
python Plotly绘图工具的简单使用
1、plotly库的相关介绍
1)相关说明
- plotly是一个基于javascript的绘图库,plotly绘图种类丰富,效果美观;
- 易于保存与分享plotly的绘图结果,并且可以与Web无缝集成;
- ploty默认的绘图结果,是一个HTML网页文件,通过浏览器可以直接查看;
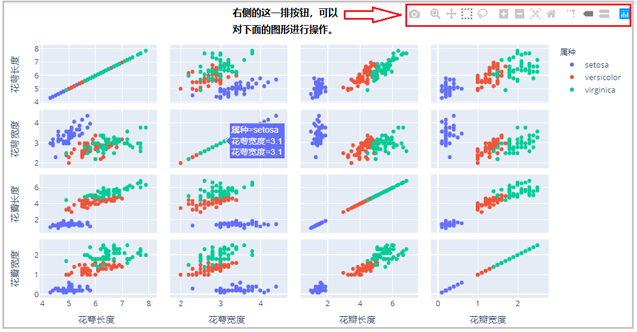
2)plotly与matplotlib、seaborn的关系
需要注意的是,ployly绘图库与matplotlib绘图库、seaborn绘图库并没有什么关系。也就是说说plotly是一个单独的绘图库,有自己独特的绘图语法、绘图参数和绘图原理,因此我们需要单独学习它。
2、导入相关库
对于我们做数据分析的人员来说,一般用的都是离线绘图库。在线绘图库需要的话,可以自己百度研究。
import os
import numpy as np
import pandas as pd
import plotly as py
import plotly.graph_objs as go
import plotly.expression as px
from plotly import tools
import warnings
warnings.filterwarnings("ignore")
3、plotly绘图原理
1)ployly常用的两个绘图模块:graph_objs和expression
graph_objs和expression是plotly里面两个很常用的绘图库,graph_objs相当于matplotlib,在数据组织上比较费劲,但是任然比起matplotlib绘图更简单、更好看。这里说的费劲是相对于expression库来说的。expression库相当于seaborn的地位,在数据组织上较为容易,绘图比起seaborn来说,也更加容易。这里你心里有个印象即可,知道这两个绘图库很牛,就行了。
对于graph_objs绘图库,我们常命名为“go”(import plotly.graph_objs as go);对于expression绘图库,我们常命名为“px”(import plotly.expression as px)。
2)graph_objs(“go”)库的绘图原理
① 简单的案例说明
df = pd.read_excel("plot.xlsx")
# 步骤一
trace0 = go.Scatter(x=df["年份"],y=df["城镇居民"],name="城镇居民")
trace1 = go.Scatter(x=df["年份"],y=df["农村居民"],name="农村居民")
# 步骤二
data = [trace0,trace1]
# 步骤三
fig = go.Figure(data)
# 步骤四
fig.update_layout(
title="城乡居民家庭人均收入",
xaxis_title="年份",
yaxis_title="人均收入(元)"
)
# 步骤五
fig.show()
结果如下:

② 原理说明
1、绘制图形轨迹,在ployly里面叫做trace,每一个轨迹是一个trace。
2、将轨迹包裹成一个列表,形成一个“轨迹列表”。一个轨迹放在一个列表中,多个轨迹也是放在一个列表中。
