
Python爬虫简单运用爬取代理IP的实现
功能1: 爬取西拉ip代理官网上的代理ip
环境:python3.8+pycharm
库:requests,lxml
浏览器:谷歌
IP地址:http://www.xiladaili.com/gaoni/
分析网页源码:

选中div元素后右键找到Copy再深入子菜单找到Copy Xpath点击一下就复制到XPath
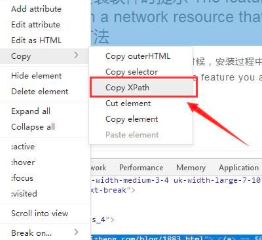
我们复制下来的Xpth内容为:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1]
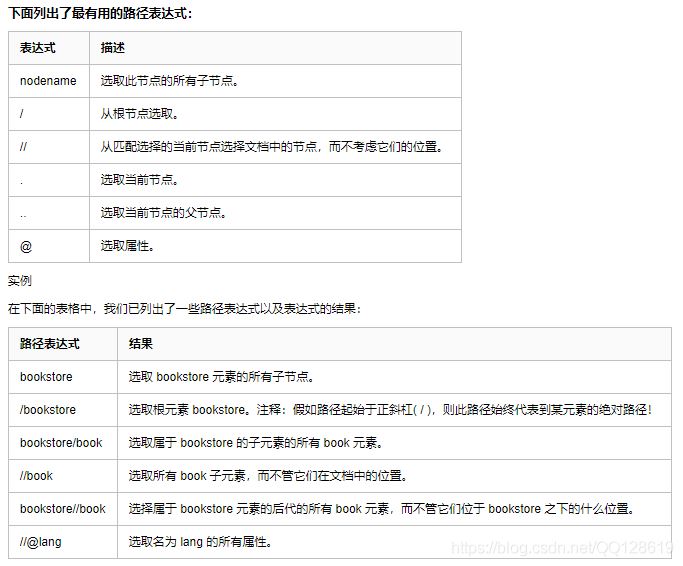
虽然可以查出来ip,但不利于程序自动爬取所有IP,利用谷歌XpathHelp测试一下

从上图可以看出,只匹配到了一个Ip,我们稍作修改,即可达到目的
,有关xpath规则,可以参考下表;


经过上面的规则学习后,我们修改为://*[@class=‘mt-0 mb-2 table-responsive']/table/tbody/tr/td[1],再利用xpthhelp工具验证一下:

