
python+selenium爬取微博热搜存入Mysql的实现方法
更新时间:2021年01月27日 11:45:00 作者:也曾rgnxhw
这篇文章主要介绍了python+selenium爬取微博热搜存入Mysql的实现方法,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
最终的效果
废话不多少,直接上图
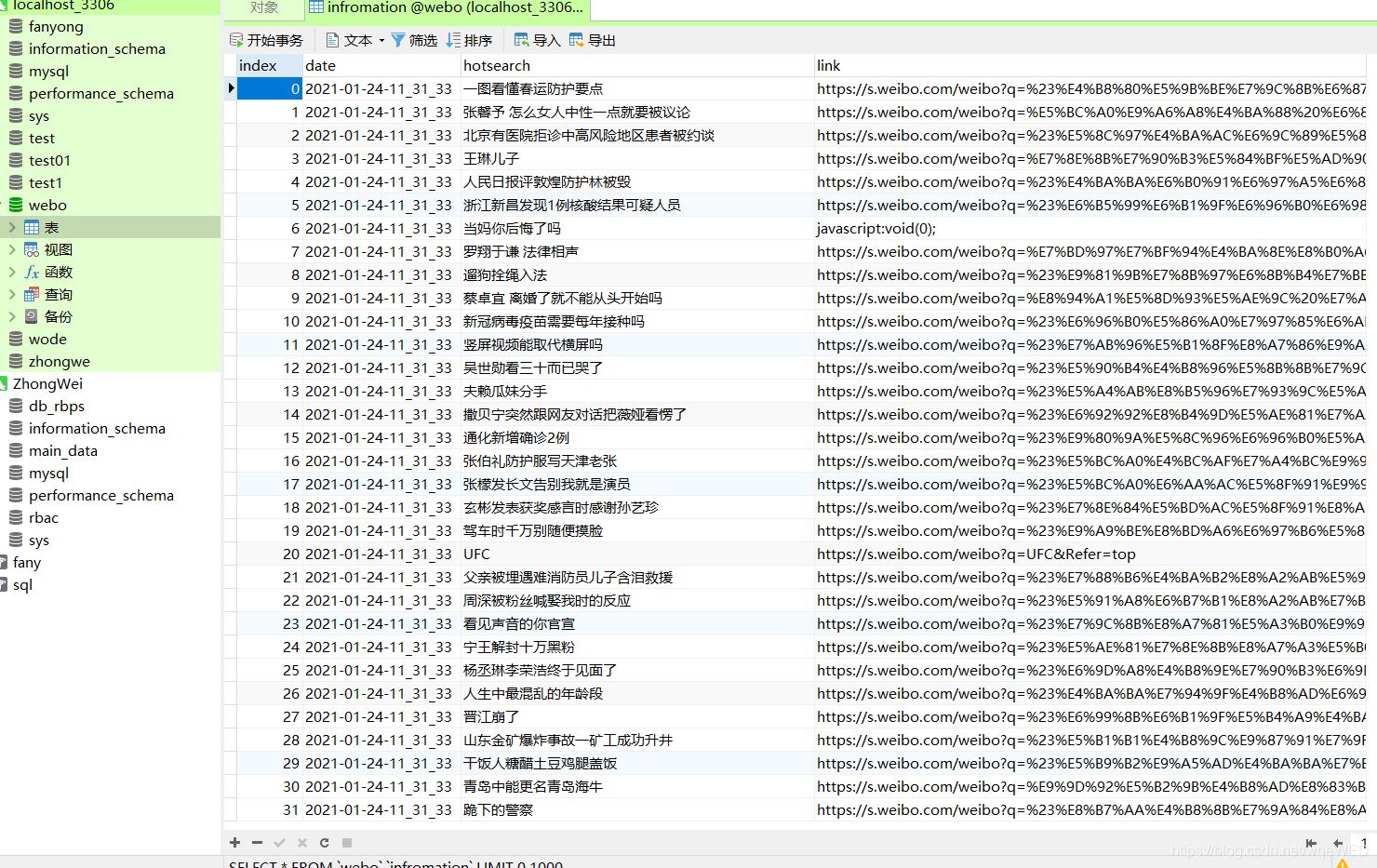
这里可以清楚的看到,数据库里包含了日期,内容,和网站link
下面我们来分析怎么实现
使用的库
import requests from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd
目标分析
这是微博热搜的link:点我可以到目标网页

首先我们使用selenium对目标网页进行请求
然后我们使用xpath对网页元素进行定位,遍历获得所有数据
然后使用pandas生成一个Dataframe对像,直接存入数据库
一:得到数据
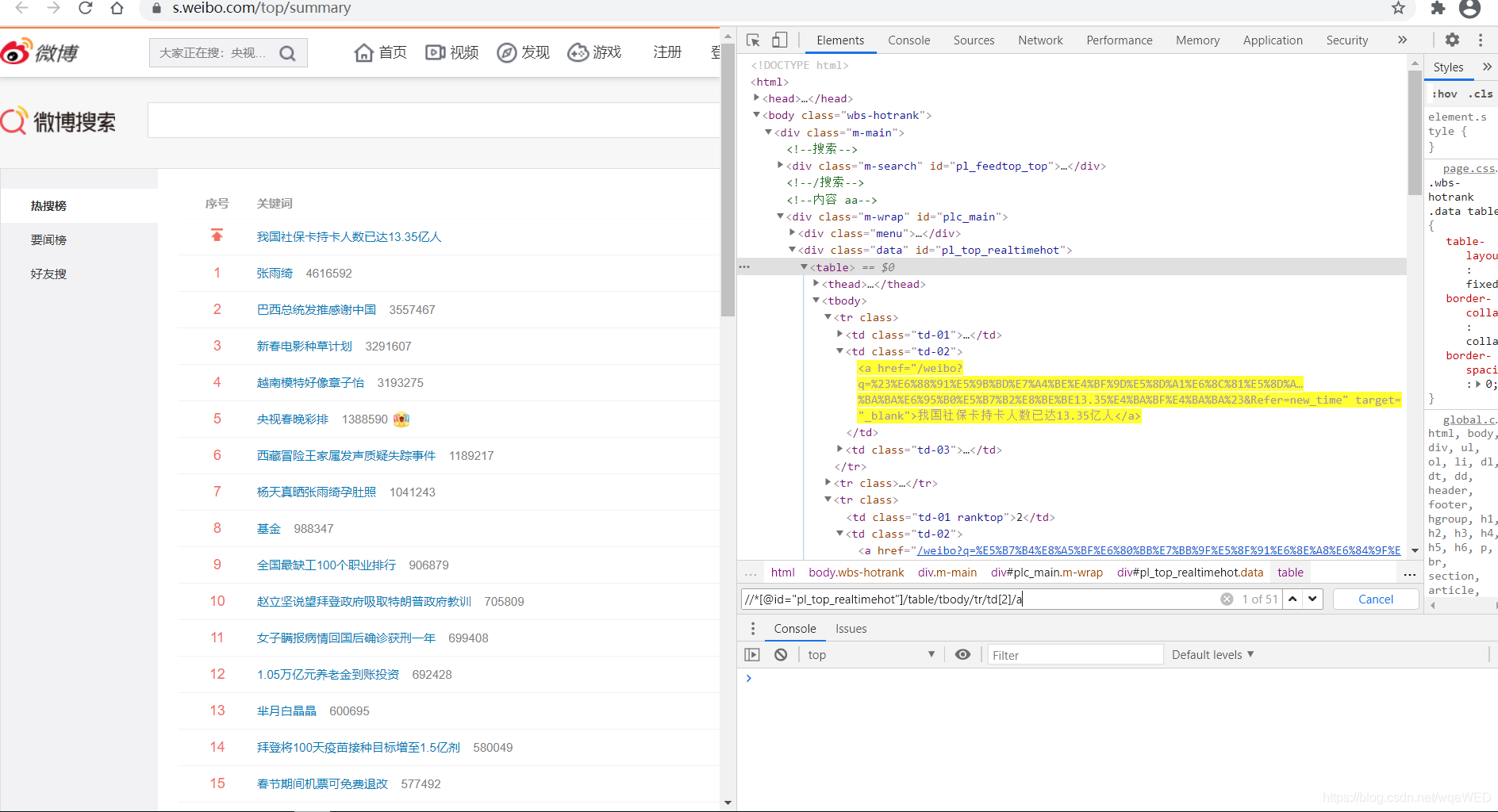
我们看到,使用xpath可以得到51条数据,这就是各热搜,从中我们可以拿到链接和标题内容
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a') #得到所有数据
context = [i.text for i in c] # 得到标题内容
links = [i.get_attribute('href') for i in c] # 得到link
然后我们再使用zip函数,将date,context,links合并
zip函数是将几个列表合成一个列表,并且按index对分列表的数据合并成一个元组,这个可以生产pandas对象。
dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
其中date可以使用time模块获得
二:链接数据库
这个很容易
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
总代码
from selenium.webdriver import Chrome, ChromeOptions
import time
from sqlalchemy import create_engine
import pandas as pd
def get_data():
url = r"https://s.weibo.com/top/summary" # 微博的地址
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
browser = Chrome(options=option)
browser.get(url)
