
Python爬虫分析微博热搜关键词的实现代码
更新时间:2021年02月22日 10:15:41 作者:北晨lpl
这篇文章主要介绍了Python爬虫分析微博热搜关键词的实现代码,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
1,使用到的第三方库
requests
BeautifulSoup 美味汤
worldcloud 词云
jieba 中文分词
matplotlib 绘图
2,代码实现部分
import requests
import wordcloud
import jieba
from bs4 import BeautifulSoup
from matplotlib import pyplot as plt
from pylab import mpl
#设置字体
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
url = 'https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6'
try:
#获取数据
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text,'html.parser')
data = soup.find_all('a')
d_list = []
for item in data:
d_list.append(item.text)
words = d_list[4:-11:]
#中文分词
result = list(jieba.cut(words[0]))
for word in words[1::]:
result.extend(jieba.cut(word))
redata = []
for it in result:
if len(it) <= 1:
continue
else:
redata.append(it)
result_str = ' '.join(redata)
#输出词云图
font = r'C:\Windows\Fonts\simhei.ttf'
w = wordcloud.WordCloud(font_path=font,width=600,height=400)
w.generate(result_str)
w.to_file('微博热搜关键词词云.png')
key = list(set(redata))
x,y = [],[]
#筛选数据
for st in key:
count = redata.count(st)
if count <= 1:
continue
else:
x.append(st)
y.append(count)
x.sort()
y.sort()
#绘制结果图
plt.plot(x,y)
plt.show()
except Exception as e:
print(e)
3,运行结果

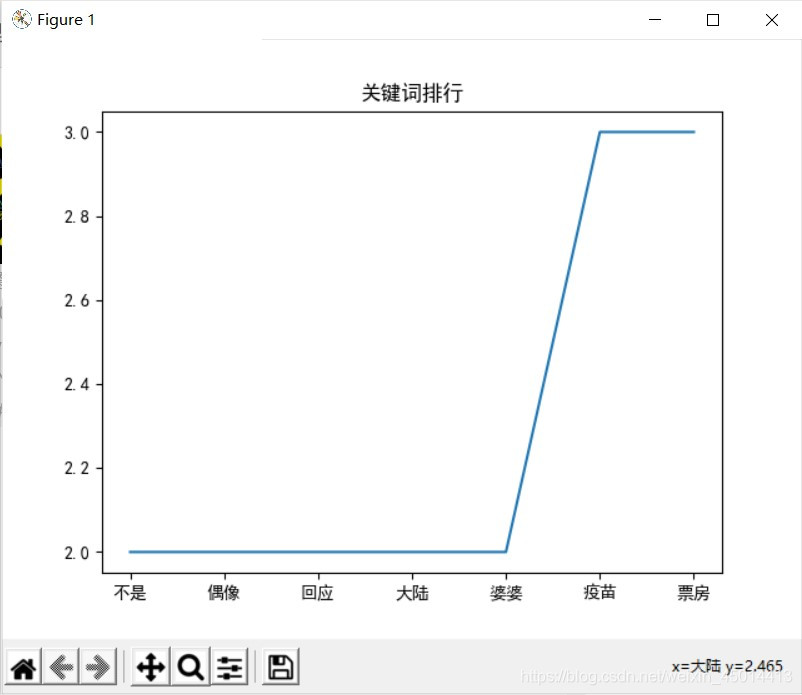
到此这篇关于Python爬虫分析微博热搜关键词的文章就介绍到这了,更多相关Python爬虫微博热搜内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

利用Python脚本写端口扫描器socket,python-nmap
这篇文章主要介绍了利用Python脚本写端口扫描器socket,python-nmap,文章围绕主题展开详细介绍,具有一定的参考价值,需要的小伙伴可以参考一下2022-07-07 最近想爬取淘宝的一些商品,但是发现如果要使用搜索等一些功能时基本都需要登录,所以就想出一篇模拟登录淘宝的文章!本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-08-08
最近想爬取淘宝的一些商品,但是发现如果要使用搜索等一些功能时基本都需要登录,所以就想出一篇模拟登录淘宝的文章!本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-08-08
DRF QuerySet Instance数据库操作功能概述
这篇文章主要为大家介绍了DRF QuerySet Instance数据库处理的功能概述,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-10-10 这篇文章主要介绍了Python类和对象的定义与实际应用,结合三个具体案例形式分析了Python面向对象程序设计中类与对象的定义、应用、设计模式等相关操作技巧,需要的朋友可以参考下2018-12-12
这篇文章主要介绍了Python类和对象的定义与实际应用,结合三个具体案例形式分析了Python面向对象程序设计中类与对象的定义、应用、设计模式等相关操作技巧,需要的朋友可以参考下2018-12-12 这篇文章主要介绍了Django防御csrf攻击的实现方式(包括ajax请求),具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09
这篇文章主要介绍了Django防御csrf攻击的实现方式(包括ajax请求),具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-09-09 我从Stephen A. Goss那读到关于了《Python 3正在毁灭Python》。这篇文章有不少精彩的论点,但我却并不认为Python 3是在毁灭Python,也不认为整个局面对Python一点也不利2014-11-11
我从Stephen A. Goss那读到关于了《Python 3正在毁灭Python》。这篇文章有不少精彩的论点,但我却并不认为Python 3是在毁灭Python,也不认为整个局面对Python一点也不利2014-11-11 今天小编就为大家分享一篇python psutil监控进程实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12
今天小编就为大家分享一篇python psutil监控进程实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-12-12 这篇文章主要介绍了七种Python代码审查工具推荐,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03
这篇文章主要介绍了七种Python代码审查工具推荐,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下2021-03-03 这篇文章主要为大家详细介绍了python实现定时打卡小程序,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-11-11
这篇文章主要为大家详细介绍了python实现定时打卡小程序,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-11-11 这篇文章主要介绍了Python实现将图片转换为ASCII字符画,要将图片转换为字符图其实很简单,我们首先将图片转换为灰度图像,这样图片的每个像素点的颜色值都是0到255,然后我们选用一些在文字矩形框内占用面积从大到小的ASCII码字符2022-08-08
这篇文章主要介绍了Python实现将图片转换为ASCII字符画,要将图片转换为字符图其实很简单,我们首先将图片转换为灰度图像,这样图片的每个像素点的颜色值都是0到255,然后我们选用一些在文字矩形框内占用面积从大到小的ASCII码字符2022-08-08










最新评论