
ol7.7安装部署4节点spark3.0.0分布式集群的详细教程
更新时间:2020年07月10日 11:42:30 作者:九命猫幺
这篇文章主要介绍了安装部署4节点spark3.0.0分布式集群,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
为学习spark,虚拟机中开4台虚拟机安装spark3.0.0
底层hadoop集群已经安装好,见ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境
首先,去http://spark.apache.org/downloads.html下载对应安装包
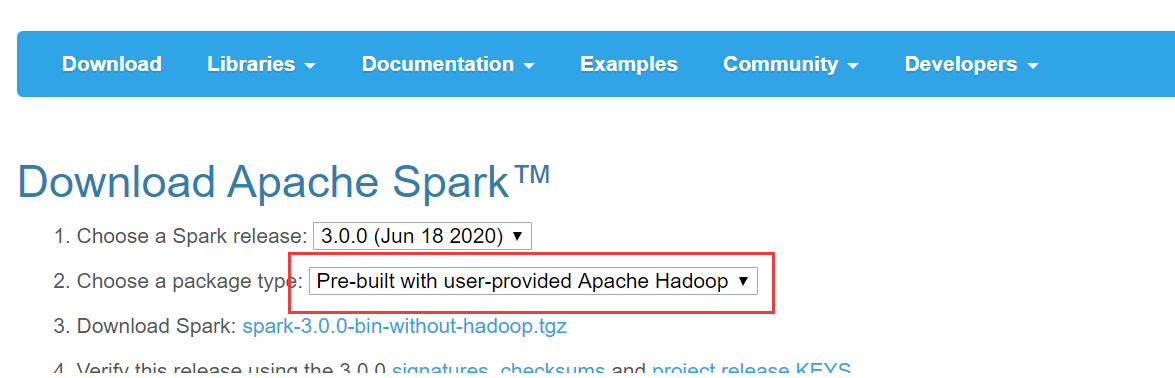
解压
[hadoop@master ~]$ sudo tar -zxf spark-3.0.0-bin-without-hadoop.tgz -C /usr/local [hadoop@master ~]$ cd /usr/local [hadoop@master /usr/local]$ sudo mv ./spark-3.0.0-bin-without-hadoop/ spark [hadoop@master /usr/local]$ sudo chown -R hadoop: ./spark
四个节点都添加环境变量
export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
配置spark
spark目录中的conf目录下cp ./conf/spark-env.sh.template ./conf/spark-env.sh后面添加
export SPARK_MASTER_IP=192.168.168.11 export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export SPARK_LOCAL_DIRS=/usr/local/hadoop export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
然后配置work节点,cp ./conf/slaves.template ./conf/slaves修改为
master
slave1
slave2
slave3
写死JAVA_HOME,sbin/spark-config.sh最后添加
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
复制spark目录到其他节点
sudo scp -r /usr/local/spark/ slave1:/usr/local/ sudo scp -r /usr/local/spark/ slave2:/usr/local/ sudo scp -r /usr/local/spark/ slave3:/usr/local/ sudo chown -R hadoop ./spark/
...
启动集群
先启动hadoop集群/usr/local/hadoop/sbin/start-all.sh
然后启动spark集群
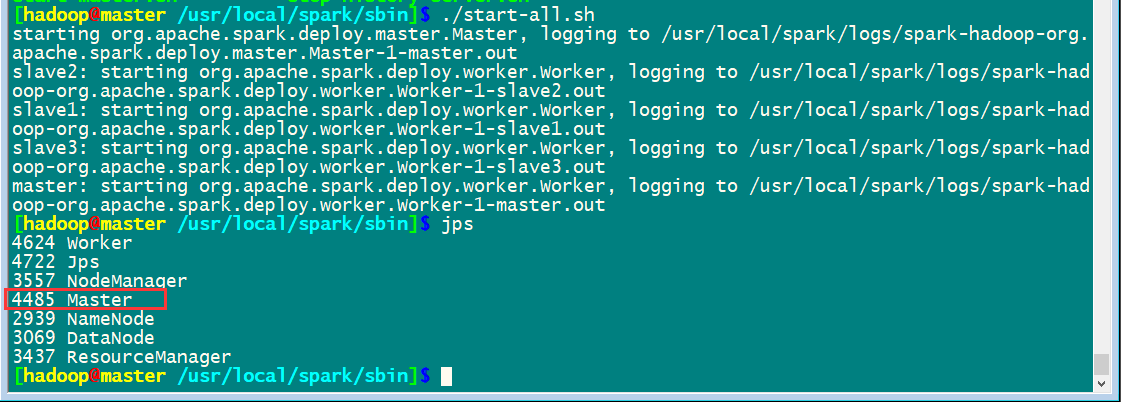
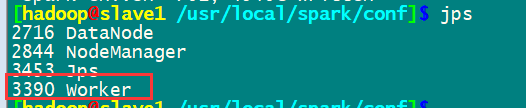
通过master8080端口监控
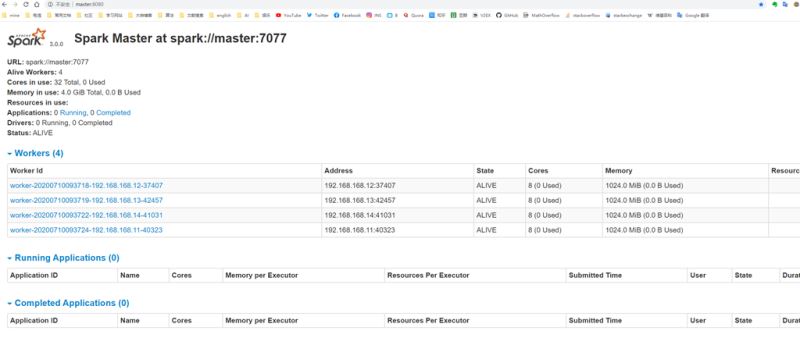
完成安装
到此这篇关于ol7.7安装部署4节点spark3.0.0分布式集群的详细教程的文章就介绍到这了,更多相关ol7.7安装部署spark集群内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了DVWA下载、安装、使用(漏洞测试环境搭建)的详细教程,本文通过图文并茂的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-10-10