3、创建画布的同时,并将上述的“轨迹列表”,传入到Figure()中。
4、使用Layout添加其他的绘图参数,完善图形。
5、展示图形。
3)expression(“px”)库的绘图原理
① 简单的案例说明
iris = pd.read_excel("iris.xlsx",sheet_name="Sheet2")
fig = px.scatter(iris,x="花萼长度",y="花萼宽度",color="属种")
fig.show()
结果如下:
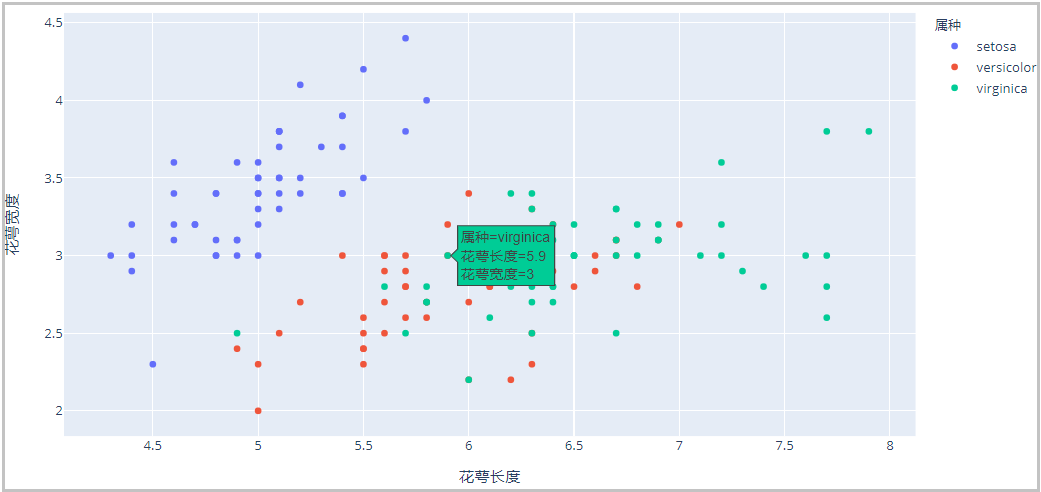
② 原理说明
1、直接使用px调用某个绘图方法时,会自动创建画布,并画出图形。
2、展示图形。
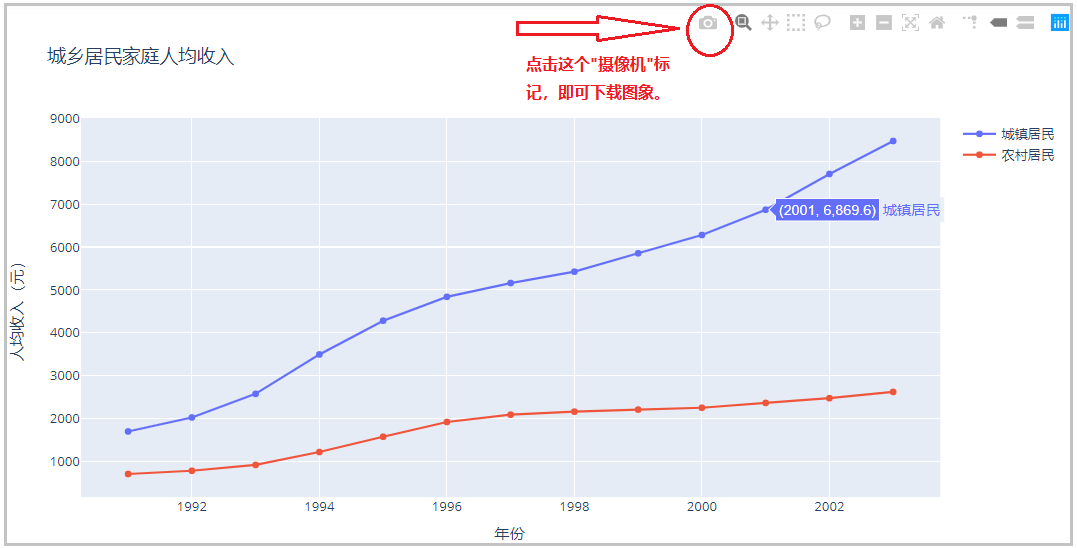
4、保存图形的两种方式
1)直接下载下来:保存成png静态图片
2)使用py.offline.plot(fig,filename=“XXX.html”)代码保存成html网页动态图片
iris = pd.read_excel("iris.xlsx",sheet_name="Sheet2")
fig = px.scatter(iris,x="花萼长度",y="花萼宽度",color="属种")
py.offline.plot(fig,filename="iris1.html")
结果如下:该文件是一个html文件,这里上传不了,自己下去尝试一下就知道了。
3)总结说明
使用“照相机”那个下载按钮,可以直接将图片下载保存在本地,但是这个图片是一个静态图片,没有交互性。但是使用py.offline.plot()方法,可以将图片保存成一个html的网页格式,其他人可以在电脑上直接打开这个html网页,并且保留了图片的原始样式,具有交互性。
5、绘制双y轴图
1)数据集如下
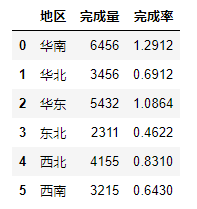
2)绘制不同地区的“任务完成量”和“任务完成率”情况
df = pd.read_excel("double_y.xlsx")
x = df["地区"]
y1 = df["完成量"]
y2 = df["完成率"]
trace0 = go.Bar(x=x,y=y1,
marker=dict(color=["red","blue","green","darkgrey","darkblue","orange"]),
opacity=0.5,
name="不同地区的任务完成量")
trace1 = go.Scatter(x=x,y=y2,
mode="lines",
name="不同地区的任务完成率",
# 【步骤一】:使用这个参数yaxis="y2",就是绘制双y轴图
yaxis="y2")
data = [trace0,trace1]
layout = go.Layout(title="不同地区的任务完成量和任务完成率情况",
xaxis=dict(title="地区"),
yaxis=dict(title="不同地区的任务完成量"),
# 【步骤二】:给第二个y轴,添加标题,指定第二个y轴,在右侧。
yaxis2=dict(title="不同地区的任务完成率",overlaying="y",side="right"),
legend=dict(x=0.78,y=0.98,font=dict(size=12,color="black")))
