
详解Python3网络爬虫(二):利用urllib.urlopen向有道翻译发送数据获得翻译结果
上一篇内容,已经学会了使用简单的语句对网页进行抓取。接下来,详细看下urlopen的两个重要参数url和data,学习如何发送数据data
一、urlopen的url参数 Agent

url不仅可以是一个字符串,例如:http://www.baidu.com。url也可以是一个Request对象,这就需要我们先定义一个Request对象,然后将这个Request对象作为urlopen的参数使用,方法如下:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
html = response.read()
html = html.decode("utf-8")
print(html)
同样,运行这段代码同样可以得到网页信息。可以看一下这段代码和上个笔记中代码的不同,对比一下就明白了。
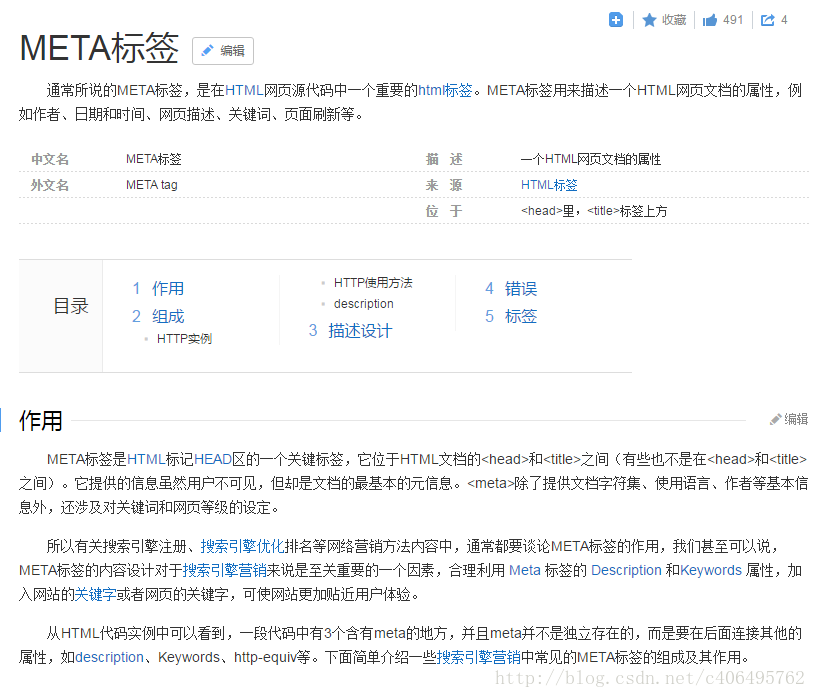
urlopen()返回的对象,可以使用read()进行读取,同样也可以使用geturl()方法、info()方法、getcode()方法。

geturl()返回的是一个url的字符串;
info()返回的是一些meta标记的元信息,包括一些服务器的信息;
getcode()返回的是HTTP的状态码,如果返回200表示请求成功。
关于META标签和HTTP状态码的内容可以自行百度百科,里面有很详细的介绍。

了解到这些,我们就可以进行新一轮的测试,新建文件名urllib_test04.py,编写如下代码:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
print("geturl打印信息:%s"%(response.geturl()))
print('**********************************************')
print("info打印信息:%s"%(response.info()))
