
selenium与xpath之获取指定位置的元素的实现
更新时间:2021年01月26日 09:21:07 作者:封妖师的徒弟
这篇文章主要介绍了selenium与xpath之获取指定位置的元素的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
今天有点新的与大家分享,关于selenium与xpath之间爬数据获取指定位置的时候,方式不一样哦。
详情可以看我的代码,以b站来看好吧:
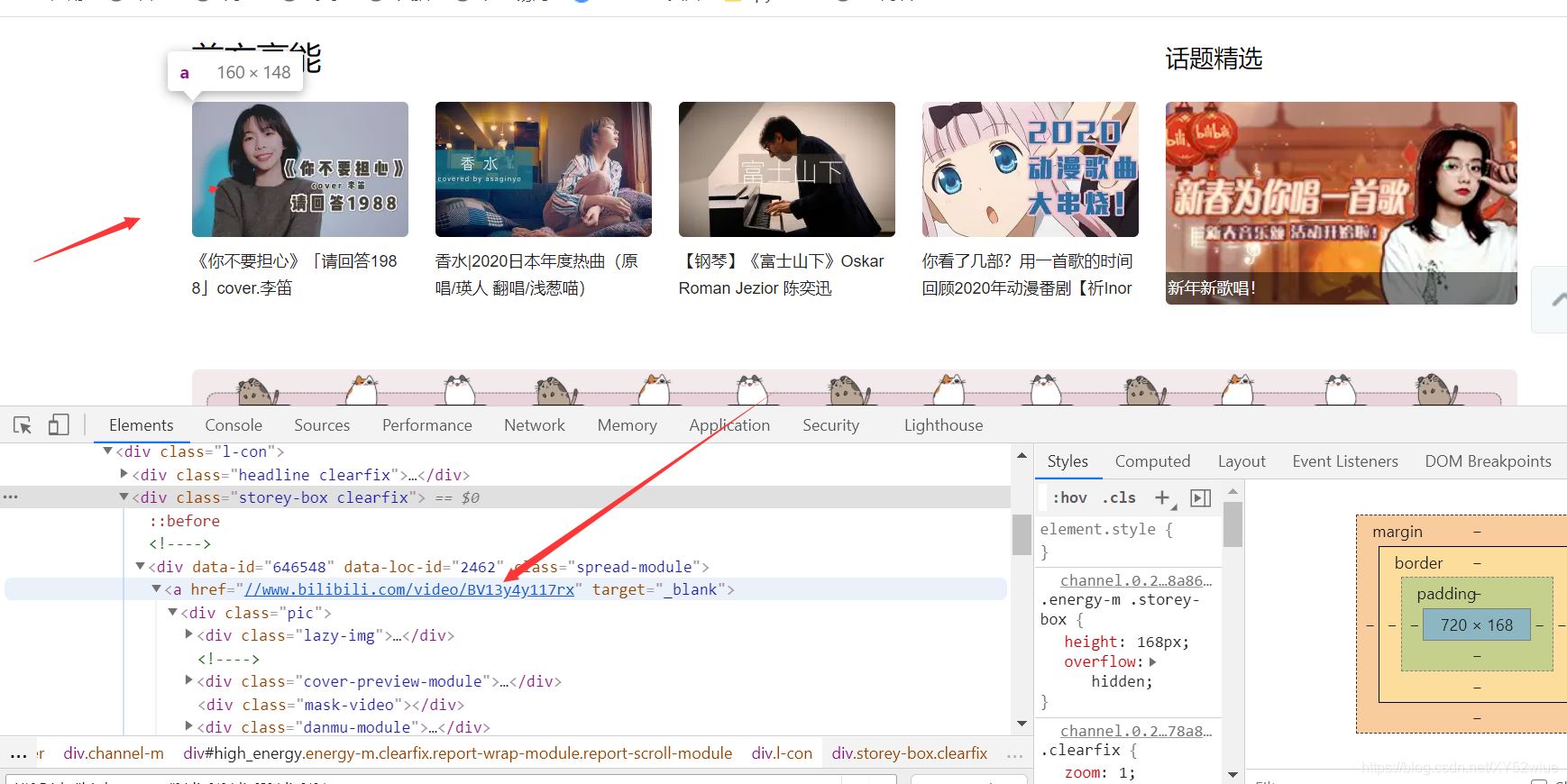
查看这href元素,如果是xpath,肯定这么写是没有问题的:
i.find_element_by_xpath('./a/@href')
但你再selenium里面这样写会报错,所以要改成这样
i.find_element_by_xpath('./a').get_attribute('href')
这样方可正确
这是一个小案例,关于爬取b站音乐视频,但我的技术水平有限,无法下载,找不到那个东东
大家如果知道如何下载可以在评论区留言,嘿嘿
import requests
from selenium.webdriver import Chrome,ChromeOptions
#后面越来越多喜欢用函数来实现了
def get_webhot(): #热搜函数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
url ="https://www.bilibili.com/" # 微博的地址
res = requests.get(url)
#这个就是再后台上面运行那个浏览器,不在表面上占用你的
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
#这里也要输入
browser = Chrome(options=option)
browser.get(url)
#解析那个web热搜前,按住ctrl+f会在下面出现一个框框,然后改就完事
browser.find_element_by_xpath('//*[@id="primaryChannelMenu"]/span[3]/div/a/span').click()
c = browser.find_elements_by_xpath('//*[@id="high_energy"]/div[1]/div[2]/div')
for i in c:
#这里一定要注意,在selenium中不能像xpath那样写('./a/@href')来获取指定的位置,要报错,只能这么获取,查了很久
detail_url = i.find_element_by_xpath('./a').get_attribute('href')
name = i.find_element_by_xpath('./a/p').get_attribute('title')
detail_page_text = requests.get(url=detail_url,headers = headers).text
print(detail_url,name)
#运行完事
get_webhot()
这是这个结果

到此这篇关于selenium与xpath之获取指定位置的元素的实现的文章就介绍到这了,更多相关selenium与xpath指定位置元素内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python使用回溯法子集树模板解决爬楼梯问题,简单说明了爬楼梯问题并结合实例形式给出了Python回溯法子集树模板解决爬楼梯问题的相关操作技巧,需要的朋友可以参考下2017-09-09
