
python批量下载抖音视频
更新时间:2019年06月17日 14:50:00 作者:贾继康
这篇文章主要为大家详细介绍了python批量下载抖音视频,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
本文实例为大家分享了python批量下载抖音视频的具体代码,供大家参考,具体内容如下
知识储备:博主是在Pycharm下进行的
文件夹:dou_ying
1、在文件夹doy_ying下新建第一个文件:dou_ying_video_download.py
代码:
# coding=utf-8
"""
@author: jiajiknag
程序功能:批量下载抖音视频
"""
import requests
import bs4
import os
import json
import re
import sys
import time
# 如果一个对象没有实现上下文,我们就不能把它用于with语句。这个时候,可以用closing()来把该对象变为上下文对象。
# closing-将任意对象变为上下文对象,并支持with语句。
from contextlib import closing
# Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库
# urllib3.disable_warnings()禁用urllib3警告的方法
requests.packages.urllib3.disable_warnings()
# 创建类Sipder()
class Spider():
def __init__(self):
# UA对照表:https://blog.csdn.net/time888/article/details/72822729
self.headers = {
# 用户代理:用于浏览器识别的,可以看出自己系统版本,浏览器,浏览器内核等
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
# 输出信息-视频信息
print('[INFO]:Douyin(抖音) App Video downloader...')
print('[Version]: V1.0')
print('[Author]: Jiajikang')
# 创建函数run():外部调用运行
def run(self):
# 输入ID地址(爬去某人抖音视频的抖音号)
user_id = input('Enter the ID:')
try:
# 因为抖音号是数字所以使用int()验证是否是数字
int(user_id)
# 输入错误时输出except下的语句
except:
print('[Error]:ID error...')
return
video_names, video_urls, nickname = self._parse_userID(user_id)
# os.listdir()方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
if nickname not in os.listdir():
# os.mkdir() 方法用于以数字权限模式创建目录
os.mkdir(nickname)
print('[INFO]:Number of Videos <%s>' % len(video_urls))
for num in range(len(video_names)):
# %d是一个占位符,标识一个字符串型的数据, %s也是一个占位符,标识一个字符串型的数据
print('[INFO]:Parsing <No.%d> <Url:%s>' % (num+1, video_urls[num]))
temp = video_names[num].replace('\\', '')
video_name = temp.replace('/', '')
# 调用函数_downloader()
self._downloader(video_urls[num], os.path.join(nickname, video_name))
print('\n')
print('[INFO]:All Done...')
# 创建函数_downloader()并含有参数:路径和视频的url-视频下载
def _downloader(self, video_url, path):
# 定义size并初始化为0
size = 0
# 定义一个变量download_url:利用函数_get_download_url()来获取视频url
download_url = self._get_download_url(video_url)
with closing(requests.get(download_url, headers=self.headers, stream=True, verify=False)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
sys.stdout.write('[File Size]: %0.2f MB\n' % (content_size/chunk_size/1024))
# 使用写入的方式打开,如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
with open(path, 'wb') as f:
# 遍历获取数据
for data in response.iter_content(chunk_size=chunk_size):
# 向文件中写入指定的字符串data
f.write(data)
# 计算写入字符串的长度
size += len(data)
# flush() 方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。
f.flush()
sys.stdout.write('[Progress]: %0.2f%%' % float(size/content_size*100) + '\r')
sys.stdout.flush()
# 创建函数_get_download_url()并含有形参video_url:获得视频下载地址
def _get_download_url(self, video_url):
# 获取视频的下载地址
# Requests 可以为 HTTPS 请求验证 SSL 证书,就像 web 浏览器一样。要想检查某个主机的 SSL 证书,你可以使用 verify 参数:
# 定义变量res用来接收视频地址,verify 仅应用于主机证书
res = requests.get(url=video_url, verify=False)
# 将res.text 文件利用'lxml'解析成xml文件,了解lxml--https://blog.csdn.net/tanzuozhev/article/details/50442243
soup = bs4.BeautifulSoup(res.text, 'lxml')
# 使用find_all来获取网页中JavaScript中的script的变量;[-1]去除最后一个字符
script = soup.find_all('script')[-1]
# 定义变量date=正则表达式\[(.+)]\,[0]可以使其返回一个字典
video_url_js = re.findall('var data = \[(.+)\];', str(script))[0]
# 使用loads()下载
html = json.loads(video_url_js)
# 返回,使用[0]是返回一个字典
return html['video']['play_addr']['url_list'][0]
# 定义函数_parse_userID()且形参user_id;通过user_id获取该用户发布的所有视频
def _parse_userID(self, user_id):
# 获取所有视频
video_names = []
video_urls = []
unique_id = ''
# 当获取的id不是用户的id时:
while unique_id != user_id:
# 获取url-下载
search_url = 'https://api.amemv.com/aweme/v1/discover/search/?keyword={}&count=10&type=1&aid=1128'.format(user_id)
res = requests.get(url=search_url, verify=False)
res_dic = json.loads(res.text)
uid = res_dic['user_list'][0]['user_info']['uid']
aweme_count = res_dic['user_list'][0]['user_info']['aweme_count']
nickname = res_dic['user_list'][0]['user_info']['nickname']
unique_id = res_dic['user_list'][0]['user_info']['unique_id']
# 用户的url
user_url = 'https://www.douyin.com/aweme/v1/aweme/post/?user_id={}&max_cursor=0&count={}'.format(uid, aweme_count)
# 请求获取用户的url
res = requests.get(url=user_url, verify=False)
# 下载后去的url转换的文本
res_dic = json.loads(res.text)
i = 1
# 遍历下载的文本
for each in res_dic['aweme_list']:
share_desc = each['share_info']['share_desc']
if '抖音-原创音乐短视频社区' == share_desc:
video_names.append(str(i) + '.mp4')
i += 1
else:
video_names.append(share_desc + '.mp4')
video_urls.append(each['share_info']['share_url'])
return video_names, video_urls, nickname
"""
if __name__ == '__main__':
# 创建对象
sp = Spider()
sp.run()
"""
温馨提示: 有些库是要自己去下载,一般使用命令在提示符下输入:pip install 自己要下载的库,如下图是博主下载的。

