
python爬虫之爬取百度音乐的实现方法
在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同。在上次爬虫中,每一类数据都要从其父类(包括其父节点的父节点)上往下寻找ROI数据所在的子节点,这样就会使爬虫很臃肿,因为很多数据有相同的父节点,每次都要重复的找到这个父节点。这样的爬虫效率很低。
因此,笔者在上次的基础上,改进了一下爬取的策略,笔者以实例来描述。
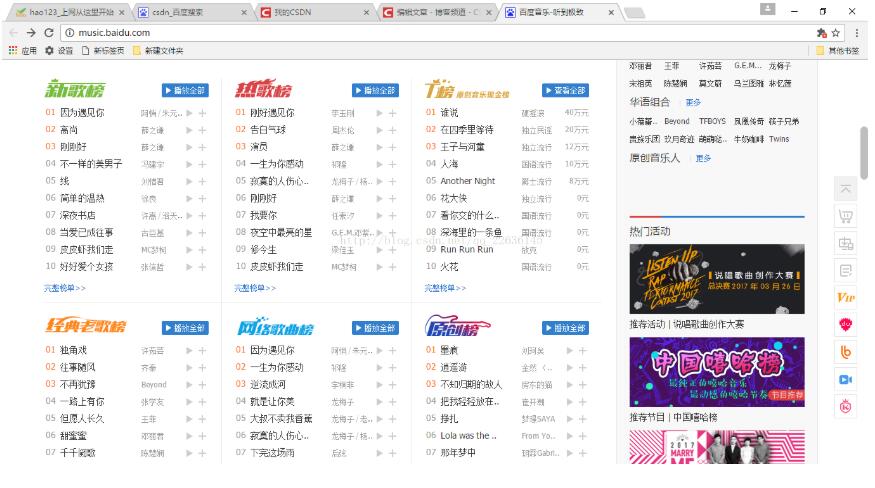
如图,笔者此次爬取的是百度音乐的页面,所爬取的类容是上面榜单下的所有内容(歌曲名,歌手,排名)。如果按照上次的爬虫的方法便要写上三个select方法,分别抓取歌曲名,歌手,排名,但笔者观察得知这三项数据皆放在一个li标签内,如图:
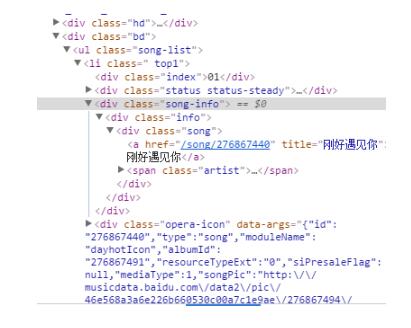
这样我们是不是直接抓取ul标签,再分析其中的数据便可得到全部数据了?答案是,当然可以。
但Beaufulsoup不能直接提供这样的方法,但Python无所不能,python里面自带的re模块是我见过最迷人的模块之一。它能在字符串中找到我们让我们roi的区域,上述的li标签中包含了我们需要的歌曲名,歌手,排名数据,我们只需要在li标签中通过re.findall()方法,便可找到我们需要的数据。这样就能够大大提升我们爬虫的效率。
我们先来直接分析代码:
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
data = soup.select('div.ranklist-wrapper.clearfix div.bd ul.song-list li')
pattern1 = re.compile(r'<li.*?<div class="index">(.*?)</div>.*?title="(.*?)".*?title="(.*?)".*?</li>', re.S)
pattern2 = re.compile(r'<li.*?<div class="index">(.*?)</div>.*?title="(.*?)".*?target="_blank">(.*?)</a>', re.S)
wants = []
for item in data:
# print(item)
final = re.findall(pattern1, str(item))
if len(final) == 1:
# print(final[0])
wants.append(final[0])
else:
other = re.findall(pattern2, str(item))
# print(other[0])
wants.append(other[0])
return wants
上面的代码是我分析网页数据的全部代码,这里不得不说python语言的魅力,数十行代码便能完成java100行的任务,C/C++1000行的任务。上述函数中,笔者首先通过Beautifulsoup得到该网页的源代码,再通过select()方法得到所有li标签中的数据。
到这里,这个爬虫便要进入到最重要的环节了,相信很多不懂re模块的童靴们有点慌张,在这里笔者真的是强烈推荐对python有兴趣的童靴们一定要学习这个非常重要的一环。首先,我们知道re的方法大多只针对string型数据,因此我们调用str()方法将每个list中的数据(即item)转换为string型。然后便是定义re的pattern了,这是个稍显复杂的东西,其中主要用到re.compile()函数得到要在string中配对的pattern,这里笔者便不累述了,感兴趣的童靴可以去网上查阅一下资料。
上述代码中,笔者写了两个pattern,因为百度音乐的网页里,li标签有两个结构,当用一个pattern在li中找不到数据时,便使用另一个pattern。关于re.findadd()方法,它会返回一个list,里面装着tuple,但其实我们知道我们找到的数据就是list[0],再将每个数据添加到另一个List中,让函数返回。
相信很多看到这里的小伙伴已经云里雾里,无奈笔者对re板块也知道的不多,对python感兴趣的同学可以查阅相关资料再来看一下代码,相信能够如鱼得水。
完整的代码如下:
import requests
from bs4 import BeautifulSoup
import re
def get_one_page(url):
wb_data = requests.get(url)
wb_data.encoding = wb_data.apparent_encoding
if wb_data.status_code == 200:
return wb_data.text
else:
return None
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
data = soup.select('div.ranklist-wrapper.clearfix div.bd ul.song-list li')
pattern1 = re.compile(r'<li.*?<div class="index">(.*?)</div>.*?title="(.*?)".*?title="(.*?)".*?</li>', re.S)
pattern2 = re.compile(r'<li.*?<div class="index">(.*?)</div>.*?title="(.*?)".*?target="_blank">(.*?)</a>', re.S)
wants = []
for item in data:
# print(item)
final = re.findall(pattern1, str(item))
if len(final) == 1:
# print(final[0])
wants.append(final[0])
else:
other = re.findall(pattern2, str(item))
# print(other[0])
wants.append(other[0])
return wants
if __name__ == '__main__':
url = 'http://music.baidu.com/'
html = get_one_page(url)
data = parse_one_page(html)
for item in data:
dict = {
'序列': item[0],
'歌名': item[1],
'歌手': item[2]
}
print(dict)
最后我们看到的输出结果如下:

好了,笔者今天就到这里了。希望喜欢python的萌新能够快速实现自己的spider,也希望一些大神们能够看到这篇文章时不吝赐教。
以上这篇python爬虫之爬取百度音乐的实现方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
相关文章
 图像加噪声就是其中一种常见的处理方式,噪声可以帮助提高图像的真实性和复杂性,使得处理后的图像更加接近真实的场景,本文主要介绍了python图像加噪声的实现示例,感兴趣的可以了解一下2023-08-08
图像加噪声就是其中一种常见的处理方式,噪声可以帮助提高图像的真实性和复杂性,使得处理后的图像更加接近真实的场景,本文主要介绍了python图像加噪声的实现示例,感兴趣的可以了解一下2023-08-08
Python与xlwings黄金组合处理Excel各种数据和自动化任务
这篇文章主要为大家介绍了Python与xlwings黄金组合处理Excel各种数据和自动化任务示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪<BR>2023-12-12 数据增强是一种生成合成数据的方法,即通过调整原始样本来创建新样本。这样我们就可获得大量的数据。这不仅增加了数据集的大小,还提供了单个样本的多个变体,这有助于我们的机器学习模型避免过度拟合2021-06-06
数据增强是一种生成合成数据的方法,即通过调整原始样本来创建新样本。这样我们就可获得大量的数据。这不仅增加了数据集的大小,还提供了单个样本的多个变体,这有助于我们的机器学习模型避免过度拟合2021-06-06 django有默认自带的数据库,当然也可以用其他的数据库,下面这篇文章主要给大家介绍了关于Django数据库(SQlite)基本入门使用教程的相关资料,需要的朋友可以参考下2022-07-07
django有默认自带的数据库,当然也可以用其他的数据库,下面这篇文章主要给大家介绍了关于Django数据库(SQlite)基本入门使用教程的相关资料,需要的朋友可以参考下2022-07-07 最近做了一个简单的文件传输系统,基于ftp协议,使用python语言开发,虽然python里面已经有ftplib模块,可以很容易的实现ftp服务器,这篇文章主要介绍了python实现ftp文件传输系统的案例分析,需要的朋友可以参考下2020-03-03
最近做了一个简单的文件传输系统,基于ftp协议,使用python语言开发,虽然python里面已经有ftplib模块,可以很容易的实现ftp服务器,这篇文章主要介绍了python实现ftp文件传输系统的案例分析,需要的朋友可以参考下2020-03-03 本文给大家分享的是使用python实现将一行里的内容进行分行输出,一共给出了四种方法,小伙伴们可以参考下2015-11-11
本文给大家分享的是使用python实现将一行里的内容进行分行输出,一共给出了四种方法,小伙伴们可以参考下2015-11-11 Arrow是一个功能强大、易用且具有优雅设计的Python日期时间库,它建立在Python的datetime模块之上,旨在弥补datetime模块在处理日期时间时的一些不足之处,下面我们就来了解一下Arrow库的常见时间操作吧2023-12-12
Arrow是一个功能强大、易用且具有优雅设计的Python日期时间库,它建立在Python的datetime模块之上,旨在弥补datetime模块在处理日期时间时的一些不足之处,下面我们就来了解一下Arrow库的常见时间操作吧2023-12-12 这篇文章主要介绍了在Python下多线程编程的尝试,由于GIL的存在,多线程在Python开发领域一直是个热门问题,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了在Python下多线程编程的尝试,由于GIL的存在,多线程在Python开发领域一直是个热门问题,需要的朋友可以参考下2015-04-04 这篇文章主要介绍了Python爬取豆瓣视频信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了Python爬取豆瓣视频信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11 这篇文章主要介绍了用Python处理Args的3种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
这篇文章主要介绍了用Python处理Args的3种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03










最新评论