print('**********************************************')
print("getcode打印信息:%s"%(response.getcode()))
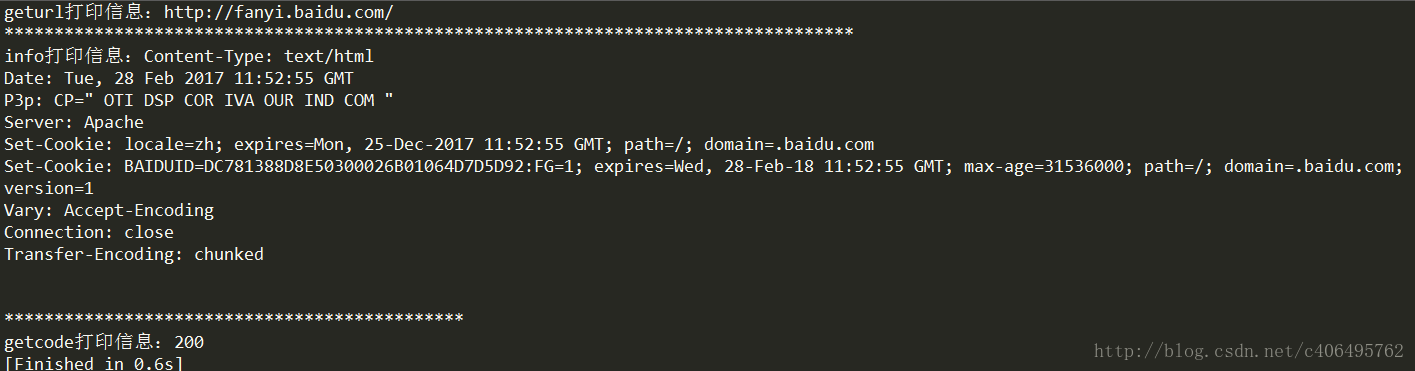
可以得到如下运行结果:
二、urlopen的data参数
我们可以使用data参数,向服务器发送数据。根据HTTP规范,GET用于信息获取,POST是向服务器提交数据的一种请求,再换句话说:
从客户端向服务器提交数据使用POST;
从服务器获得数据到客户端使用GET(GET也可以提交,暂不考虑)。
如果没有设置urlopen()函数的data参数,HTTP请求采用GET方式,也就是我们从服务器获取信息,如果我们设置data参数,HTTP请求采用POST方式,也就是我们向服务器传递数据。
data参数有自己的格式,它是一个基于application/x-www.form-urlencoded的格式,具体格式我们不用了解, 因为我们可以使用urllib.parse.urlencode()函数将字符串自动转换成上面所说的格式。
三、发送data实例
向有道翻译发送data,得到翻译结果。
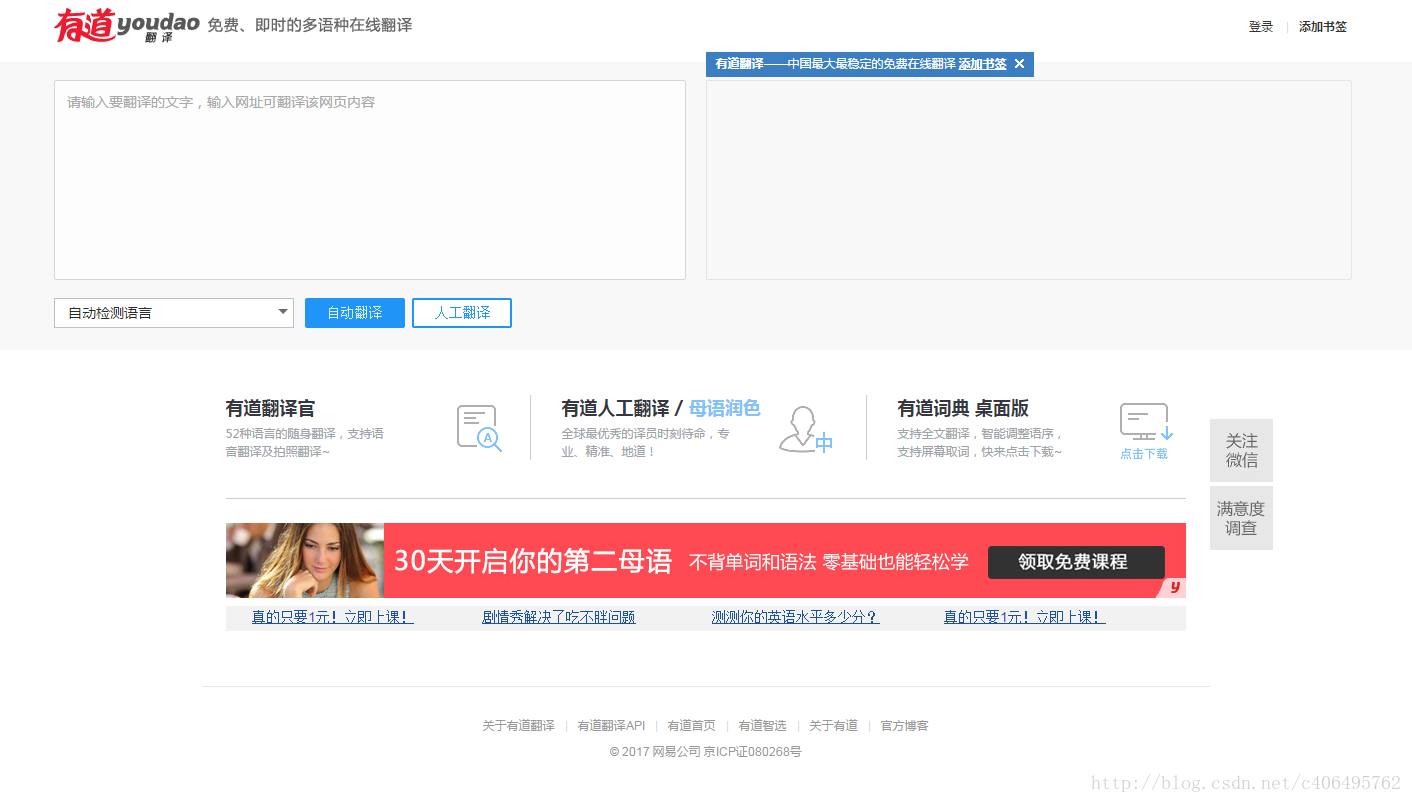
1.打开有道翻译界面,如下图所示:
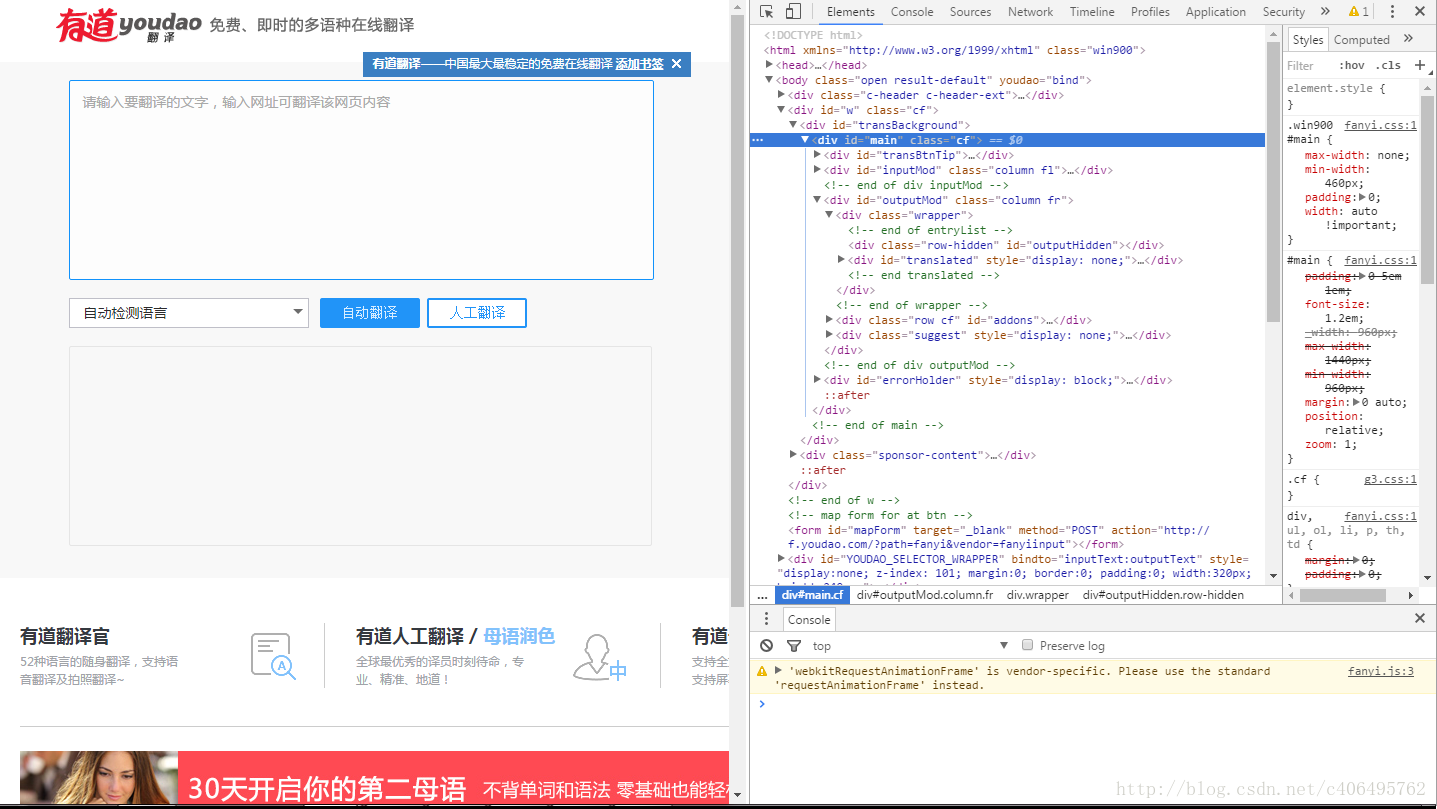
2.鼠标右键检查,也就是审查元素,如下图所示:
3.选择右侧出现的Network,如下图所示:
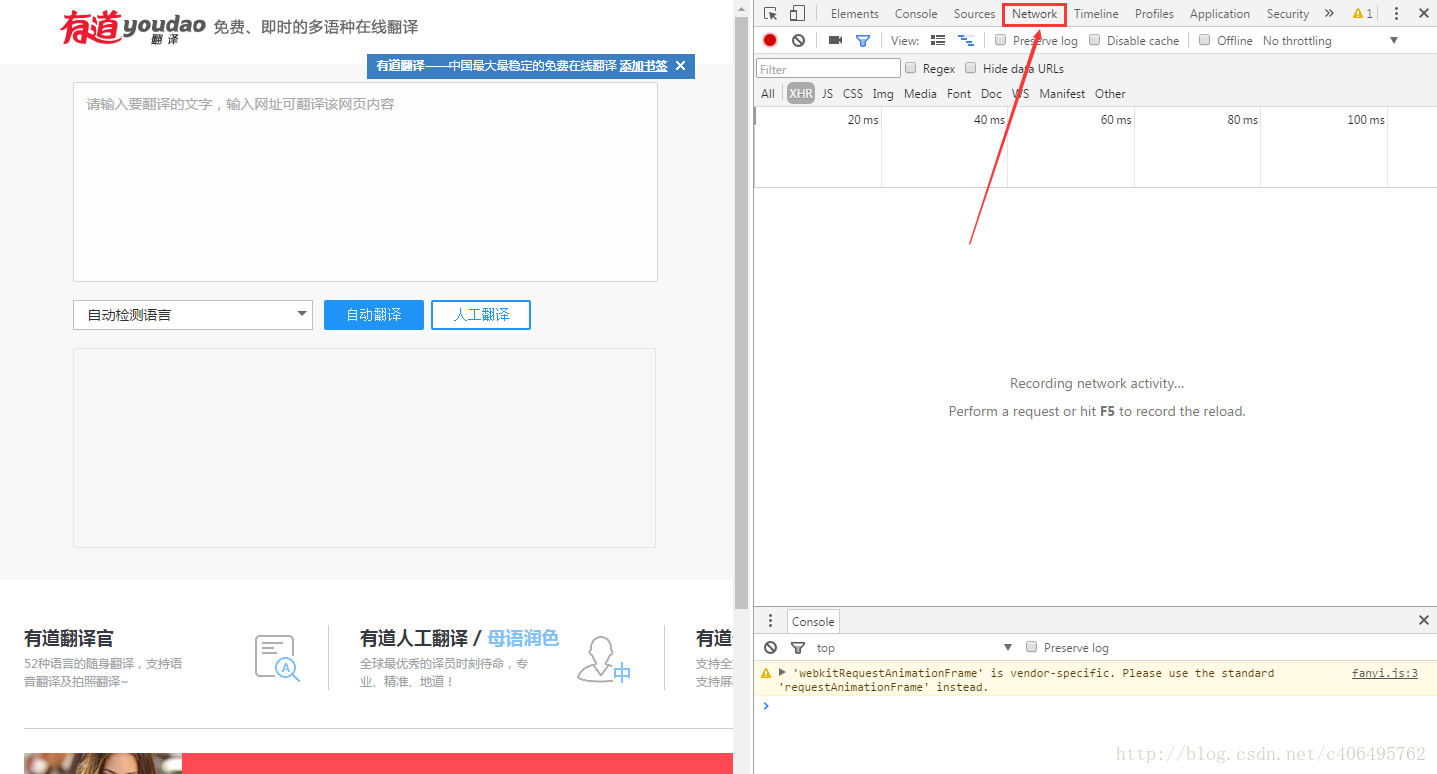
4.在左侧输入翻译内容,输入Jack,如下图所示:

5.点击自动翻译按钮,我们就可以看到右侧出现的内容,如下图所示:

6.点击上图红框中的内容,查看它的信息,如下图所示:

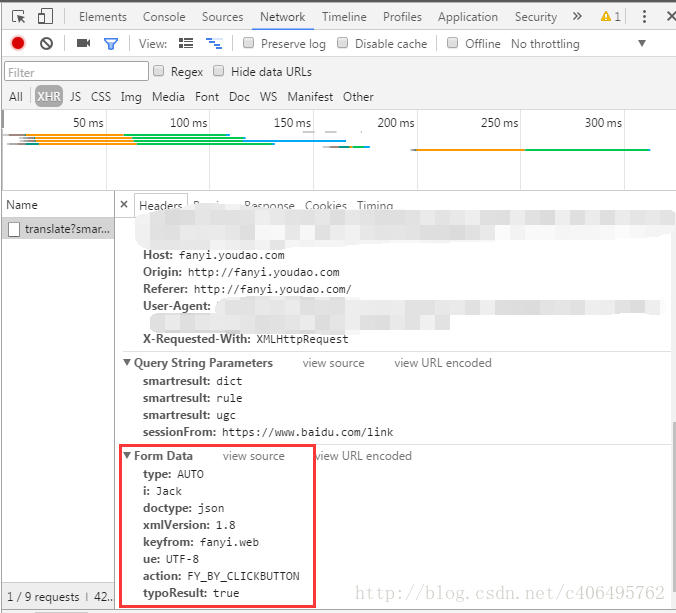
7.记住这些信息,这是我们一会儿写程序需要用到的。
新建文件translate_test.py,编写如下代码:
# -*- coding: UTF-8 -*-
from urllib import request