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a')
context = [i.text for i in all]
links = [i.get_attribute('href') for i in all]
date = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime())
dates = []
for i in range(len(context)):
dates.append(date)
# print(len(dates),len(context),dates,context)
dc = zip(dates, context, links)
pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
# pdf.to_sql(name=in, con=enging, if_exists="append")
return pdf
def w_mysql(pdf):
try:
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
except:
print('出错了')
if __name__ == '__main__':
xx = get_data()
w_mysql(xx)
到此这篇关于python+selenium爬取微博热搜存入Mysql的实现方法的文章就介绍到这了,更多相关python selenium爬取微博热搜存入Mysql内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python全面解析xml文件方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-02-02
这篇文章主要介绍了Python全面解析xml文件方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-02-02 GUI,全称为图形用户界面,又称为图形用户接口,是一种人与计算机通信的界面显示格式。那么Python常用GUI框架有哪些呢?我们来看看具体介绍2022-11-11
GUI,全称为图形用户界面,又称为图形用户接口,是一种人与计算机通信的界面显示格式。那么Python常用GUI框架有哪些呢?我们来看看具体介绍2022-11-11 django.urls.path是Django中用于定义URL映射规则的函数之一,本文主要介绍了django中path函数使用,具有一定的参考价值,感兴趣的可以了解一下2023-12-12
django.urls.path是Django中用于定义URL映射规则的函数之一,本文主要介绍了django中path函数使用,具有一定的参考价值,感兴趣的可以了解一下2023-12-12 在本文里我们给大家整理了一篇关于python图形绘制奥运五环的实例内容,大家可以跟着学习下。2019-09-09
