
Python实现爬取网页中动态加载的数据
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中,无法抓取动态加载的可用数据。例如,获取某网页中,商品价格时就会出现此类现象。如下图所示。本文将实现爬取网页中类似的动态加载的数据。
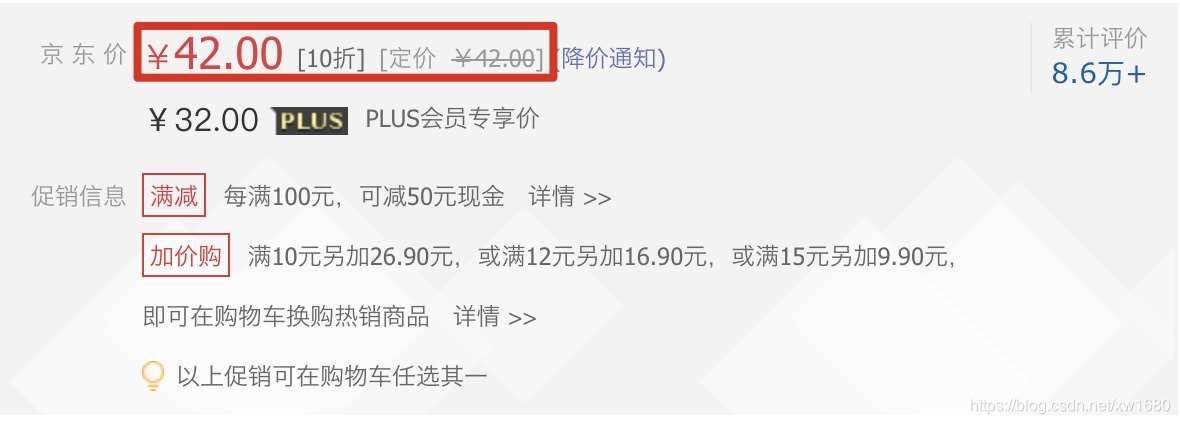
1. 那么什么是动态加载的数据?
我们通过requests模块进行数据爬取无法每次都是可见即可得,有些数据是通过非浏览器地址栏中的url请求得到的。而是通过其他请求请求到的数据,那么这些通过其他请求请求到的数据就是动态加载的数据。(猜测有可能是js代码当咱们访问此页面时就会发送得get请求,到其他url中获取数据)
2. 如何检测网页中是否存在动态加载得数据?
在当前页面中打开抓包工具,捕获到地址栏中的url对应的数据包,在该数据包的response选项卡搜索我们想要爬取的数据,如果搜索到了结果则表示数据不是动态加载的,否则表示数据为动态加载的。如图所示:
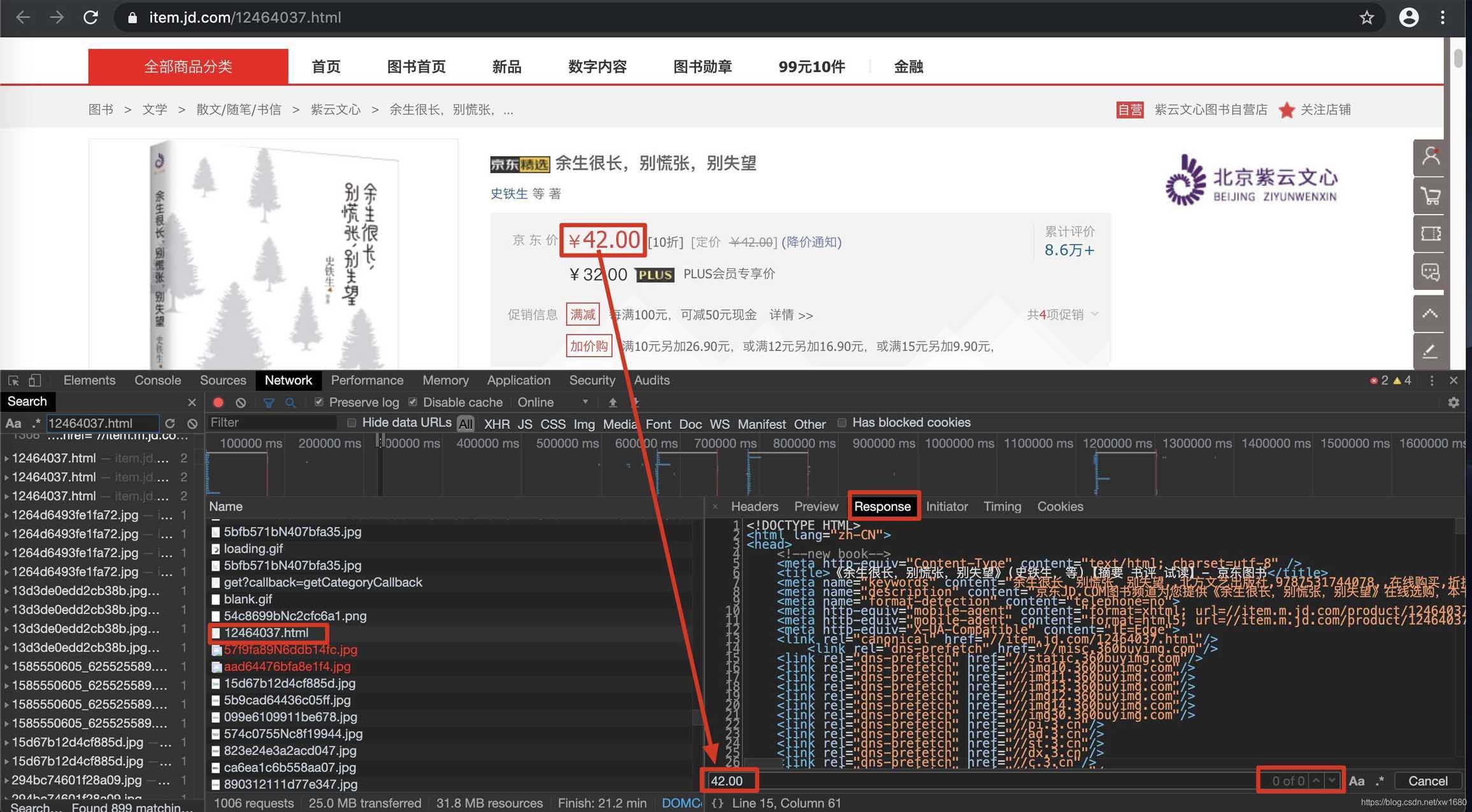
或者鼠标右键单击要爬取的页面显示网页源代码搜索我们想要爬取的数据,如果搜索到了结果则表示数据不是动态加载的,否则表示数据为动态加载的。如图所示:

3. 如果数据为动态加载,那么我们如何捕获到动态加载的数据?
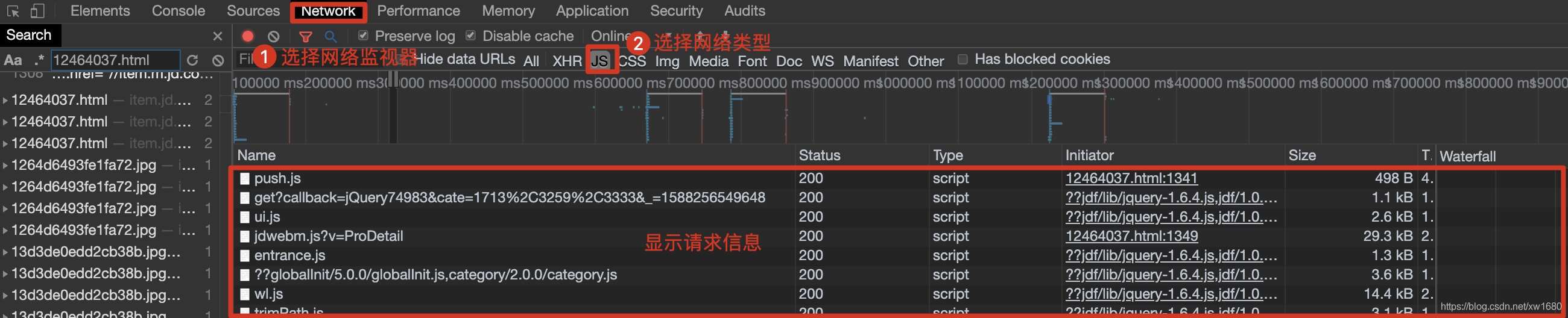
在实现爬取动态加载的数据信息时,首先需要在浏览器的网络监视器中根据动态加载的技术选择网络请求的类型,然后通过逐个筛选的方式查询预览信息中的关键数据,并获取对应的请求地址,最后进行信息的解析工作即可。具体步骤如下:
在浏览器中快捷键F12打开开发者工具,然后选择Network(网络监视器)并在网络类型中选择JS,再按快捷键F5刷新,如下图所示。
