细介绍如何使用NodeJS基础的http, fs, path, url等模块提供的API来搭建一个简单的web服务器。具有很好的参考价值。下面跟着小编一起来看下吧2017-04-04










最新评论