这样我们就可以爬取整个页面的Ip地址了,为了方便爬取更多的IP,我们继续往下翻页,找到翻页按钮:
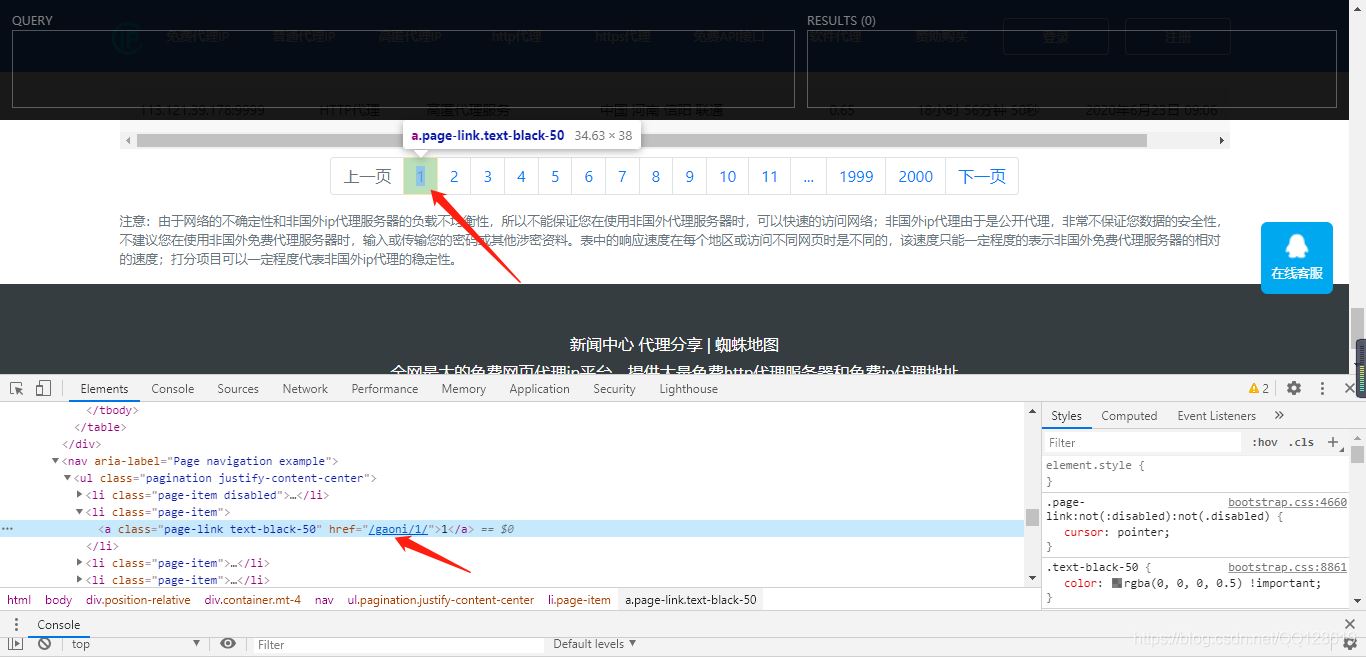
找规律,发现每翻一页,a标签下的href连接地址加1即可,python程序可以利用for循环解决翻页问题即可。
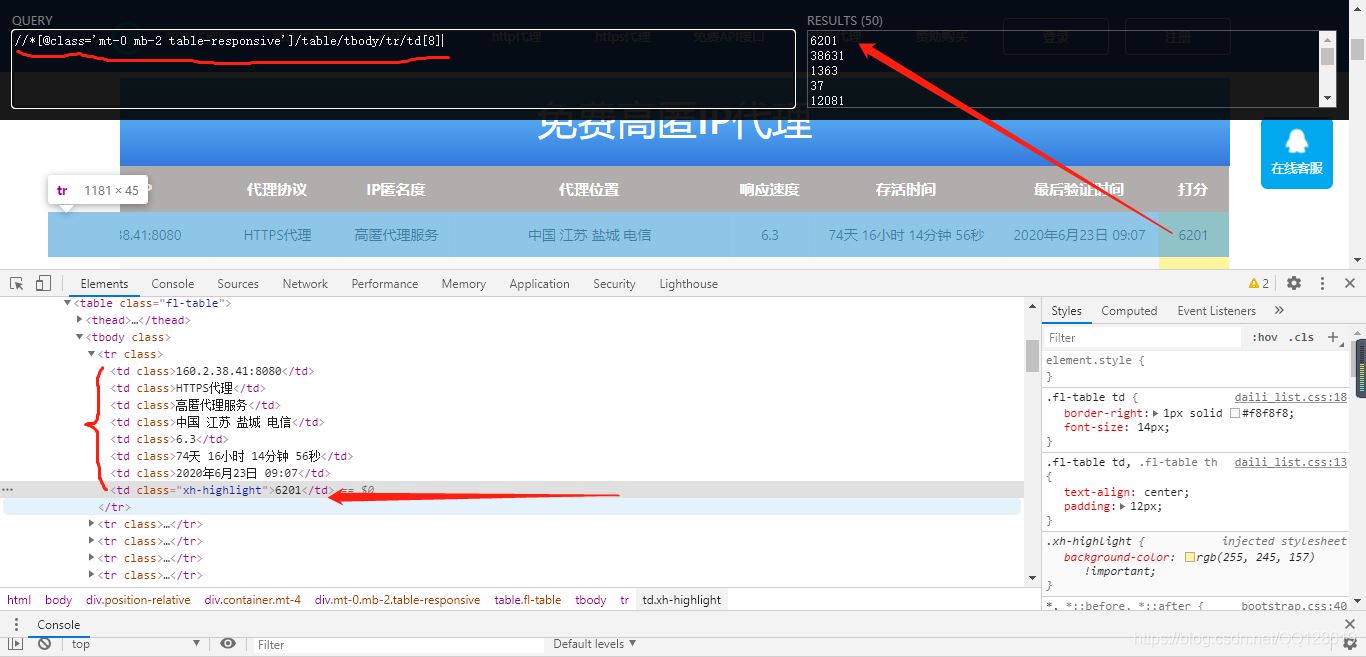
为了提高IP代理的质量,我们爬取评分高的IP来使用。找到评分栏下的Xpath路径,这里不再做详细介绍,思路参考上面找IP地址的思路,及XPath规则,过程参考下图:
Python代码实现
代码可复制粘贴直接使用,如果出现报错,修改一下cookie。这里使用代理ip爬取,防止IP被封。当然这里的代码还是基础的,有空可以写成代理池,多任务去爬。当然还可以使用其它思路去实现,这里只做入门介绍。当有了这些代理IP后,我们可以用文件保存,或者保存到数据库中,根据实际使用情况而定,这里不做保存,只放到列表变量中保存。
import requests
from lxml import etree
import time
class XiLaIp_Spider:
def __init__(self):
self.url = 'http://www.xiladaili.com/gaoni/'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'cookie': 'td_cookie=1539882751; csrftoken=lymOXQp49maLMeKXS1byEMMmsavQPtOCOUwy6WIbfMNazZW80xKKA8RW2Zuo6ssy; Hm_lvt_31dfac66a938040b9bf68ee2294f9fa9=1592547159; Hm_lvt_9bfa8deaeafc6083c5e4683d7892f23d=1592535959,1592539254,1592612217; Hm_lpvt_9bfa8deaeafc6083c5e4683d7892f23d=1592612332',
}
self.proxy = '116.196.85.150:3128'
self.proxies = {
"http": "http://%(proxy)s/" % {'proxy': self.proxy},
"https": "http://%(proxy)s/" % {'proxy': self.proxy}
}
self.list1 = []
def get_url(self):
file = open('Ip_Proxy.txt', 'a', encoding='utf-8')
ok_file = open('OkIp_Proxy.txt', 'a', encoding='utf-8')
for index in range(50):
time.sleep(3)
try:
res = requests.get(url=self.url if index == 0 else self.url + str(index) + "/", headers=self.headers,
proxies=self.proxies, timeout=10).text
except:
continue
data = etree.HTML(res).xpath("//*[@class='mt-0 mb-2 table-responsive']/table/tbody/tr/td[1]")
# '//*[@id="scroll"]/table/tbody/tr/td[1]'
score_data = etree.HTML(res).xpath("//*[@class='mt-0 mb-2 table-responsive']/table/tbody/tr/td[8]")
for i, j in zip(data, score_data):
# file.write(i.text + '\n')
score = int(j.text)
# 追加评分率大于十万的ip
if score > 100000:
self.list1.append(i.text)
set(self.list1)
file.close()
ok_ip = []
for i in self.list1:
try:
# 验证代理ip是否有效
res = requests.get(url='https://www.baidu.com', headers=self.headers, proxies={'http': 'http://' + i},
timeout=10)
if res.status_code == 200:
# ok_file.write(i + '\n')
ok_ip.append(i)
except:
continue
ok_file.close()