from urllib import parse
import json
if __name__ == "__main__":
#对应上图的Request URL
Request_URL = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=https://www.baidu.com/link'
#创建Form_Data字典,存储上图的Form Data
Form_Data = {}
Form_Data['type'] = 'AUTO'
Form_Data['i'] = 'Jack'
Form_Data['doctype'] = 'json'
Form_Data['xmlVersion'] = '1.8'
Form_Data['keyfrom'] = 'fanyi.web'
Form_Data['ue'] = 'ue:UTF-8'
Form_Data['action'] = 'FY_BY_CLICKBUTTON'
#使用urlencode方法转换标准格式
data = parse.urlencode(Form_Data).encode('utf-8')
#传递Request对象和转换完格式的数据
response = request.urlopen(Request_URL,data)
#读取信息并解码
html = response.read().decode('utf-8')
#使用JSON
translate_results = json.loads(html)
#找到翻译结果
translate_results = translate_results['translateResult'][0][0]['tgt']
#打印翻译信息
print("翻译的结果是:%s" % translate_results)
这样我们就可以查看翻译的结果了,如下图所示:

JSON是一种轻量级的数据交换格式,我们需要从爬取到的内容中找到JSON格式的数据,这里面保存着我们想要的翻译结果,再将得到的JSON格式的翻译结果进行解析,得到我们最终想要的样子:杰克。