这篇文章主要介绍了DVWA下载、安装、使用(漏洞测试环境搭建)的详细教程,本文通过图文并茂的形式给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-10-10 这篇文章主要介绍了grafana安装及使用教程详解,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01
这篇文章主要介绍了grafana安装及使用教程详解,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-01-01 这篇文章主要介绍了好玩的vbs小程序之关机功能,非常有趣,感兴趣的朋友跟随小编一起看看吧2019-09-09
这篇文章主要介绍了好玩的vbs小程序之关机功能,非常有趣,感兴趣的朋友跟随小编一起看看吧2019-09-09
MobaXterm连接服务器如何在关闭会话的情况下依然执行程序(最新推荐)
这篇文章主要介绍了MobaXterm连接服务器如何在关闭会话的情况下依然执行程序,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2023-06-06 这篇文章主要介绍了使用postman进行接口测试的方法(测试用户管理模块),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧2021-01-01
这篇文章主要介绍了使用postman进行接口测试的方法(测试用户管理模块),本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧2021-01-01 IP对大家来说应该再熟悉不过了,但其实IP地址有一些不为人知的事情,可能你并不知道。例如短IP、不同进制的ip等,所以下面这篇文章主要给大家总结介绍了一些你可能不知道的ip地址知识,需要的朋友可以参考借鉴,下面来一起看看吧。2017-07-07
IP对大家来说应该再熟悉不过了,但其实IP地址有一些不为人知的事情,可能你并不知道。例如短IP、不同进制的ip等,所以下面这篇文章主要给大家总结介绍了一些你可能不知道的ip地址知识,需要的朋友可以参考借鉴,下面来一起看看吧。2017-07-07 这篇文章主要为大家介绍了深度卷积神经网络各种改进结构块汇总,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05
这篇文章主要为大家介绍了深度卷积神经网络各种改进结构块汇总,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05 这篇文章主要介绍了OAuth 2.0授权协议详解,本文对OAuth协议做了详解讲解,对OAuth协议的各个方面做了分解,读完本文你就会知道到底啥是OAuth了,需要的朋友可以参考下2014-09-09
这篇文章主要介绍了OAuth 2.0授权协议详解,本文对OAuth协议做了详解讲解,对OAuth协议的各个方面做了分解,读完本文你就会知道到底啥是OAuth了,需要的朋友可以参考下2014-09-09
多种语言(big5\gbk\gb2312\utf8\Shift_JIS\iso8859-1)的网页编码切换解决方案归纳
多种语言(big5\gbk\gb2312\utf8\Shift_JIS\iso8859-1)的网页编码切换解决方案归纳2012-06-06
如何集成Elasticsearch到django restful
在Django项目中集成Elasticsearch可通过Haystack实现,Haystack作为Django插件提供搜索接口,Elasticsearch作为后端搜索引擎存储检索数据,Haystack支持多种搜索引擎,易于切换且不需改动代码,本文给大家介绍如何集成Elasticsearch到django restful,感兴趣的朋友一起看看吧2024-09-09










最新评论