
python使用requests库爬取拉勾网招聘信息的实现
更新时间:2020年11月20日 14:44:10 作者:周少钦
这篇文章主要介绍了python使用requests库爬取拉勾网招聘信息的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
按F12打开开发者工具抓包,可以定位到招聘信息的接口
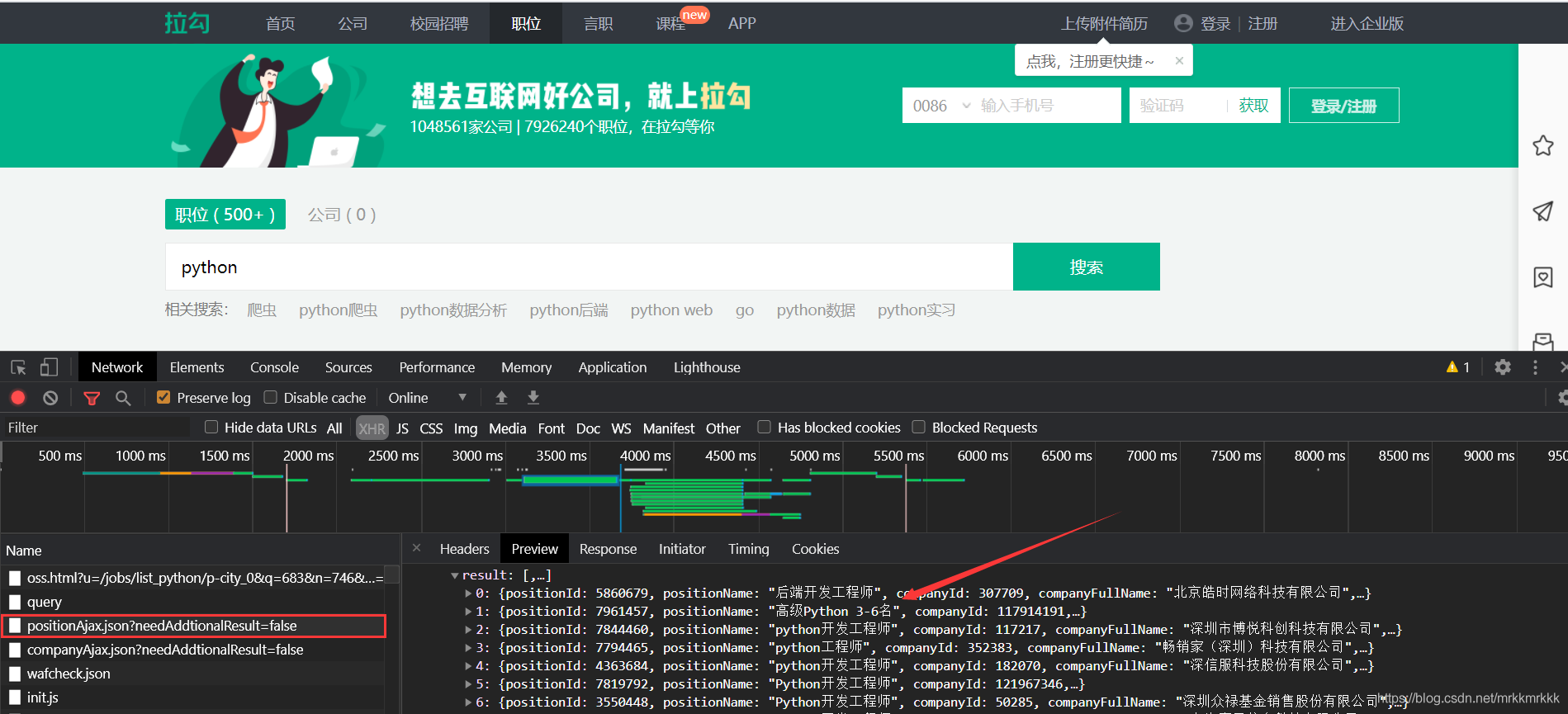
在请求中可以获取到接口的url和formdata,表单中pn为请求的页数,kd为关请求职位的关键字
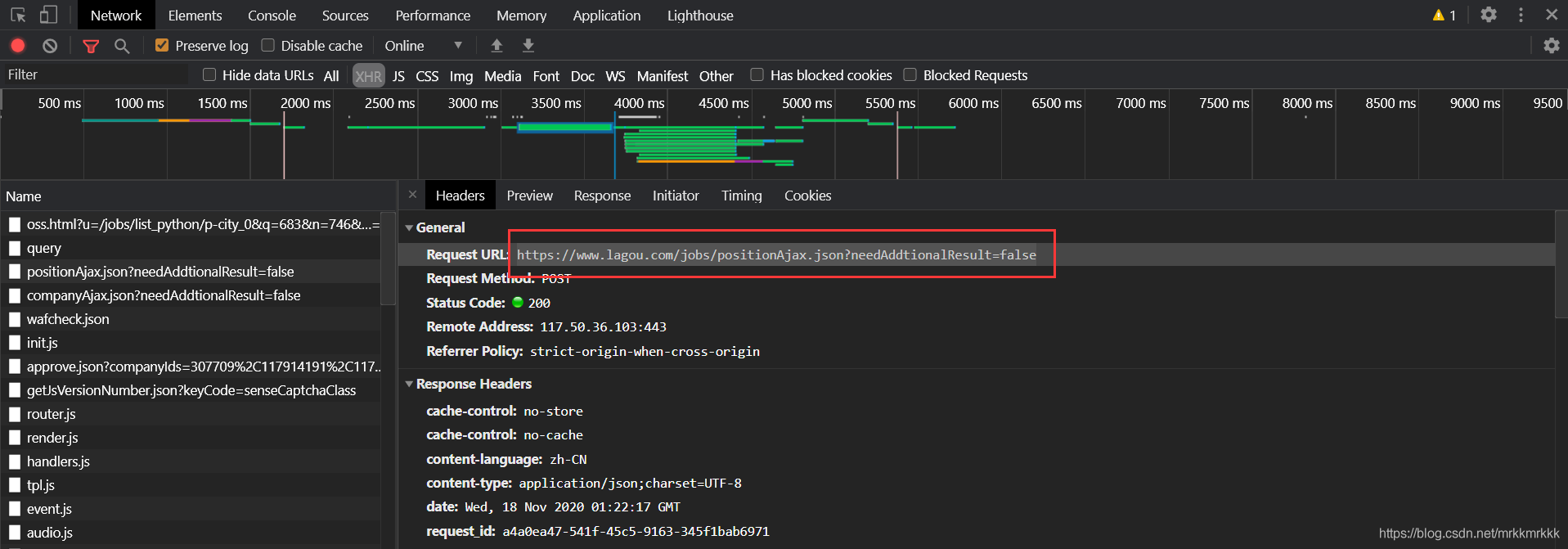
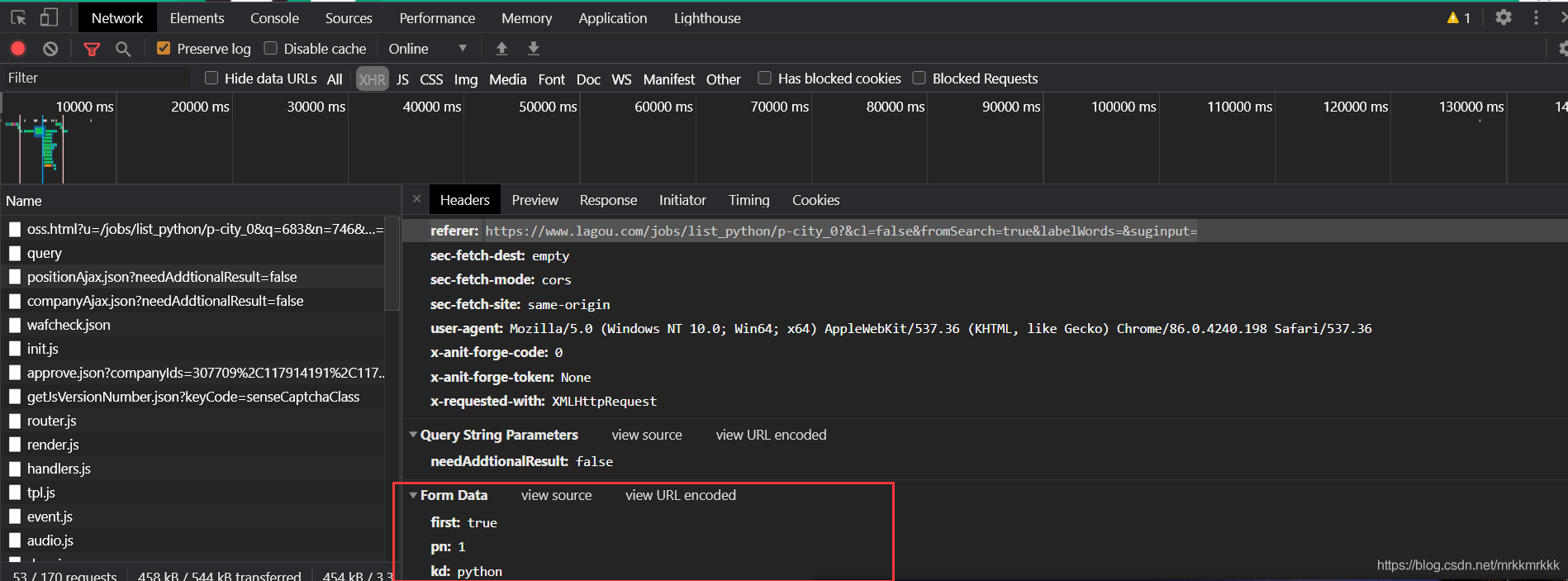
使用python构建post请求
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
headers = {
'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
res = requests.post("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false", data=data,headers=headers)
print(res.text)
发现没有从接口获取到数据

换了个网络后接口还是会返回操作频繁的错误信息,仔细检查后发现这个接口需要一个动态的cookies不然会一值返回错误频繁
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
#头部中必须有user-agent和referer不然不会返回cookies
headers = {
'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
#通过访问主页获取cookies
r1= requests.get("https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='",headers=headers)
#再post请求中传入cookies
r2 = requests.post("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false", data=data,headers=headers, cookies=r2.cookies)
print(r2.text)
注意!每请求十次接口cookies也会刷新一次,下面贴上完整爬虫代码
import json
import logging
import requests
#获取cookie
def getCookie():
res = requests.get("https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=",
headers=headers)
return res.cookies
#获取json数据
def getPage(i, cookies, kw):
data = {
'first': 'true',
'pn': i,
'kd': kw
}