fig = go.Figure(data=data,layout=layout)
fig.show()
结果如下:
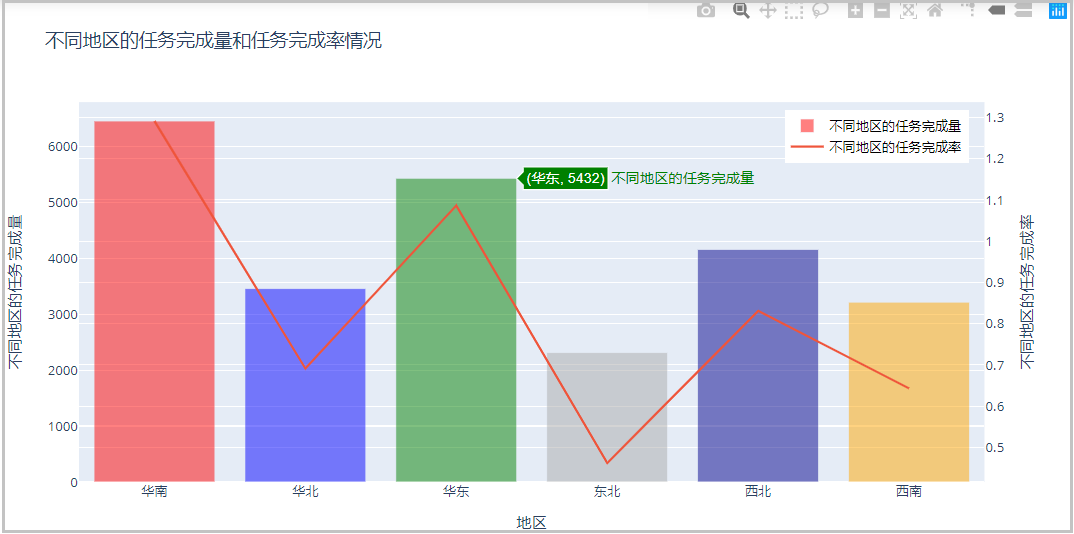
6、绘制多子图:一个画布上绘制多个图形
1)相关库和方法介绍
1、绘制多个子图,需要先导入tools库。from plotly import tools
2、tools.make_subplots(rows= ,cols=)用于指定绘图布局,rows和cols表示将画布布局成几行几列。
3、fig.append_trace()将每个图形轨迹trace,绘制在不同的位置上。
2)分别绘制不同地区的“任务完成量”和“任务完成率”情况
# 步骤一:导入相关库
from plotly import tools
# 步骤二:指定绘图布局
fig = tools.make_subplots(rows=2,cols=1)
# 步骤三:绘制图形轨迹
trace0 = go.Bar(x=x,y=y1,
marker=dict(color=["red","blue","green","darkgrey","darkblue","orange"]),
opacity=0.5,
name="不同地区的任务完成量")
trace1 = go.Scatter(x=x,y=y2,
mode="lines",
name="不同地区的任务完成率",
line=dict(width=2,color="red"))
# 步骤四:将第一个轨迹,添加到第1行的第1个位置
# 将第二个轨迹,添加到第2行的第1个位置
fig.append_trace(trace0,1,1)
fig.append_trace(trace1,2,1)
# 步骤四:根据自己的需求,给图形添加标题。height、width参数用于指定图形的宽和高
fig.update_layout(title="不同地区的任务量与完成量",height=800,width=800)
# 步骤五:展示图形
fig.show()
结果如下:
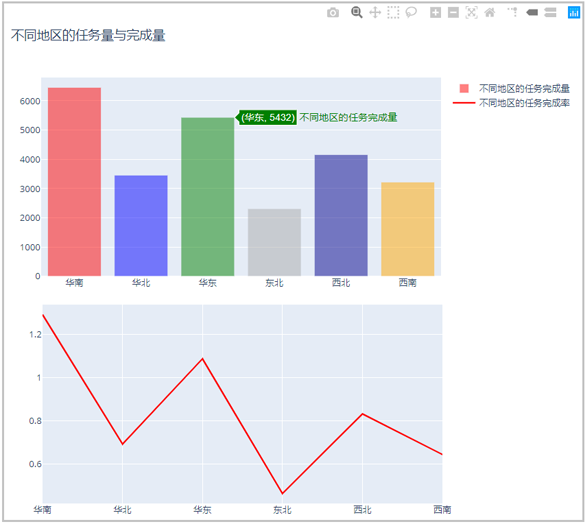
到此这篇关于python Plotly绘图工具的简单使用的文章就介绍到这了,更多相关python Plotly绘图内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

pandas中.loc和.iloc以及.at和.iat的区别说明
这篇文章主要介绍了pandas中.loc和.iloc以及.at和.iat的区别说明,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-04-04 这篇文章主要介绍了使用Python操作MySQL的一些基本方法,Python+MySQL也是服务器端快速开发的一种绝佳搭配方案,需要的朋友可以参考下2015-08-08
这篇文章主要介绍了使用Python操作MySQL的一些基本方法,Python+MySQL也是服务器端快速开发的一种绝佳搭配方案,需要的朋友可以参考下2015-08-08
详解使用Selenium爬取豆瓣电影前100的爱情片相关信息
