
Python描述数据结构学习之哈夫曼树篇
前言
本篇章主要介绍哈夫曼树及哈夫曼编码,包括哈夫曼树的一些基本概念、构造、代码实现以及哈夫曼编码,并用Python实现。
1. 基本概念
哈夫曼树

其中,
带权路径长度是带权结点和根结点之间的路径长度与该结点的权值的乘积。有关带权结点、路径长度的概念请参阅这篇博客。
对于含有
2. 构造过程及实现
给定
比如

代码实现:
class HuffmanTreeNode(object): def __init__(self): self.data = '#' self.weight = -1 self.parent = None self.lchild = None self.rchild = None class HuffmanTree(object): def __init__(self, data_list): self.nodes = [] # 按权重从大到小进行排列 for val in data_list: newnode = HuffmanTreeNode() newnode.data = val[0] newnode.weight = val[1] self.nodes.append(newnode) self.nodes = sorted(self.nodes, key=lambda node: node.weight, reverse=True) print([(node.data, node.weight) for node in self.nodes]) def CreateHuffmanTree(self): # 这里注意区分 # TreeNode = self.nodes[:] 变量TreeNode, 这个相当于深拷贝, TreeNode变化不影响nodes # TreeNode = self.nodes 指针TreeNode与nodes共享一个地址, 相当于浅拷贝, TreeNode变化会影响nodes TreeNode = self.nodes[:] if len(TreeNode) > 0: while len(TreeNode) > 1: letfTreeNode = TreeNode.pop() rightTreeNode = TreeNode.pop() newNode = HuffmanTreeNode() newNode.lchild = letfTreeNode newNode.rchild = rightTreeNode newNode.weight = letfTreeNode.weight + rightTreeNode.weight letfTreeNode.parent = newNode rightTreeNode.parent = newNode self.InsertTreeNode(TreeNode, newNode) return TreeNode[0] def InsertTreeNode(self, TreeNode, newNode): length = len(TreeNode) if length > 0: temp = length - 1 while temp >= 0: if newNode.weight < TreeNode[temp].weight: TreeNode.insert(temp+1, newNode) return True temp -= 1 TreeNode.insert(0, newNode)
3. 哈夫曼编码
在数据通信时,假如我们要发送
| A | B | C | D | E | F | G | |
|---|---|---|---|---|---|---|---|
| 固定长度编码 | 000 | 001 | 010 | 011 | 100 | 101 | 110 |
| 可变长度编码 | 0 | 1 | 01 | 10 | 11 | 101 | 110 |
报文最短可以引申到二叉树路径最短,即构造前缀编码的实质就是构造一棵哈夫曼树,通过这种形式获得的二进制编码称为哈夫曼编码。这里的权值就是报文中字符出现的概率,出现概率越高的字符我们用越短的字符表示。
以下表中的字符及其出现的概率为例来实现哈夫曼编码:
| 字符 | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| 出现概率 | 0.01 | 0.43 | 0.15 | 0.02 | 0.03 | 0.21 | 0.07 | 0.08 |
| 哈夫曼编码 | 101010 | 0 | 110 | 101011 | 10100 | 111 | 1011 | 100 |
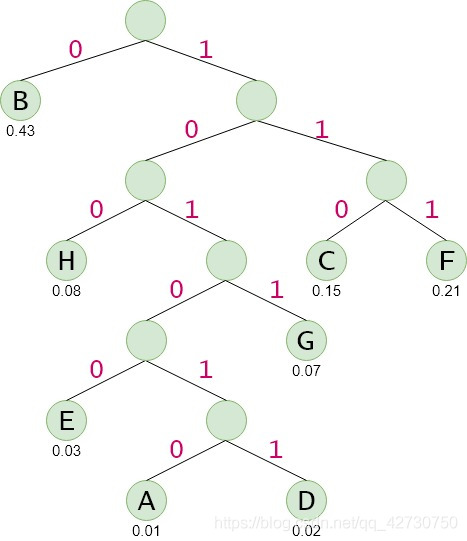
代码实现就是在哈夫曼树的基础上加一个编码的函数:
def HuffmanEncode(self, Root):
TreeNode = self.nodes[:]
code_result = []
for index in range(len(TreeNode)):
temp = TreeNode[index]
code_leaf = [temp.data]
code = ''
while temp is not Root:
if temp.parent.lchild is temp:
# 左分支
code = '0' + code
else:
# 右分支
code = '1' + code
temp = temp.parent
code_leaf.append(code)
code_result.append(code_leaf)
return code_result
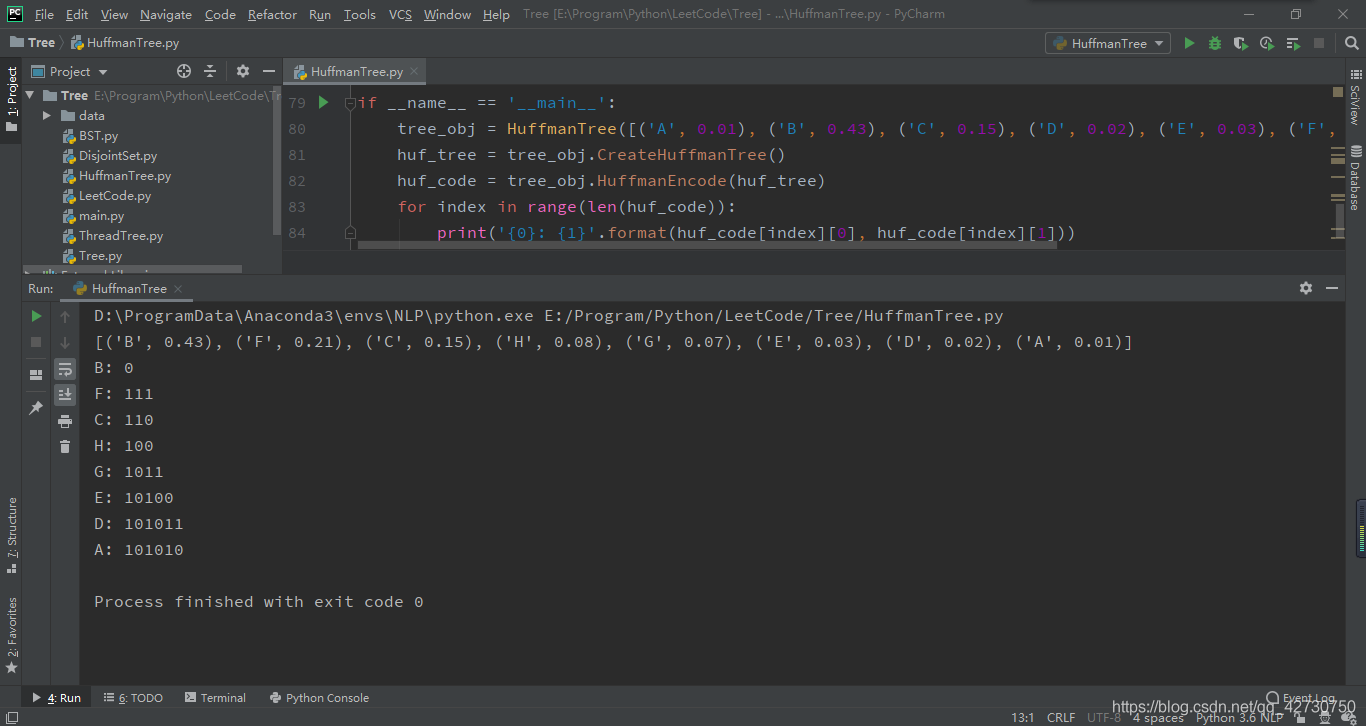
测试结果如下:
if __name__ == '__main__':
tree_obj = HuffmanTree([('A', 0.01), ('B', 0.43), ('C', 0.15), ('D', 0.02), ('E', 0.03), ('F', 0.21), ('G', 0.07), ('H', 0.08)])
huf_tree = tree_obj.CreateHuffmanTree()
huf_code = tree_obj.HuffmanEncode(huf_tree)
for index in range(len(huf_code)):
print('{0}: {1}'.format(huf_code[index][0], huf_code[index][1]))
总结
到此这篇关于Python描述数据结构学习之哈夫曼树篇的文章就介绍到这了,更多相关Python数据结构之哈夫曼树内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