这篇文章主要介绍了Python使用回溯法子集树模板解决爬楼梯问题,简单说明了爬楼梯问题并结合实例形式给出了Python回溯法子集树模板解决爬楼梯问题的相关操作技巧,需要的朋友可以参考下2017-09-09 开发软件的时候不可避免要和数据库发生交互,但是有些 SQL 请求非常耗时,如果在主线程中发送请求,可能会造成界面卡顿,本文将介绍一种让数据库请求变得和前端的 ajax 请求一样简单,希望对大家有所帮助2023-12-12
开发软件的时候不可避免要和数据库发生交互,但是有些 SQL 请求非常耗时,如果在主线程中发送请求,可能会造成界面卡顿,本文将介绍一种让数据库请求变得和前端的 ajax 请求一样简单,希望对大家有所帮助2023-12-12
Python3.4实现从HTTP代理网站批量获取代理并筛选的方法示例
这篇文章主要介绍了Python3.4实现从HTTP代理网站批量获取代理并筛选的方法,涉及Python网络连接、读取、判断等相关操作技巧,需要的朋友可以参考下2017-09-09 这篇文章主要介绍了python实现图像随机裁剪的示例代码,帮助大家更好的理解和使用python处理图片,感兴趣的朋友可以了解下2020-12-12
这篇文章主要介绍了python实现图像随机裁剪的示例代码,帮助大家更好的理解和使用python处理图片,感兴趣的朋友可以了解下2020-12-12
浅谈pytorch中torch.max和F.softmax函数的维度解释
这篇文章主要介绍了浅谈pytorch中torch.max和F.softmax函数的维度解释,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 这篇文章主要介绍了python使用pil生成缩略图的方法,涉及Python使用pil模块操作图片的技巧,非常具有实用价值,需要的朋友可以参考下2015-03-03
这篇文章主要介绍了python使用pil生成缩略图的方法,涉及Python使用pil模块操作图片的技巧,非常具有实用价值,需要的朋友可以参考下2015-03-03 这篇文章主要介绍了pandas 对日期类型数据的处理方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了pandas 对日期类型数据的处理方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08 今天小编就为大家分享一篇关于Django使用paginator插件实现翻页功能的实例,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2018-10-10
今天小编就为大家分享一篇关于Django使用paginator插件实现翻页功能的实例,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧2018-10-10 这篇文章主要介绍了python super()函数的基本使用,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-09-09
这篇文章主要介绍了python super()函数的基本使用,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-09-09 这篇文章主要给大家分享的是Python函数参数的进阶用法,Python函数的参数根据函数 在调用时 传参的形式分为关键字参数和位置参数,下面文章小编就来介绍相关资料,需要的朋友可以参考一下2021-10-10
这篇文章主要给大家分享的是Python函数参数的进阶用法,Python函数的参数根据函数 在调用时 传参的形式分为关键字参数和位置参数,下面文章小编就来介绍相关资料,需要的朋友可以参考一下2021-10-10










最新评论