res = requests.post("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false", data=data,
headers=headers, cookies=cookies)
return json.loads(res.text)
#合并列表
def reduceList(l):
text = ""
for i in l:
text += i + " "
return text.strip()
#提取字段并保存到文件中
def saveInCsv(f, data):
js = data["content"]["positionResult"]["result"]
for node in js:
# 对空值进行处理
district = node["district"]
if district != None:
district = "-" + district
else:
district = ""
f.write(
node["positionName"] + "·" + node["city"] + district + "·" + node[
"salary"] + "·" +
node["workYear"] + "·" + node["education"] + "·" + reduceList(node["skillLables"]) + "·" +
node["companyShortName"] + "·" + node["companySize"] + "·" + node["positionAdvantage"] + "\n")
if __name__ == '__main__':
#定义头部
headers = {
'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
#初始化cookie
cookies = getCookie()
with open("file.csv", "w", encoding="utf-8") as f:
for i in range(1, 31):
#每十个请求重新获取cookie
if (i % 10 == 0):
cookies = getCookie()
#解析字段并存储
data = getPage(i, cookies, "python")
saveInCsv(f, data)
到此这篇关于python使用requests库爬取拉勾网招聘信息的实现的文章就介绍到这了,更多相关python requests爬取拉勾网内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python删除字符串中字符的四种方法,本文通过示例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-12-12
这篇文章主要介绍了Python删除字符串中字符的四种方法,本文通过示例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-12-12 今天小编就为大家分享一篇Python任意字符串转16, 32, 64进制的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-06-06