python模块详解之pywin32使用文档(python操作windowsAPI)
pywin32是一个第三方模块库,主要的作用是方便python开发者快速调用windows API的一个模块库,这篇文章主要给大家介绍了关于python模块详解之pywin32使用文档的相关资料,文中将python操作windowsAPI介绍的非常详细,需要的朋友可以参考下2024-01-01 前面一篇文章中提到的那个程序,GUI中包含了一张图片。在编译成exe文件发布时,无法直接生成一个单独的exe文件。因此需要直接把图片写入到代码中2014-08-08
前面一篇文章中提到的那个程序,GUI中包含了一张图片。在编译成exe文件发布时,无法直接生成一个单独的exe文件。因此需要直接把图片写入到代码中2014-08-08 这篇文章主要介绍了Pytorch定义的网络结构层能否重复使用的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06
这篇文章主要介绍了Pytorch定义的网络结构层能否重复使用的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06
基于matplotlib中ion()和ioff()的使用详解
这篇文章主要介绍了基于matplotlib中ion()和ioff()的使用详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 这篇文章主要为大家详细介绍了基于python实现图书管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-04-04
这篇文章主要为大家详细介绍了基于python实现图书管理系统,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-04-04 这篇文章主要给大家分享了关于Flask 上下文详细介绍,我们可以把上下文理解为当前环境的快照,是一个用来保存状态的对象。在代码执行的某个时刻,根据上下文的代码逻辑,可以决定在当前时刻下使用到的环境变量等。下面一起进入文章了解详情内容,需要的朋友也可以参考一下2021-11-11
这篇文章主要给大家分享了关于Flask 上下文详细介绍,我们可以把上下文理解为当前环境的快照,是一个用来保存状态的对象。在代码执行的某个时刻,根据上下文的代码逻辑,可以决定在当前时刻下使用到的环境变量等。下面一起进入文章了解详情内容,需要的朋友也可以参考一下2021-11-11
pytest使用parametrize将参数化变量传递到fixture
这篇文章主要为大家介绍了pytest使用parametrize将参数化变量传递到fixture的使用详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2022-05-05 这篇文章主要给大家介绍了关于Python导入或执行python源文件的3种方法,python源代码的文件以"py"为扩展名,由python.exe解释,可以在控制台下运行,需要的朋友可以参考下2023-08-08
这篇文章主要给大家介绍了关于Python导入或执行python源文件的3种方法,python源代码的文件以"py"为扩展名,由python.exe解释,可以在控制台下运行,需要的朋友可以参考下2023-08-08 这篇文章主要介绍了Python NumPy创建数组方法,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的朋友可以参考一下2022-09-09
这篇文章主要介绍了Python NumPy创建数组方法,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的朋友可以参考一下2022-09-09
Python中的JSON Pickle Shelve模块特性与区别实例探究
在Python中,处理数据序列化和持久化是极其重要的,JSON、Pickle和Shelve是三种常用的模块,它们提供了不同的方法来处理数据的序列化和持久化,本文将深入研究这三个模块,探讨它们的特性、用法以及各自的优缺点2024-01-01










最新评论