
Mysql误删数据解决方案及kill语句原理
mysql误删数据
- 使用delete语句误删数据行
- 使用drop table或者truncate table误删数据表
- 使用drop database语句误删数据库
- 使用rm误删mysql整个实例
对于误删行
- 使用flashback工具闪回,把数据恢复回来。原理是修改binlog的内容,拿回原库重放,需要确保binlog_format=row和binlog_row_imsge=Full
- 具体恢复时
- 如果是insert,将binlog event类型是write_rows event改为delete_rows event。
- 如果是delete则相反。
- 如果是update,binlog里有数据修改前和修改后的值,对调这两行即可。
- 多个事物也是按照以上原则倒叙执行。
- 预防:把sql_safe_updates参数设置为on。这样一来,如果我们忘记在delete或者update语句中写where条件,或者where条件里面没有包含索引字段的话,这条语句的执行就会报错。
对于误删库/表
需要使用全量备份,加增量日志的方式。要求线上有定期的全量备份吗,并且实时备份binlog。
假如有人中午12点误删了一个库,恢复数据的流程如下:
取最近一次全量备份,假设这个库是一天一备,上次备份是当天0点;
用备份恢复出一个临时库;
从日志备份里面,取出凌晨0点之后的日志
把这些日志,除了误删除数据的语句外,全部应用到临时库。

注意:
为了加速数据恢复,如果这个临时库上有多个数据库,你可以在使用mysqlbinlog命令时,加上一个–database参数,用来指定误删表所在的库。这样,就避免了在恢复数据时还要应用其他库日志的情况。
在应用日志的时候,需要跳过12点误操作的那个语句的binlog:
加速恢复的方法:备份恢复出临时实例之后,将这个临时实例设置成线上备库的从库,
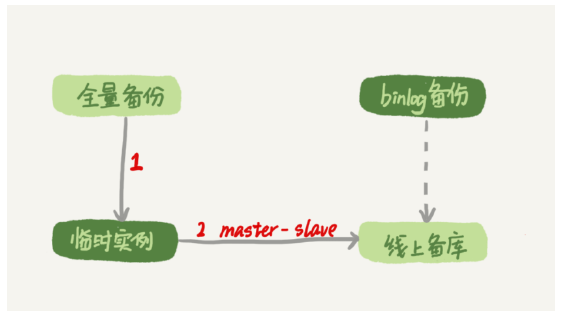
一个系统不可能备份无限的日志,你还需要根据成本和磁盘空间资源,设定一个日志保留
的天数。如果你的DBA团队告诉你,可以保证把某个实例恢复到半个月内的任意时间点,这就表示备份系统保留的日志时间就至少是半个月。
虽然“发生这种事,大家都不想的”,但是万一出现了误删事件,能够快速恢复数据,将损失
降到最小,也应该不用跑路了。而如果临时再手忙脚乱地手动操作,最后又误操作了,对业务造成了二次伤害,那就说不过去了。
延迟复制备库
- 如果一个库的备份特别大,或者误操作的时间距离上一个全量备份的时间较长,比如一周一备的实例,在备份之后的第6天发生误操作,那就需要恢复6天的日志,这个恢复时间可能是要按天来计算的。
- 延迟复制的备库是一种特殊的备库,通过 CHANGE MASTER TO MASTER_DELAY = N命令,可以指定这个备库持续保持跟主库有N秒的延迟。
- 比如你把N设置为3600,这就代表了如果主库上有数据被误删了,并且在1小时内发现了这个误操作命令,这个命令就还没有在这个延迟复制的备库执行。这时候到这个备库上执行stopslave,再通过之前介绍的方法,跳过误操作命令,就可以恢复出需要的数据。
对于rm删除数据
只要不是恶意地把整个集群删除,而只是删掉了其中某一个节点的数据的话,HA系统就会开始工作,选出一个新的主库,从而保证整个集群的正常工作。这时,你要做的就是在这个节点上把数据恢复回来,再接入整个集群。
当然了,现在不止是DBA有自动化系统,SA(系统管理员)也有自动化系统,所以也许一个批量下线机器的操作,会让你整个MySQL集群的所有节点都全军覆没。应对这种情况,我的建议只能是说尽量把你的备份跨机房,或者最好是跨城市保存。Kill sql语句

session B是直接终止掉线程,什么都不管就直接退出吗?显然,这是不行的。
当对一个表做增删改查操作时,会在表上加MDL读锁。所以,session B虽然处于blocked状态,但还是拿着一个MDL读锁的。如果线程被kill的时候,就直接终止,那之后这个MDL读锁就没机会被释放了。
kill并不是马上停止的意思,而是告诉执行线程说,这条语句已经不需要继续执行了,可以开始“执行停止的逻辑了”。