在本文里我们给大家整理了一篇关于python图形绘制奥运五环的实例内容,大家可以跟着学习下。2019-09-09 这篇文章主要为大家详细介绍了python抖音表白程序源代码,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-04-04
这篇文章主要为大家详细介绍了python抖音表白程序源代码,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-04-04 说起Excel,那绝对是数据处理领域王者般的存在。而作为网红语言Python,在数据领域也是被广泛使用。本文将利用Python和Excel制作一个视频下载器,需要的可以参考一下2022-05-05
说起Excel,那绝对是数据处理领域王者般的存在。而作为网红语言Python,在数据领域也是被广泛使用。本文将利用Python和Excel制作一个视频下载器,需要的可以参考一下2022-05-05 这篇文章主要介绍了Python数据存储之XML文档和字典的互转,通过如何将一个字典转换为XML文档,并将该XML文档保存为文本文件的提问展开主题相关介绍,需要的朋友可以参考一下下面文章内容2022-06-06
这篇文章主要介绍了Python数据存储之XML文档和字典的互转,通过如何将一个字典转换为XML文档,并将该XML文档保存为文本文件的提问展开主题相关介绍,需要的朋友可以参考一下下面文章内容2022-06-06 这篇文章主要介绍了python飞机大战pygame碰撞检测实现方法,结合实例形式分析了Python使用pygame实现飞机大战游戏中碰撞检测的原理与相关操作技巧,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了python飞机大战pygame碰撞检测实现方法,结合实例形式分析了Python使用pygame实现飞机大战游戏中碰撞检测的原理与相关操作技巧,需要的朋友可以参考下2019-12-12 可视化是将数据转换成图形或图像在屏幕上显示出来,本文主要介绍了Django使用echarts进行可视化展示的实践,感兴趣的可以了解一下2021-06-06
可视化是将数据转换成图形或图像在屏幕上显示出来,本文主要介绍了Django使用echarts进行可视化展示的实践,感兴趣的可以了解一下2021-06-06 本人c程序员,最近开始学python,深深的被python的强大所吸引,今后也会把学到的点点滴滴记录下来,现在分享一下关于类属性和实例属性的一些问题,很基础的东西2012-08-08
本人c程序员,最近开始学python,深深的被python的强大所吸引,今后也会把学到的点点滴滴记录下来,现在分享一下关于类属性和实例属性的一些问题,很基础的东西2012-08-08










最新评论