
VBA处理数据与Python Pandas处理数据案例比较分析
更新时间:2020年04月07日 14:04:21 作者:Collin_PXY
这篇文章主要介绍了VBA处理数据与Python Pandas处理数据案例比较,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下
需求:
现有一个 csv文件,包含'CNUM'和'COMPANY'两列,数据里包含空行,且有内容重复的行数据。
要求:
1)去掉空行;
2)重复行数据只保留一行有效数据;
3)修改'COMPANY'列的名称为'Company_New‘;
4)并在其后增加六列,分别为'C_col',‘D_col',‘E_col',‘F_col',‘G_col',‘H_col'。
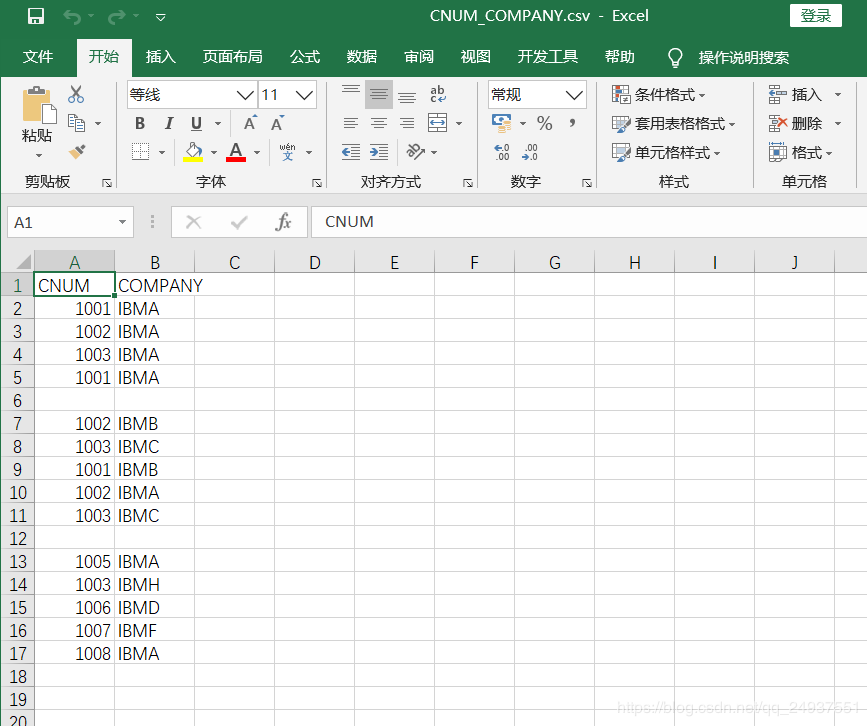
一,使用 Python Pandas来处理:
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
def deal_with_data(filepath,newpath):
file_obj=open(filepath)
df=pd.read_csv(file_obj) # 读取csv文件,创建 DataFrame
df=df.reindex(columns=['CNUM','COMPANY','C_col','D_col','E_col','F_col','G_col','H_col'],fill_value=None) # 重新指定列索引
df.rename(columns={'COMPANY':'Company_New'}, inplace = True) # 修改列名
df=df.dropna(axis=0,how='all') # 去除 NAN 即文件中的空行
df['CNUM'] = df['CNUM'].astype('int32') # 将 CNUM 列的数据类型指定为 int32
df = df.drop_duplicates(subset=['CNUM', 'Company_New'], keep='first') # 去除重复行
df.to_csv(newpath,index=False,encoding='GBK')
file_obj.close()
if __name__=='__main__':
file_path=r'C:\Users\12078\Desktop\python\CNUM_COMPANY.csv'
file_save_path=r'C:\Users\12078\Desktop\python\CNUM_COMPANY_OUTPUT.csv'
deal_with_data(file_path,file_save_path)
二,使用 VBA来处理:
Option Base 1
Option Explicit
Sub main()
On Error GoTo error_handling
Dim wb As Workbook
Dim wb_out As Workbook
Dim sht As Worksheet
Dim sht_out As Worksheet
Dim rng As Range
Dim usedrows As Byte
Dim usedrows_out As Byte
Dim dict_cnum_company As Object
Dim str_file_path As String
Dim str_new_file_path As String
'assign values to variables:
str_file_path = "C:\Users\12078\Desktop\Python\CNUM_COMPANY.csv"
str_new_file_path = "C:\Users\12078\Desktop\Python\CNUM_COMPANY_OUTPUT.csv"
Set wb = checkAndAttachWorkbook(str_file_path)
Set sht = wb.Worksheets("CNUM_COMPANY")
Set wb_out = Workbooks.Add
wb_out.SaveAs str_new_file_path, xlCSV 'create a csv file
Set sht_out = wb_out.Worksheets("CNUM_COMPANY_OUTPUT")
Set dict_cnum_company = CreateObject("Scripting.Dictionary")
usedrows = WorksheetFunction.Max(getLastValidRow(sht, "A"), getLastValidRow(sht, "B"))
'rename the header 'COMPANY' to 'Company_New',remove blank & duplicate lines/rows.