在请求信息的列表中,依次单击每个请求信息,然后在对应的Preview(请求结果预览)中核对是否为需要获取的动态加载数据,如下图所示。
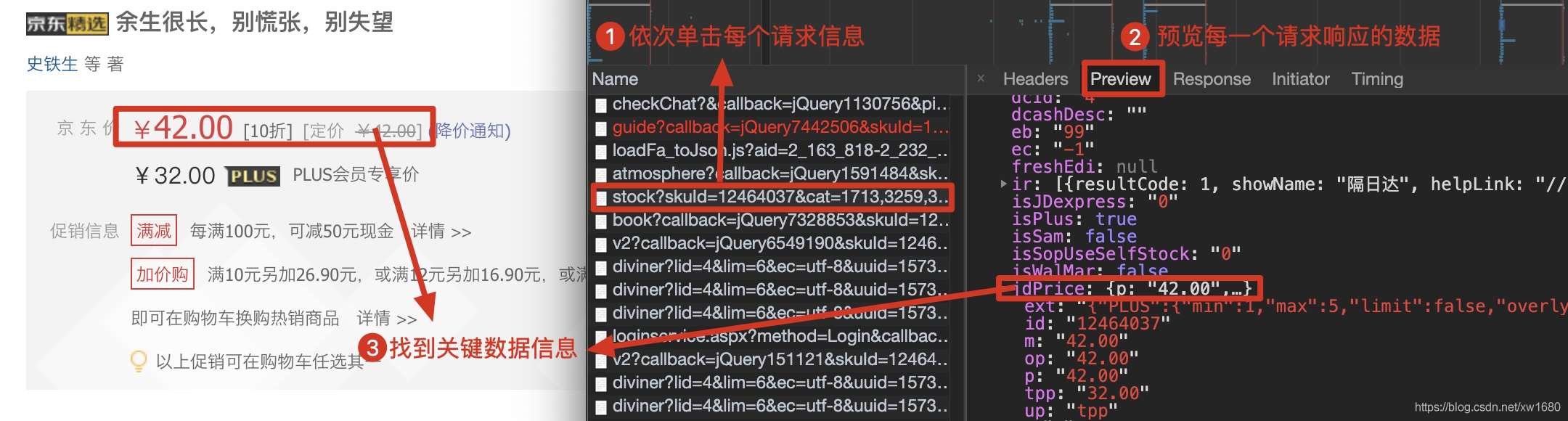
动态加载的数据信息核对完成后,单击Headers获取当前的网络请求地址以及所需参数,如下图所示。
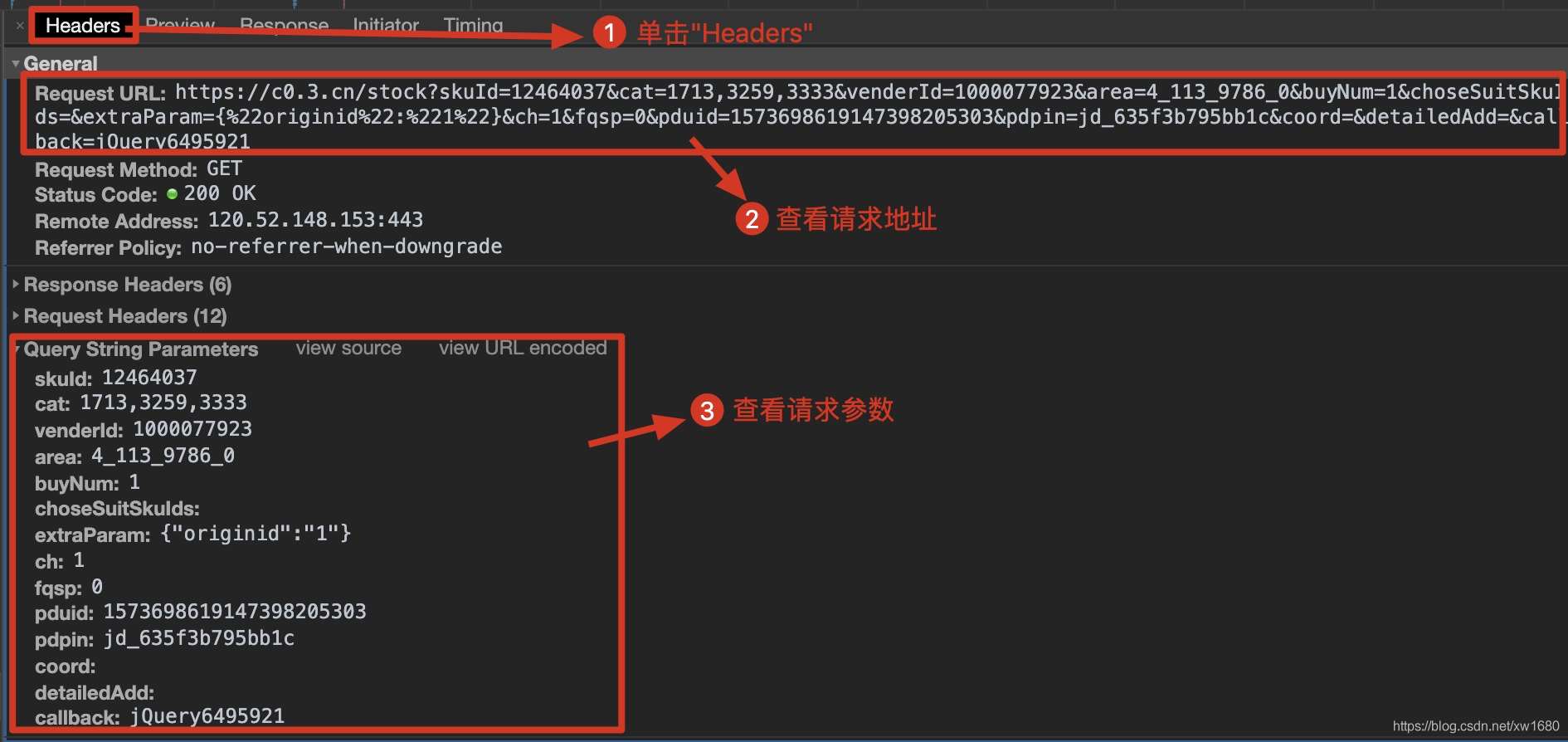
根据以上步骤获取到的请求地址,发送网络请求并从返回的信息中提取商品价格信息。笔者在代码中使用到了反序列化,关于json序列化和反序列化可以点击 此处 进行学习,代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
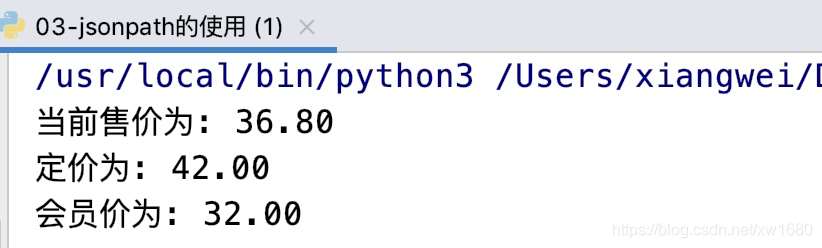
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
笔者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载数据信息时,需要根据不同的网页使用不同的方式进行数据的提取。如果在运行源码时出现了错误,请根据操作步骤获取新的请求地址即可。
到此这篇关于Python实现爬取网页中动态加载的数据的文章就介绍到这了,更多相关Python 爬取网页动态数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 在本篇文章中小编给各位分享的是关于python中append实例用法以及相关知识点,需要的朋友们可以学习下。2019-07-07
在本篇文章中小编给各位分享的是关于python中append实例用法以及相关知识点,需要的朋友们可以学习下。2019-07-07
基于Tensorflow读取MNIST数据集时网络超时的解决方式