实际上,当执行kill query thread_id_b,mysql里处理kill命令的线程做了以下事情:
- 把session B的运行状态改为了THD::KILL_QUERY
- 给session B的执行线程发了一个信号。
因为像图1的我们例子里面,session B处于锁等待状态,如果只是把session B的线程状态设置
THD::KILL_QUERY,线程B并不知道这个状态变化,还是会继续等待。发一个信号的目的,就
是让session B退出等待,来处理这个THD::KILL_QUERY状态。
以上包含了三层意思:
- 一个语句执行过程中有多处埋点,在这些“埋点”的地方判断线程状态,如果发现线程状态
- 是THD::KILL_QUERY,才开始进入语句终止逻辑;
- 如果处于等待状态,必须是一个可以被唤醒的等待,否则根本不会执行到“埋点”处;
- 语句从开始进入终止逻辑,到终止逻辑完全完成,是有一个过程的。
一个kill不掉的例子
执行set global innodb_thread_concurrency=2,将InnoDB的并发线程上限数设置为2;然后,执行下面的序列:

可以看到:
sesssion C执行的时候被堵住了;
但是session D执行的kill query C命令却没什么效果,
直到session E执行了kill connection命令,才断开了session C的连接,提示“Lost connection to MySQL server during query”,
但是这时候,如果在session E中执行show processlist,你就能看到下面这个图:
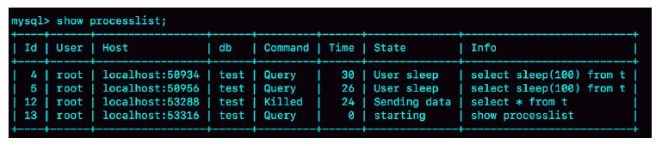
id=12这个线程的Commnad列显示的是Killed。也就是说,客户端虽然断开了连接,但实际上服务端上这条语句还在执行过程中。
在这个例子里,12号线程的等待逻辑是这样的:每10毫秒判断一下是否可以进入InnoDB执
行,如果不行,就调用nanosleep函数进入sleep状态。
也就是说,虽然12号线程的状态已经被设置成了KILL_QUERY,但是在这个等待进入InnoDB的循环过程中,并没有去判断线程的状态,因此根本不会进入终止逻辑阶段。
而当session E执行kill connection 命令时,是这么做的,
- 把12号线程状态设置为KILL_CONNECTION;
- 关掉12号线程的网络连接。因为有这个操作,所以你会看到,这时候session C收到了断开连接的提示。
那为什么执行show processlist的时候,会看到Command列显示为killed呢?其实,这就是因为在执行show processlist的时候,有一个特别的逻辑:
如果一个线程的状态是KILL_CONNECTION,就把Command列显示成Killed。
所以其实,即使是客户端退出了,这个线程的状态仍然是在等待中。只有等到满足进入InnoDB的条件后,session C的查询语句继续执行,然后才有可能判断到线程状态已经变成了KILL_QUERY或者KILL_CONNECTION,再进入终止逻辑阶段。
kill无效的第一类情况,即:线程没有执行到判断线程状态的逻辑。可能也会由于IO压力过大,读写IO的函数一直无法返回,导致不能及时判断线程的状态。
- 第二类情况,终止逻辑耗时较长
- 超大事物执行期间被kill,回滚操作耗时很长。
- 大会滚操作,比如查询过程中生成了很大的临时文件,删除临时文件需要等待IO资源,导致耗时较长。
- DDL执行到最后阶段,如果被kill,需要删除中间过程的临时文件,也需要IO资源。
ctrl+C,mysql实际上也是启动了一个连接进程发送了kill query命令。
关于客户端连接慢的误解
如果库里面的表很多,连接就会很慢。比如有一个库有上万个表,使用默认参数连接的时候,mysql会提供一个本地库名和表名补全的功能:
- 执行show databases
- 切到db1,执行show tables
- 把这两个命令的结果用于构建一个本地hash表。