以上所述是小编给大家介绍的Python3网络爬虫(二):利用urllib.urlopen向有道翻译发送数据获得翻译结果详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!
相关文章
 这篇文章主要介绍了如何取消pyecharts绘制地图时默认显示小圆点标识,文章内容介绍详细具有一定的参考价值 需要的小伙伴可以参考一下2022-04-04
这篇文章主要介绍了如何取消pyecharts绘制地图时默认显示小圆点标识,文章内容介绍详细具有一定的参考价值 需要的小伙伴可以参考一下2022-04-04 今天小编就为大家分享一篇Python实现个人微信号自动监控告警的示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-07-07
今天小编就为大家分享一篇Python实现个人微信号自动监控告警的示例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-07-07
详解Python 定时框架 Apscheduler原理及安装过程
Apscheduler是一个非常强大且易用的类库,可以方便我们快速的搭建一些强大的定时任务或者定时监控类的调度系统,这篇文章主要介绍了Python 定时框架 Apscheduler ,需要的朋友可以参考下2019-06-06 这篇文章主要为大家介绍了Python语法糖遍历列表时删除元素详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-05-05
这篇文章主要为大家介绍了Python语法糖遍历列表时删除元素详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-05-05 这篇文章主要介绍了Python的Flask框架与数据库连接的教程,是Flask框架学习当中的基本知识,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Python的Flask框架与数据库连接的教程,是Flask框架学习当中的基本知识,需要的朋友可以参考下2015-04-04 这篇文章主要介绍了Python中初始化一个二维数组及注意事项说明,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08
这篇文章主要介绍了Python中初始化一个二维数组及注意事项说明,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08 今天小编就为大家分享一篇python logging 日志的级别调整方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02
今天小编就为大家分享一篇python logging 日志的级别调整方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02 这篇文章主要介绍了Django中使用Celery的方法示例,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-11-11
这篇文章主要介绍了Django中使用Celery的方法示例,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-11-11 这篇文章主要介绍了Pytest fixture及conftest相关详解,fixture是在测试函数运行前后,由pytest执行的外壳函数,更多相关内容需要的朋友可以参考一下2022-09-09
这篇文章主要介绍了Pytest fixture及conftest相关详解,fixture是在测试函数运行前后,由pytest执行的外壳函数,更多相关内容需要的朋友可以参考一下2022-09-09 这篇文章主要介绍了pytorch 中nn.Dropout的使用说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05
这篇文章主要介绍了pytorch 中nn.Dropout的使用说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-05-05










最新评论