这篇文章主要介绍了基于Tensorflow读取MNIST数据集时网络超时的解决方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 今天小编就为大家分享一篇关于Opencv+Python实现图像运动模糊和高斯模糊的示例,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-04-04
今天小编就为大家分享一篇关于Opencv+Python实现图像运动模糊和高斯模糊的示例,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-04-04 下面小编就为大家带来一篇定制FileField中的上传文件名称实例。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-08-08
下面小编就为大家带来一篇定制FileField中的上传文件名称实例。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-08-08
python中的getattribute 、getattr、setattr方法详解
这篇文章主要介绍了python中的getattribute 、getattr、setattr方法详解,python类中默认有一些特殊方法,这篇文章记录一下特殊方法的功能及用法,需要的朋友可以参考下2023-11-11 这篇文章主要为大家详细介绍了基于Python3 OpenCV3实现静态图片人脸识别,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-05-05
这篇文章主要为大家详细介绍了基于Python3 OpenCV3实现静态图片人脸识别,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-05-05 对于相册播放器,大家应该都不陌生(用于浏览多张图片的一个应用)。本文将利用Python编写一个简单的相册播放器,感兴趣的可以学习一下2022-06-06
对于相册播放器,大家应该都不陌生(用于浏览多张图片的一个应用)。本文将利用Python编写一个简单的相册播放器,感兴趣的可以学习一下2022-06-06 本文给大家通过实例和原理深入分析了python中整型不会溢出的相关知识点,有兴趣的朋友可以跟着学习下。2018-06-06
本文给大家通过实例和原理深入分析了python中整型不会溢出的相关知识点,有兴趣的朋友可以跟着学习下。2018-06-06 下面小编就为大家带来一篇Python之re操作方法(详解)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-06-06
下面小编就为大家带来一篇Python之re操作方法(详解)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-06-06 pgu全称是Phil’s pyGame Utilities,是pygame的一组模块与脚本,其中还有gui集成了一些小模块,现在用pygame制作小游戏的人越来越多,但是pygame它是没有弹窗机制的,今天通过本文给大家介绍pygame库pgu使用示例代码,需要的朋友参考下吧2021-08-08
pgu全称是Phil’s pyGame Utilities,是pygame的一组模块与脚本,其中还有gui集成了一些小模块,现在用pygame制作小游戏的人越来越多,但是pygame它是没有弹窗机制的,今天通过本文给大家介绍pygame库pgu使用示例代码,需要的朋友参考下吧2021-08-08










最新评论