
python 多线程爬取壁纸网站的示例
更新时间:2021年02月20日 15:15:47 作者:Martina_oh
这篇文章主要介绍了python 多线程爬取壁纸网站的示例,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下
基本开发环境
· Python 3.6
· Pycharm
需要导入的库

目标网页分析
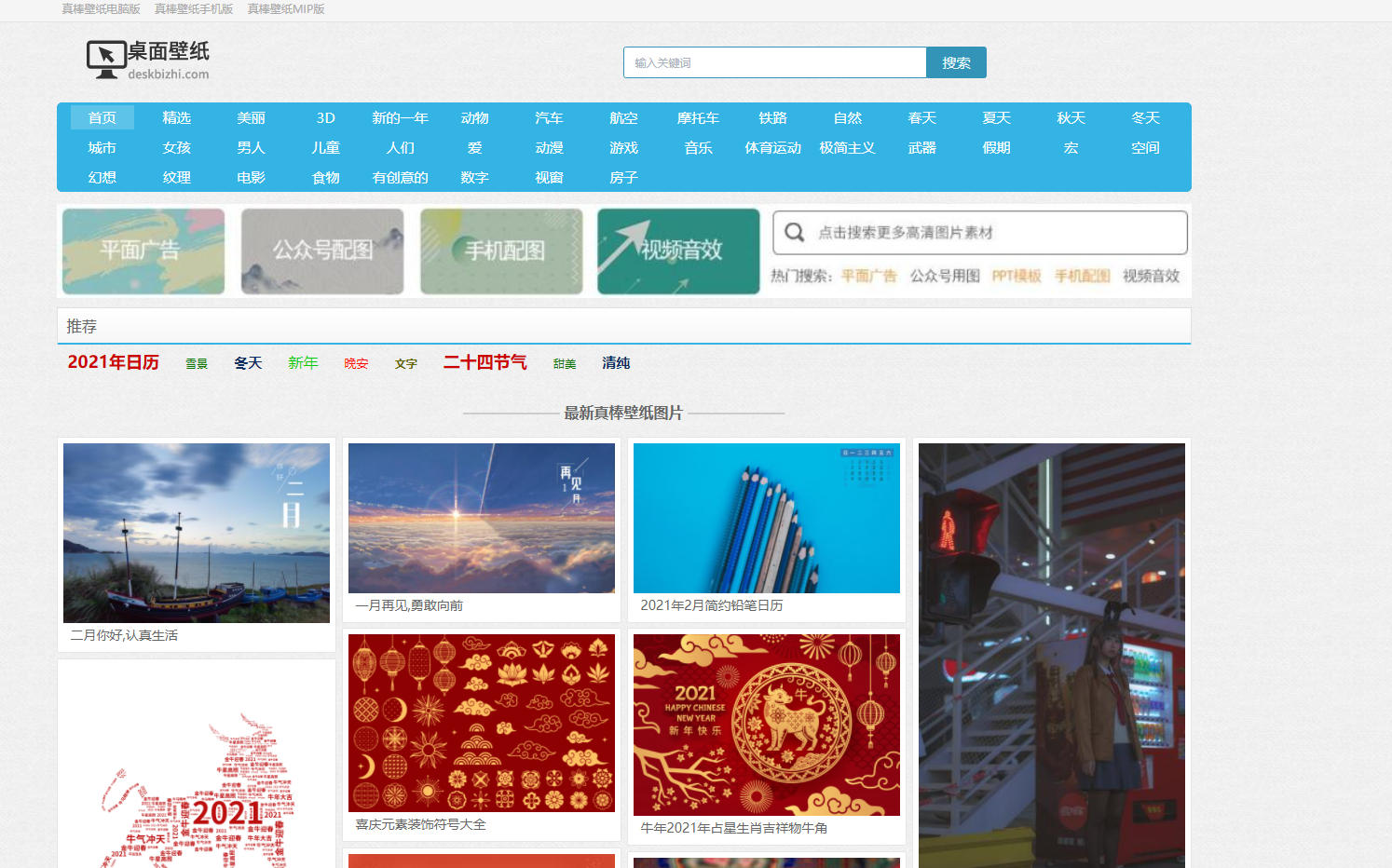
网站是静态网站,没有加密,可以直接爬取
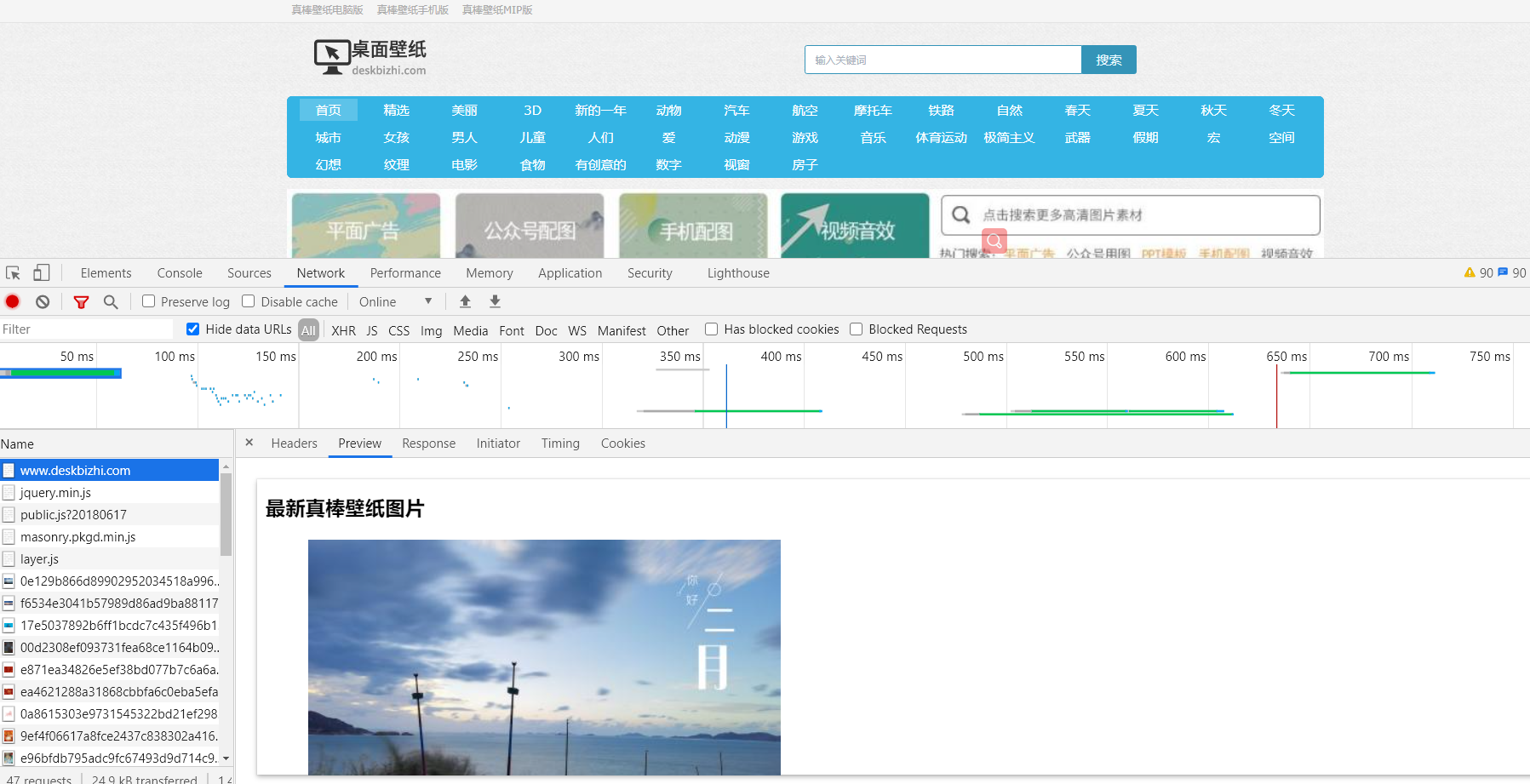
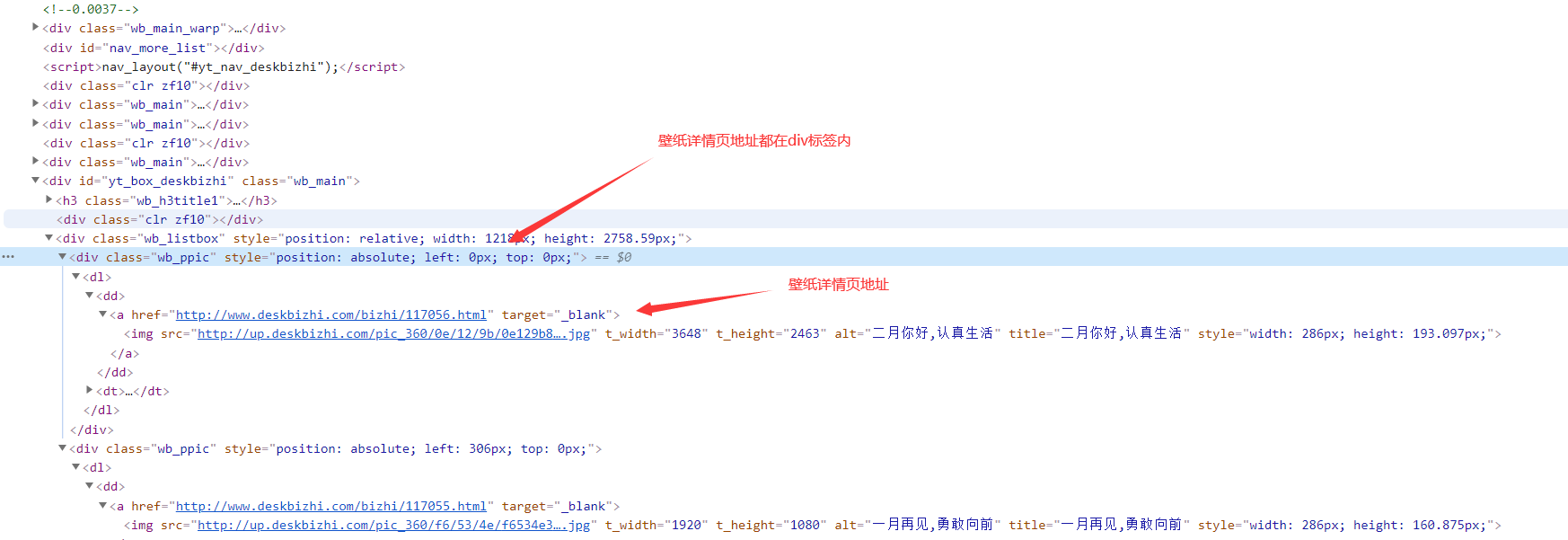
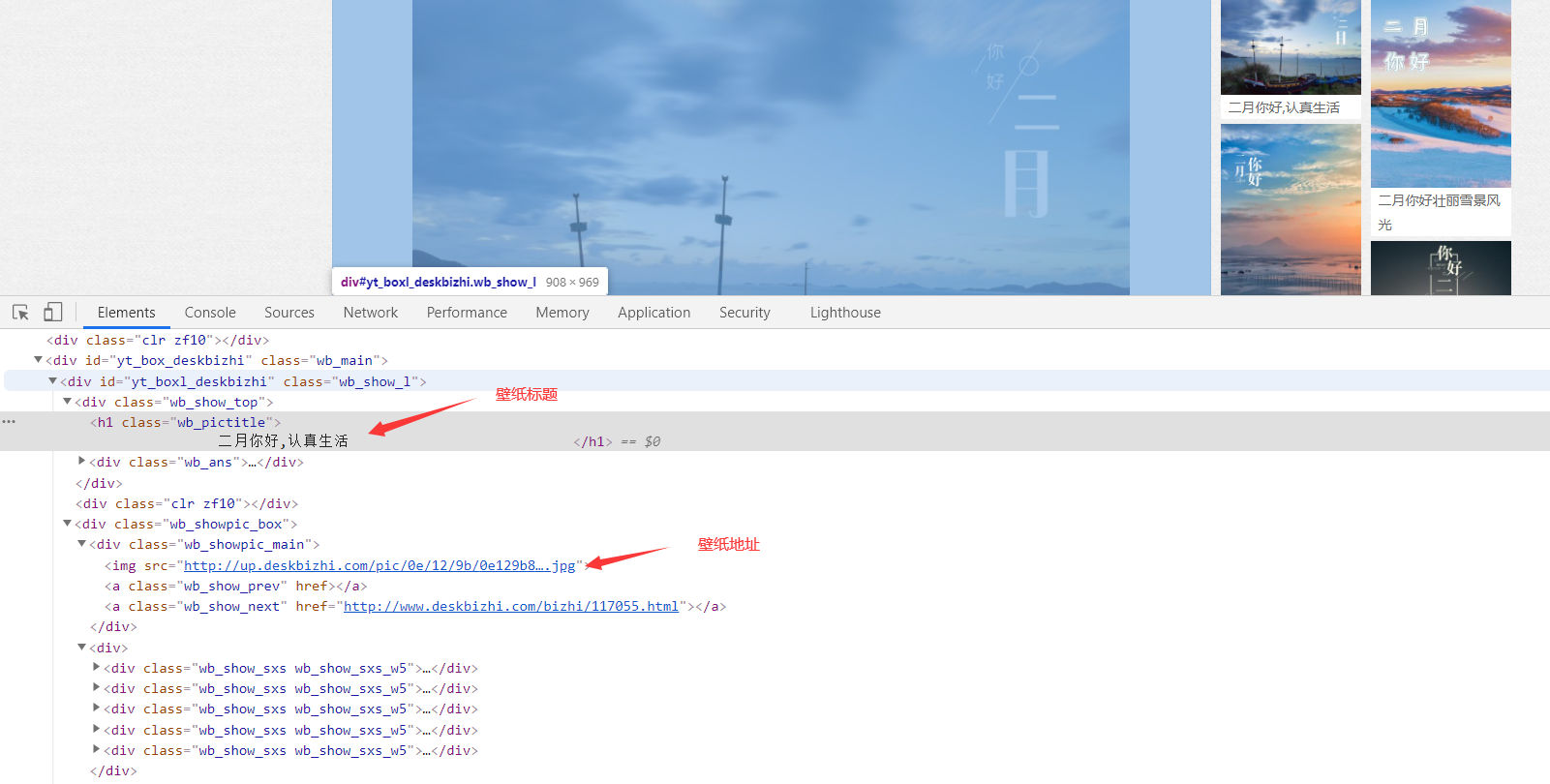
整体思路:
1、先在列表页面获取每张壁纸的详情页地址
2、在壁纸详情页面获取壁纸真实高清url地址
3、保存地址
代码实现
模拟浏览器请请求网页,获取网页数据
这里只选择爬取前10页的数据
代码如下
import threading
import parsel
import requests
def get_html(html_url):
'''
获取网页源代码
:param html_url: 网页url
:return:
'''
response = requests.get(url=html_url, headers=headers)
return response
def get_par(html_data):
'''
