
Python scrapy爬取小说代码案例详解
更新时间:2020年07月09日 09:56:03 作者:咔咔kk
这篇文章主要介绍了Python scrapy爬取小说代码案例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
scrapy是目前python使用的最广泛的爬虫框架
架构图如下
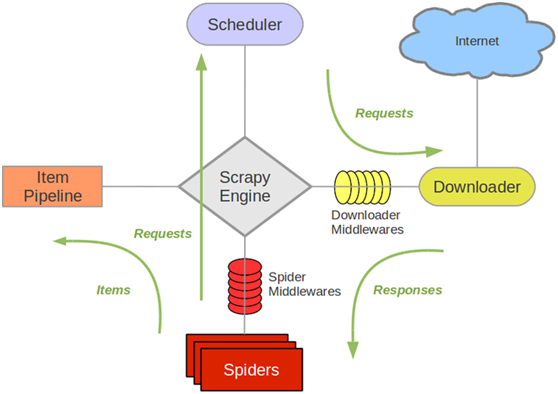
解释:
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- DownloaderMiddlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests
一。安装
pip install Twisted.whl
pip install Scrapy
Twisted的版本要与安装的python对应,https://jingyan.baidu.com/article/1709ad8027be404634c4f0e8.html
二。代码
本实例采用xpaths解析页面数据
按住shift-右键-在此处打开命令窗口
输入scrapy startproject qiushibaike 创建项目
输入scrapy genspiderqiushibaike 创建爬虫
1>结构
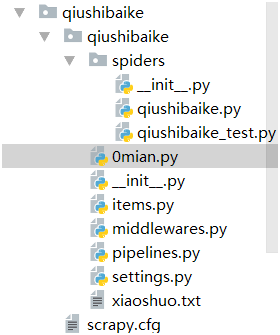
2>qiushibaike.py爬虫文件
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders.crawl import Rule, CrawlSpider
class BaiduSpider(CrawlSpider):
name = 'qiushibaike'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/']#启始页面
#
rules= (
Rule(LinkExtractor(restrict_xpaths=r'//a[@class="contentHerf"]'),callback='parse_item',follow=True),
Rule(LinkExtractor(restrict_xpaths=r'//ul[@class="pagination"]/li/a'),follow=True)
)
def parse_item(self, response):
title=response.xpath('//h1[@class="article-title"]/text()').extract_first().strip() #标题
time=response.xpath(' //span[@class="stats-time"]/text()').extract_first().strip() #发布时间
content=response.xpath('//div[@class="content"]/text()').extract_first().replace(' ','\n') #内容
score=response.xpath('//i[@class="number"]/text()').extract_first().strip() #好笑数
yield({"title":title,"content":content,"time":time,"score":score});
3>pipelines.py 数据管道[code]class QiushibaikePipeline:
class QiushibaikePipeline:
def open_spider(self,spider):#启动爬虫中调用
self.f=open("xiaoshuo.txt","w",encoding='utf-8')
def process_item(self, item, spider):
info=item.get("title")+"\n"+ item.get("time")+" 好笑数"+item.get("score")+"\n"+ item.get("content")+'\n'
self.f.write(info+"\n")
self.f.flush()
def close_spider(self,spider):#关闭爬虫中调用
self.f.close()
4>settings.py
开启ZhonghengPipeline
ITEM_PIPELINES = {
'qiushibaike.pipelines.QiushibaikePipeline': 300,
}
5>0main.py运行
from scrapy.cmdline import execute
execute('scrapy crawl qiushibaike'.split())
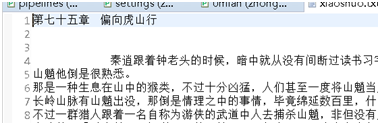
6>结果:
生成xiaohua.txt,里面有下载的笑话文字
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章

python中导入 train_test_split提示错误的解决
这篇文章主要介绍了python中导入 train_test_split提示错误的解决,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 这篇文章主要为大家详细介绍了python使用pygame框架实现推箱子游戏,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-11-11
这篇文章主要为大家详细介绍了python使用pygame框架实现推箱子游戏,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-11-11 这篇文章主要为大家详细介绍了python绘制多个曲线的折线图,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-09-09
这篇文章主要为大家详细介绍了python绘制多个曲线的折线图,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-09-09 在平常的代码中,我们常常需要与时间打交道,那么在Python中,与时间处理有关的模块就包括:time、datetime以及calendar,这篇文章主要给大家介绍了关于python标准库之time模块的语法与使用的相关资料,需要的朋友可以参考下2021-08-08
在平常的代码中,我们常常需要与时间打交道,那么在Python中,与时间处理有关的模块就包括:time、datetime以及calendar,这篇文章主要给大家介绍了关于python标准库之time模块的语法与使用的相关资料,需要的朋友可以参考下2021-08-08 这篇文章主要介绍了关于python 解决print数组/矩阵无法完整输出的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02
这篇文章主要介绍了关于python 解决print数组/矩阵无法完整输出的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02 这篇文章主要介绍了Python如何存储和读取ASCII码形式的byte数据,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-05-05
这篇文章主要介绍了Python如何存储和读取ASCII码形式的byte数据,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-05-05 这篇文章主要给大家介绍了关于python中turtle库的简单使用教程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-11-11
这篇文章主要给大家介绍了关于python中turtle库的简单使用教程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-11-11 大家知道“猜数字”这个游戏吗?顾名思义就是一个人想一个数字,另一个人猜。本文就来用Python实现一款不一样的猜数字游戏,感兴趣的可以了解一下2023-02-02
大家知道“猜数字”这个游戏吗?顾名思义就是一个人想一个数字,另一个人猜。本文就来用Python实现一款不一样的猜数字游戏,感兴趣的可以了解一下2023-02-02 这篇文章主要为大家介绍了Python进程和守护进程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2021-12-12
这篇文章主要为大家介绍了Python进程和守护进程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2021-12-12 下面小编就为大家分享一篇python去除扩展名的实例讲解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04
下面小编就为大家分享一篇python去除扩展名的实例讲解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04










最新评论