Dim cnum_company As String
cnum_company = ""
For Each rng In sht.Range("A1", "A" & usedrows)
If VBA.Trim(rng.Offset(0, 1).Value) = "COMPANY" Then
rng.Offset(0, 1).Value = "Company_New"
End If
cnum_company = rng.Value & "-" & rng.Offset(0, 1).Value
If VBA.Trim(cnum_company) <> "-" And Not dict_cnum_company.Exists(rng.Value & "-" & rng.Offset(0, 1).Value) Then
dict_cnum_company.Add rng.Value & "-" & rng.Offset(0, 1).Value, ""
End If
Next rng
'loop the keys of dict split the keyes by '-' into cnum array and company array.
Dim index_dict As Byte
Dim arr_cnum()
Dim arr_Company()
For index_dict = 0 To UBound(dict_cnum_company.keys)
ReDim Preserve arr_cnum(1 To UBound(dict_cnum_company.keys) + 1)
ReDim Preserve arr_Company(1 To UBound(dict_cnum_company.keys) + 1)
arr_cnum(index_dict + 1) = Split(dict_cnum_company.keys()(index_dict), "-")(0)
arr_Company(index_dict + 1) = Split(dict_cnum_company.keys()(index_dict), "-")(1)
Debug.Print index_dict
Next
'assigns the value of the arrays to the celles.
sht_out.Range("A1", "A" & UBound(arr_cnum)) = Application.WorksheetFunction.Transpose(arr_cnum)
sht_out.Range("B1", "B" & UBound(arr_Company)) = Application.WorksheetFunction.Transpose(arr_Company)
'add 6 columns to output csv file:
Dim arr_columns() As Variant
arr_columns = Array("C_col", "D_col", "E_col", "F_col", "G_col", "H_col") '
sht_out.Range("C1:H1") = arr_columns
Call checkAndCloseWorkbook(str_file_path, False)
Call checkAndCloseWorkbook(str_new_file_path, True)
Exit Sub
error_handling:
Call checkAndCloseWorkbook(str_file_path, False)
Call checkAndCloseWorkbook(str_new_file_path, False)
End Sub
' 辅助函数:
'Get last row of Column N in a Worksheet
Function getLastValidRow(in_ws As Worksheet, in_col As String)
getLastValidRow = in_ws.Cells(in_ws.Rows.count, in_col).End(xlUp).Row
End Function
Function checkAndAttachWorkbook(in_wb_path As String) As Workbook
Dim wb As Workbook
Dim mywb As String
mywb = in_wb_path
For Each wb In Workbooks
If LCase(wb.FullName) = LCase(mywb) Then
Set checkAndAttachWorkbook = wb
Exit Function
End If
Next
Set wb = Workbooks.Open(in_wb_path, UpdateLinks:=0)