把 response.text 转换成 selector 对象 解析提取数据
:param html_data: response.text
:return: selector 对象
'''
selector = parsel.Selector(html_data)
return selector
def download(img_url, title):
'''
保存数据
:param img_url: 图片地址
:param title: 图片标题
:return:
'''
content = get_html(img_url).content
path = '壁纸\\' + title + '.jpg'
with open(path, mode='wb') as f:
f.write(content)
print('正在保存', title)
def main(url):
'''
主函数
:param url: 列表页面 url
:return:
'''
html_data = get_html(url).text
selector = get_par(html_data)
lis = selector.css('.wb_listbox div dl dd a::attr(href)').getall()
for li in lis:
img_data = get_html(li).text
img_selector = get_par(img_data)
img_url = img_selector.css('.wb_showpic_main img::attr(src)').get()
title = img_selector.css('.wb_pictitle::text').get().strip()
download(img_url, title)
end_time = time.time() - s_time
print(end_time)
if __name__ == '__main__':
for page in range(1, 11):
url = 'http://www.deskbizhi.com/min/list-{}.html'.format(page)
main_thread = threading.Thread(target=main, args=(url,))
main_thread.start()
以上就是python 多线程爬取壁纸网站的示例的详细内容,更多关于python 爬取壁纸网站的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章介绍了python解析.pyd文件的详细代码,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考2021-12-12
这篇文章介绍了python解析.pyd文件的详细代码,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考2021-12-12 消息队列(MQ,Message Queue)在消息数据传输中的保存作用为数据通信提供了保障和实时处理上的便利,这里我们就来看一下Python中线程的MQ消息队列实现以及消息队列的优点解析2016-06-06