2、在文件夹doy_ying下新建第二个文件:run.py
代码:
# coding=utf-8 """ @author: jiajiknag 程序功能: 测试抖音视频的下载 """ from dou_ying_video_download import Spider if __name__ == '__main__': # 创建类Spider()对象 sp = Spider() # 运行开始下载 sp.run()
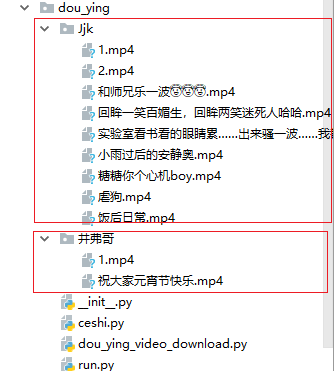
3、结果
这是我在抖音中随便找的一个发布抖音视频比较少的来测试一下,以及我还下载了自己的抖音

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要为大家详细介绍了Python如何实现在指定范围内筛选并剔除Excel表格中的数据,文中的示例代码讲解详细,感兴趣的可以了解一下2023-06-06
这篇文章主要为大家详细介绍了Python如何实现在指定范围内筛选并剔除Excel表格中的数据,文中的示例代码讲解详细,感兴趣的可以了解一下2023-06-06 决策树(Decision Tree)是一种基本的分类与回归方法,这篇文章主要给大家介绍了关于Python机器学习算法之决策树算法实现与优缺点的相关资料,需要的朋友们下面随着小编来一起学习学习吧2021-05-05
决策树(Decision Tree)是一种基本的分类与回归方法,这篇文章主要给大家介绍了关于Python机器学习算法之决策树算法实现与优缺点的相关资料,需要的朋友们下面随着小编来一起学习学习吧2021-05-05 这篇文章给大家分享了Python3中详解fabfile的编写的相关知识点以及重要内容,有兴趣的朋友跟着学习下。2018-06-06
这篇文章给大家分享了Python3中详解fabfile的编写的相关知识点以及重要内容,有兴趣的朋友跟着学习下。2018-06-06 这篇文章主要介绍了Python中用于去除空格的三个函数的使用小结,对strip()和lstrip()和rstrip()这三个函数做了简单的讲解,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Python中用于去除空格的三个函数的使用小结,对strip()和lstrip()和rstrip()这三个函数做了简单的讲解,需要的朋友可以参考下2015-04-04 这篇文章主要为大家解析了python select.select模块通信全过程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-09-09
这篇文章主要为大家解析了python select.select模块通信全过程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-09-09 本篇文章给大家总结了Python中if-elif-else的相关知识点以及语法相关内容,有兴趣的朋友参考学习下。2018-06-06
本篇文章给大家总结了Python中if-elif-else的相关知识点以及语法相关内容,有兴趣的朋友参考学习下。2018-06-06 这篇文章主要为大家详细介绍了python识别图片指定区域文字内容,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-04-04
这篇文章主要为大家详细介绍了python识别图片指定区域文字内容,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-04-04
python去除删除数据中\u0000\u0001等unicode字符串的代码
这篇文章主要介绍了python去除删除数据中\u0000\u0001等unicode字符串的代码,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-03-03
python的ImageTk.PhotoImage大坑及解决
这篇文章主要介绍了python的ImageTk.PhotoImage大坑及解决方案,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-11-11 这篇文章主要为大家详细介绍了TensorFlow实现简单线性回归,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-03-03
这篇文章主要为大家详细介绍了TensorFlow实现简单线性回归,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-03-03










最新评论