
使用Python和百度语音识别生成视频字幕的实现
更新时间:2020年04月09日 10:50:17 作者:孙亖
这篇文章主要介绍了使用Python和百度语音识别生成视频字幕,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
从视频中提取音频
安装 moviepy
pip install moviepy
相关代码:
audio_file = work_path + '\\out.wav' video = VideoFileClip(video_file) video.audio.write_audiofile(audio_file,ffmpeg_params=['-ar','16000','-ac','1'])
根据静音对音频分段
使用音频库 pydub,安装:
pip install pydub
第一种方法:
# 这里silence_thresh是认定小于-70dBFS以下的为silence,发现小于 sound.dBFS * 1.3 部分超过 700毫秒,就进行拆分。这样子分割成一段一段的。
sounds = split_on_silence(sound, min_silence_len = 500, silence_thresh= sound.dBFS * 1.3)
sec = 0
for i in range(len(sounds)):
s = len(sounds[i])
sec += s
print('split duration is ', sec)
print('dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}'.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(sounds)))

感觉分割的时间不对,不好定位,我们换一种方法:
# 通过搜索静音的方法将音频分段
# 参考:https://wqian.net/blog/2018/1128-python-pydub-split-mp3-index.html
timestamp_list = detect_nonsilent(sound,500,sound.dBFS*1.3,1)
for i in range(len(timestamp_list)):
d = timestamp_list[i][1] - timestamp_list[i][0]
print("Section is :", timestamp_list[i], "duration is:", d)
print('dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}'.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(timestamp_list)))
输出结果如下:
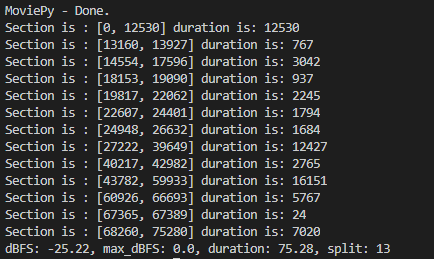
感觉这样好处理一些
使用百度语音识别
现在百度智能云平台创建一个应用,获取 API Key 和 Secret Key:

获取 Access Token
使用百度 AI 产品需要授权,一定量是免费的,生成字幕够用了。
'''
百度智能云获取 Access Token
'''
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode( 'utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.errno))
result_str = err.reason
if (IS_PY3):
result_str = result_str.decode()
print(result_str)
result = json.loads(result_str)
print(result)
if ('access_token' in result.keys() and 'scope' in result.keys()):
print(SCOPE)
if SCOPE and (not SCOPE in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope is not correct')
print('SUCCESS WITH TOKEN: %s EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
使用 Raw 数据进行合成
这里使用百度语音极速版来合成文字,因为官方介绍专有GPU服务集群,识别响应速度较标准版API提升2倍及识别准确率提升15%。适用于近场短语音交互,如手机语音搜索、聊天输入等场景。 支持上传完整的录音文件,录音文件时长不超过60秒。实时返回识别结果
def asr_raw(speech_data, token):
length = len(speech_data)
if length == 0:
# raise DemoError('file %s length read 0 bytes' % AUDIO_FILE)
raise DemoError('file length read 0 bytes')
params = {'cuid': CUID, 'token': token, 'dev_pid': DEV_PID}
#测试自训练平台需要打开以下信息
#params = {'cuid': CUID, 'token': token, 'dev_pid': DEV_PID, 'lm_id' : LM_ID}
params_query = urlencode(params)
headers = {
'Content-Type': 'audio/' + FORMAT + '; rate=' + str(RATE),
'Content-Length': length
}
url = ASR_URL + "?" + params_query
# print post_data
req = Request(ASR_URL + "?" + params_query, speech_data, headers)
try:
begin = timer()
f = urlopen(req)
result_str = f.read()
# print("Request time cost %f" % (timer() - begin))
except URLError as err:
# print('asr http response http code : ' + str(err.errno))
result_str = err.reason
if (IS_PY3):
result_str = str(result_str, 'utf-8')
return result_str
生成字幕
字幕格式: https://www.cnblogs.com/tocy/p/subtitle-format-srt.html
生成字幕其实就是语音识别的应用,将识别后的内容按照 srt 字幕格式组装起来就 OK 了。具体字幕格式的内容可以参考上面的文章,代码如下:
idx = 0
for i in range(len(timestamp_list)):
d = timestamp_list[i][1] - timestamp_list[i][0]
data = sound[timestamp_list[i][0]:timestamp_list[i][1]].raw_data
str_rst = asr_raw(data, token)
result = json.loads(str_rst)
# print("rst is ", result)
# print("rst is ", rst['err_no'][0])
if result['err_no'] == 0:
text.append('{0}\n{1} --> {2}\n'.format(idx, format_time(timestamp_list[i][0]/ 1000), format_time(timestamp_list[i][1]/ 1000)))
text.append( result['result'][0])
text.append('\n')
idx = idx + 1
print(format_time(timestamp_list[i][0]/ 1000), "txt is ", result['result'][0])
with open(srt_file,"r+") as f:
f.writelines(text)
总结
我在视频网站下载了一个视频来作测试,极速模式从速度和识别率来说都是最好的,感觉比网易见外平台还好用。
到此这篇关于使用Python和百度语音识别生成视频字幕的文章就介绍到这了,更多相关Python 百度语音识别生成视频字幕内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:
相关文章
 这篇文章主要介绍了python数据分析之时间序列分析详情,时间序列分析是基于随机过程理论和数理统计学方法,具体详细内容介绍,需要的小伙伴可以参考一下2022-08-08
这篇文章主要介绍了python数据分析之时间序列分析详情,时间序列分析是基于随机过程理论和数理统计学方法,具体详细内容介绍,需要的小伙伴可以参考一下2022-08-08 这篇文章主要给大家介绍了关于利用Python如何批量更新服务器文件的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用python具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2018-07-07
这篇文章主要给大家介绍了关于利用Python如何批量更新服务器文件的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用python具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2018-07-07 这篇文章主要介绍了python自然语言编码转换模块codecs介绍,codecs专门用作编码转换,通过它的接口是可以扩展到其他关于代码方面的转换,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了python自然语言编码转换模块codecs介绍,codecs专门用作编码转换,通过它的接口是可以扩展到其他关于代码方面的转换,需要的朋友可以参考下2015-04-04 在本篇内容里小编给大家整理分享的是一篇关于python创建文本文件的简单方法,有需要的朋友们可以参考学习下。2020-08-08
在本篇内容里小编给大家整理分享的是一篇关于python创建文本文件的简单方法,有需要的朋友们可以参考学习下。2020-08-08 这篇文章主要介绍了如何利用fig.add_subplot和axes.twinx().twiny()方法实现双X轴双Y轴绘图,文中的示例代码讲解详细,快跟随小编一起动手尝试一下吧2022-04-04
这篇文章主要介绍了如何利用fig.add_subplot和axes.twinx().twiny()方法实现双X轴双Y轴绘图,文中的示例代码讲解详细,快跟随小编一起动手尝试一下吧2022-04-04 Scipy是基于Numpy的科学计算工具库,方便、易于使用、专为科学和工程设计,是一个用于数学、科学、工程领域的常用软件包,这篇文章主要给大家介绍了关于Python常见报错解决之SciPy和NumPy版本冲突的相关资料,需要的朋友可以参考下2024-03-03
Scipy是基于Numpy的科学计算工具库,方便、易于使用、专为科学和工程设计,是一个用于数学、科学、工程领域的常用软件包,这篇文章主要给大家介绍了关于Python常见报错解决之SciPy和NumPy版本冲突的相关资料,需要的朋友可以参考下2024-03-03 这篇文章主要介绍了Python基于回溯法子集树模板解决最佳作业调度问题,简单说明了作业调度问题并结合实例形式给出了Python使用回溯法子集树模板实现最佳作业调度问题的具体步骤与相关操作技巧,需要的朋友可以参考下2017-09-09
这篇文章主要介绍了Python基于回溯法子集树模板解决最佳作业调度问题,简单说明了作业调度问题并结合实例形式给出了Python使用回溯法子集树模板实现最佳作业调度问题的具体步骤与相关操作技巧,需要的朋友可以参考下2017-09-09 本文主要介绍了Django之第三方平台QQ授权登录的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-05-05
本文主要介绍了Django之第三方平台QQ授权登录的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-05-05 这篇文章主要介绍了Python Asyncio调度原理详情,Python.Asyncio是一个大而全的库,它包括很多功能,而跟核心调度相关的逻辑除了三种可等待对象外,还有其它一些功能,它们分别位于runners.py,base_event.py,event.py三个文件中2022-06-06
这篇文章主要介绍了Python Asyncio调度原理详情,Python.Asyncio是一个大而全的库,它包括很多功能,而跟核心调度相关的逻辑除了三种可等待对象外,还有其它一些功能,它们分别位于runners.py,base_event.py,event.py三个文件中2022-06-06 这篇文章主要介绍了Python使用configparser库读取配置文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了Python使用configparser库读取配置文件,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02










最新评论