第三步是耗时比较长的操作,也就是我们感知到慢不是连接满,也不是服务端慢,而是客户端慢。如果在这个连接中加上 -A,就可以取消自动补全功能,很快返回。
自动补全的效果就是,在输入库名或者表名的时候,将输入前缀,可以使用tab自动补全或者显示提示。实际如果自动补全用的不多,可以每次使用都加-A。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 这篇文章主要介绍了MySQL OOM 系列三 摆脱MySQL被Kill的厄运 ,需要的朋友可以参考下2016-07-07
这篇文章主要介绍了MySQL OOM 系列三 摆脱MySQL被Kill的厄运 ,需要的朋友可以参考下2016-07-07 在MySQL中,判断字符串字段是否包含特定子字符串,可使用LIKE操作符、INSTR()函数、LOCATE()函数、POSITION()函数、FIND_IN_SET()函数以及正则表达式REGEXP或RLIKE,每种方法适用于不同的场景和需求,LIKE和INSTR()通常用于简单包含判断2024-09-09
在MySQL中,判断字符串字段是否包含特定子字符串,可使用LIKE操作符、INSTR()函数、LOCATE()函数、POSITION()函数、FIND_IN_SET()函数以及正则表达式REGEXP或RLIKE,每种方法适用于不同的场景和需求,LIKE和INSTR()通常用于简单包含判断2024-09-09 本文介绍一下关于mysql获取字符串长度的方法,希望此教程对各位同学会有所帮助哦。2013-11-11
本文介绍一下关于mysql获取字符串长度的方法,希望此教程对各位同学会有所帮助哦。2013-11-11 这篇文章主要介绍了MySQL 数据库范式设计理论总结,数据库的规划化范式设计,在逻辑结构上可以让结构更加细粒度,容易理解,下文我们就来了解具体的内容介绍吧2022-04-04
这篇文章主要介绍了MySQL 数据库范式设计理论总结,数据库的规划化范式设计,在逻辑结构上可以让结构更加细粒度,容易理解,下文我们就来了解具体的内容介绍吧2022-04-04 这篇文章主要为大家详细介绍了mac下mysql5.7.20 安装配置方法图文教程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-11-11
这篇文章主要为大家详细介绍了mac下mysql5.7.20 安装配置方法图文教程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-11-11 本文主要介绍了MySQL日期时间加减,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-09-09
本文主要介绍了MySQL日期时间加减,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-09-09 本文总结了30个mysql千万级大数据SQL查询优化技巧,特别适合大数据里的MYSQL使用2018-03-03
本文总结了30个mysql千万级大数据SQL查询优化技巧,特别适合大数据里的MYSQL使用2018-03-03 ADODB 入门...2006-12-12
ADODB 入门...2006-12-12
driver-class-name: com.mysql.jdbc.Driver爆红的问题解决
在springboot项目工程中想要进行数据库配置,driver-class-name: com.mysql.cj.jdbc.Driver始终报错,本文就来介绍一下如何解决,感兴趣的可以了解一下2024-07-07 今天小编就为大家分享一篇关于Mysql5.6修改root密码教程,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-02-02
今天小编就为大家分享一篇关于Mysql5.6修改root密码教程,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2019-02-02










最新评论