消息队列(MQ,Message Queue)在消息数据传输中的保存作用为数据通信提供了保障和实时处理上的便利,这里我们就来看一下Python中线程的MQ消息队列实现以及消息队列的优点解析2016-06-06 LyScript 插件集成的内置API函数可灵活的实现绕过各类反调试保护机制。本文将运用LyScript实现绕过大多数通用调试机制,实现隐藏调试器的目的,需要的可以参考一下2022-09-09
LyScript 插件集成的内置API函数可灵活的实现绕过各类反调试保护机制。本文将运用LyScript实现绕过大多数通用调试机制,实现隐藏调试器的目的,需要的可以参考一下2022-09-09 下面小编就为大家带来一篇基于Python __dict__与dir()的区别详解。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10
下面小编就为大家带来一篇基于Python __dict__与dir()的区别详解。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。2017-09-09
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。2017-09-09 这篇文章主要介绍了基于Keras的格式化输出Loss实现方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06
这篇文章主要介绍了基于Keras的格式化输出Loss实现方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 这篇文章主要介绍了Python中文分词工具之结巴分词用法,结合实例形式总结分析了Python针对中文文件的读取与分词操作过程中遇到的问题与解决方法,需要的朋友可以参考下2017-04-04
这篇文章主要介绍了Python中文分词工具之结巴分词用法,结合实例形式总结分析了Python针对中文文件的读取与分词操作过程中遇到的问题与解决方法,需要的朋友可以参考下2017-04-04
python3 cookbook解压可迭代对象赋值给多个变量的问题及解决方案
这篇文章主要介绍了python3 cookbook-解压可迭代对象赋值给多个变量,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2024-01-01 这篇文章主要介绍了python求列表交集的方法,实例汇总了三个常用的方法,具有一定的参考借鉴价值,需要的朋友可以参考下2014-11-11
这篇文章主要介绍了python求列表交集的方法,实例汇总了三个常用的方法,具有一定的参考借鉴价值,需要的朋友可以参考下2014-11-11 这篇文章主要介绍了Python实现的读写json文件功能,结合实例形式分析了Python针对json文件进行读写的常见操作技巧与注意事项,需要的朋友可以参考下2018-06-06
这篇文章主要介绍了Python实现的读写json文件功能,结合实例形式分析了Python针对json文件进行读写的常见操作技巧与注意事项,需要的朋友可以参考下2018-06-06










最新评论