return ok_ip
def run(self):
return self.get_url()
dl = XiLaIp_Spider()
dl.run()
到此这篇关于Python爬虫简单运用爬取代理IP的实现的文章就介绍到这了,更多相关Python 爬取代理IP内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 现在很多场景需要使用的数字识别,比如银行卡识别,以及车牌识别等,在AI领域有很多图像识别算法,大多是居于opencv 或者谷歌开源的tesseract 识别,下面这篇文章主要给大家介绍了关于如何基于opencv实现简单的数字识别,需要的朋友可以参考下2021-09-09
现在很多场景需要使用的数字识别,比如银行卡识别,以及车牌识别等,在AI领域有很多图像识别算法,大多是居于opencv 或者谷歌开源的tesseract 识别,下面这篇文章主要给大家介绍了关于如何基于opencv实现简单的数字识别,需要的朋友可以参考下2021-09-09 在生物信息学领域,经常需要根据基因名称匹配其对应的编号,本文介绍了一种通过字典进行基因名称与编号匹配的方法,首先定义一个空列表存储对应编号,对于字典中不存在的基因名称,其编号默认为02024-09-09
在生物信息学领域,经常需要根据基因名称匹配其对应的编号,本文介绍了一种通过字典进行基因名称与编号匹配的方法,首先定义一个空列表存储对应编号,对于字典中不存在的基因名称,其编号默认为02024-09-09 今天小编就为大家分享一篇基于scrapy的redis安装和配置方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06
今天小编就为大家分享一篇基于scrapy的redis安装和配置方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06 这篇文章主要介绍了Python hashlib加密模块常用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了Python hashlib加密模块常用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-12-12 这篇文章主要介绍了python如何发送xml格式请求数据问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-06-06
这篇文章主要介绍了python如何发送xml格式请求数据问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-06-06 这篇文章主要介绍了Python-基础-简介入门的相关资料,需要的朋友可以参考下2014-08-08
这篇文章主要介绍了Python-基础-简介入门的相关资料,需要的朋友可以参考下2014-08-08 这篇文章主要为大家介绍了通过Python读取照片的Exif信息解锁图片背后的故事探究,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-12-12
这篇文章主要为大家介绍了通过Python读取照片的Exif信息解锁图片背后的故事探究,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-12-12 这篇文章主要介绍了在 Python 中如何使用 Re 模块的正则表达式通配符,本文详细解释了如何在 Python 中使用带有通配符的 re.sub() 来匹配字符串与正则表达式,需要的朋友可以参考下2023-06-06
这篇文章主要介绍了在 Python 中如何使用 Re 模块的正则表达式通配符,本文详细解释了如何在 Python 中使用带有通配符的 re.sub() 来匹配字符串与正则表达式,需要的朋友可以参考下2023-06-06 这篇文章主要为大家详细介绍了Python管理Windows服务的小脚本,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03
这篇文章主要为大家详细介绍了Python管理Windows服务的小脚本,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-03-03 这篇文章主要介绍了Python 中的参数传递、返回值、浅拷贝、深拷贝,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2019-06-06
这篇文章主要介绍了Python 中的参数传递、返回值、浅拷贝、深拷贝,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2019-06-06










最新评论