今天小编就为大家分享一篇Python任意字符串转16, 32, 64进制的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-06-06 这篇文章主要介绍了Python3.9新特性详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-10-10
这篇文章主要介绍了Python3.9新特性详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-10-10 python 判断自定义对象类型 判断内建的类型可以用type。2009-03-03
python 判断自定义对象类型 判断内建的类型可以用type。2009-03-03 这篇文章主要介绍了Django ORM 事务和查询优化,包括事务操作、ORM 惰性查询及only与defer相关知识,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-09-09
这篇文章主要介绍了Django ORM 事务和查询优化,包括事务操作、ORM 惰性查询及only与defer相关知识,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-09-09 这篇文章主要给大家介绍了关于Jupyter Notebook界面汉化的相关资料,设置成中文界面后非常利于操作,文中介绍的方法非常简单,需要的朋友可以参考下2023-09-09
这篇文章主要给大家介绍了关于Jupyter Notebook界面汉化的相关资料,设置成中文界面后非常利于操作,文中介绍的方法非常简单,需要的朋友可以参考下2023-09-09 这篇文章主要介绍了Python内置加密模块用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11
这篇文章主要介绍了Python内置加密模块用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-11-11 这篇文章主要介绍了python 通过手机号识别出对应的微信性别,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了python 通过手机号识别出对应的微信性别,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下2019-12-12 最近线上运行的一个python任务负责处理一批数据,为提高处理效率,使用了python进程池,并会打印log,本文给大家分析了Python进程池log死锁问题以及解决方法,需要的朋友可以参考下2024-01-01
最近线上运行的一个python任务负责处理一批数据,为提高处理效率,使用了python进程池,并会打印log,本文给大家分析了Python进程池log死锁问题以及解决方法,需要的朋友可以参考下2024-01-01 这篇文章主要介绍了Python数据结构与算法之完全树与最小堆,结合实例形式分析了Python完全树定义及堆排序功能实现相关操作技巧,需要的朋友可以参考下2017-12-12
这篇文章主要介绍了Python数据结构与算法之完全树与最小堆,结合实例形式分析了Python完全树定义及堆排序功能实现相关操作技巧,需要的朋友可以参考下2017-12-12










最新评论