Set checkAndAttachWorkbook = wb
End Function
Function checkAndCloseWorkbook(in_wb_path As String, in_saved As Boolean)
Dim wb As Workbook
Dim mywb As String
mywb = in_wb_path
For Each wb In Workbooks
If LCase(wb.FullName) = LCase(mywb) Then
wb.Close savechanges:=in_saved
Exit Function
End If
Next
End Function
三,输出结果:
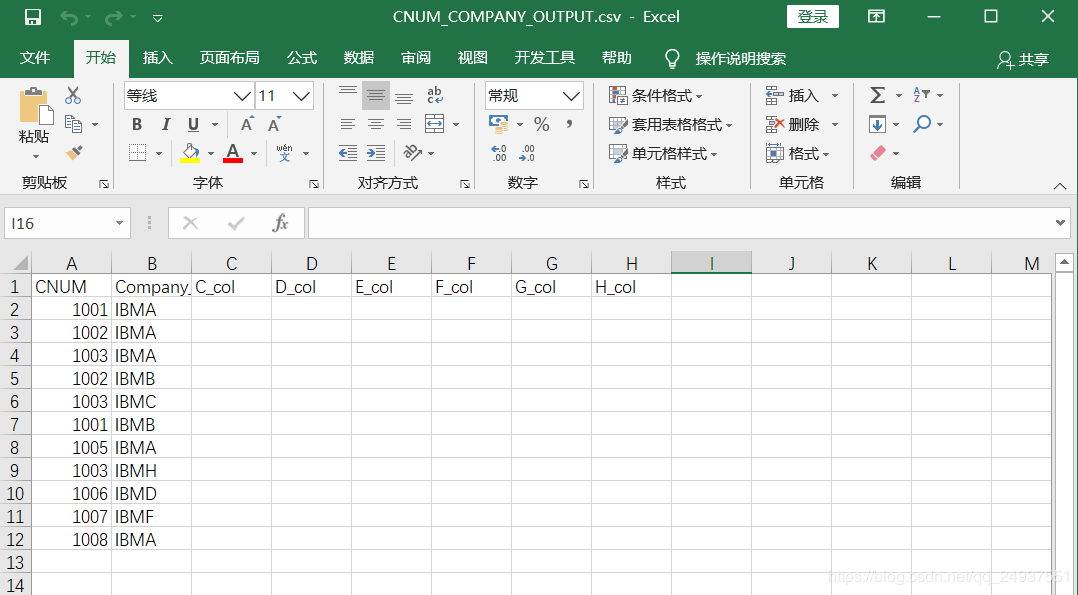
两种方法输出结果相同:
四,比较总结:
Python pandas 内置了大量处理数据的方法,我们不需要重复造轮子,用起来很方便,代码简洁的多。
Excel VBA 处理这个需求,使用了 数组,字典等数据结构(实际需求中,数据量往往很大,所以一些地方没有直接使用遍历单元格的方法),以及处理字符串,数组和字典的很多方法,对文件的操作也很复杂,一旦出错,调试起来比python也较困难,代码已经尽量优化,但还是远比 Python要多。
到此这篇关于VBA处理数据与Python Pandas处理数据案例比较分析的文章就介绍到这了,更多相关VBA与Python Pandas处理数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 表格拆分是常见的数据处理,本文主要介绍了Excel VBA按列拆分工作表和工作簿的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-01-01
表格拆分是常见的数据处理,本文主要介绍了Excel VBA按列拆分工作表和工作簿的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-01-01 VBA 浏览文件夹对话框调用实现代码。大家可以根据需要选择。2009-07-07
VBA 浏览文件夹对话框调用实现代码。大家可以根据需要选择。2009-07-07 本文主要介绍了VBA中Excel宏的介绍及应用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-05-05
本文主要介绍了VBA中Excel宏的介绍及应用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-05-05 本文给大家分享的是使用VBA解决Windows空当接龙的617局的方法和思路,有需要的小伙伴可以参考下。2015-09-09
本文给大家分享的是使用VBA解决Windows空当接龙的617局的方法和思路,有需要的小伙伴可以参考下。2015-09-09 要想一下子就替换掉很多个WORD文档中的内容,我们可以使用VBA的办法,本文主要介绍了VBA实现全文件快速替换的示例代码,具有一定的参考价值,感兴趣的可以了解一下2023-08-08
要想一下子就替换掉很多个WORD文档中的内容,我们可以使用VBA的办法,本文主要介绍了VBA实现全文件快速替换的示例代码,具有一定的参考价值,感兴趣的可以了解一下2023-08-08
VBA处理数据与Python Pandas处理数据案例比较分析
这篇文章主要介绍了VBA处理数据与Python Pandas处理数据案例比较,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2020-04-04 好多朋友想学习vba但相关资料不是很多,其实就是利用了vb的语法,结合office2009-07-07
好多朋友想学习vba但相关资料不是很多,其实就是利用了vb的语法,结合office2009-07-07 用vba实现将记录集输出到Excel模板...2007-02-02
用vba实现将记录集输出到Excel模板...2007-02-02 本文主要介绍了VBA中的循环代码的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-06-06
本文主要介绍了VBA中的循环代码的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-06-06 本文主要介绍了vba将excel按照某一列拆分成多个文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧<BR>2023-01-01
本文主要介绍了vba将excel按照某一列拆分成多个文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧<BR>2023-01-01










最新评论