这篇文章主要介绍了详解使用Selenium爬取豆瓣电影前100的爱情片相关信息,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03 这篇文章主要介绍了Python读取VOC中的xml目标框实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-03-03
这篇文章主要介绍了Python读取VOC中的xml目标框实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-03-03 这篇文章主要介绍了Python爬虫如何应对Cloudflare邮箱加密,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了Python爬虫如何应对Cloudflare邮箱加密,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06 本文和你一起探索Python中的lambda函数,让你以最短的时间明白这个函数的原理。也可以利用碎片化的时间巩固这个函数,让你在处理工作过程中更高效2022-06-06
本文和你一起探索Python中的lambda函数,让你以最短的时间明白这个函数的原理。也可以利用碎片化的时间巩固这个函数,让你在处理工作过程中更高效2022-06-06 这篇文章主要介绍了Python 字符串操作,所谓字符串,就是由0个或者多个字符组成的有限序列,字符串的字符可以是特殊符号、英文字母、中文字符、日文的平假名或片假名、希腊字母、Emoji字符等等。下面我们大家一起来学习文章详细内容吧2021-11-11
这篇文章主要介绍了Python 字符串操作,所谓字符串,就是由0个或者多个字符组成的有限序列,字符串的字符可以是特殊符号、英文字母、中文字符、日文的平假名或片假名、希腊字母、Emoji字符等等。下面我们大家一起来学习文章详细内容吧2021-11-11
Python使用pymysql从MySQL数据库中读出数据的方法
今天小编就为大家分享一篇Python使用pymysql从MySQL数据库中读出数据的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-07-07 这篇文章主要介绍了Pycharm如何退出py.test模式问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-01-01
这篇文章主要介绍了Pycharm如何退出py.test模式问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-01-01 这篇文章主要介绍了Python设计模式结构型代理模式,代理模式即Proxy Pattern,为其他对象提供一种代理以控制对这个对象的访问,下文内容详细介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-02-02
这篇文章主要介绍了Python设计模式结构型代理模式,代理模式即Proxy Pattern,为其他对象提供一种代理以控制对这个对象的访问,下文内容详细介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-02-02










最新评论