
Python爬虫制作翻译程序的示例代码
更新时间:2021年02月22日 10:29:32 作者:欧业
这篇文章主要介绍了Python爬虫制作翻译程序的示例代码,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
上篇文章给大家介绍了Python爬虫实现百度翻译功能过程详解
Python爬虫学习之翻译小程序 感兴趣的朋友点击查看。
今天给大家介绍Python爬虫制作翻译程序的方法,具体内容如下所示:
此处我爬的是百度翻译,打开百度翻译的页面
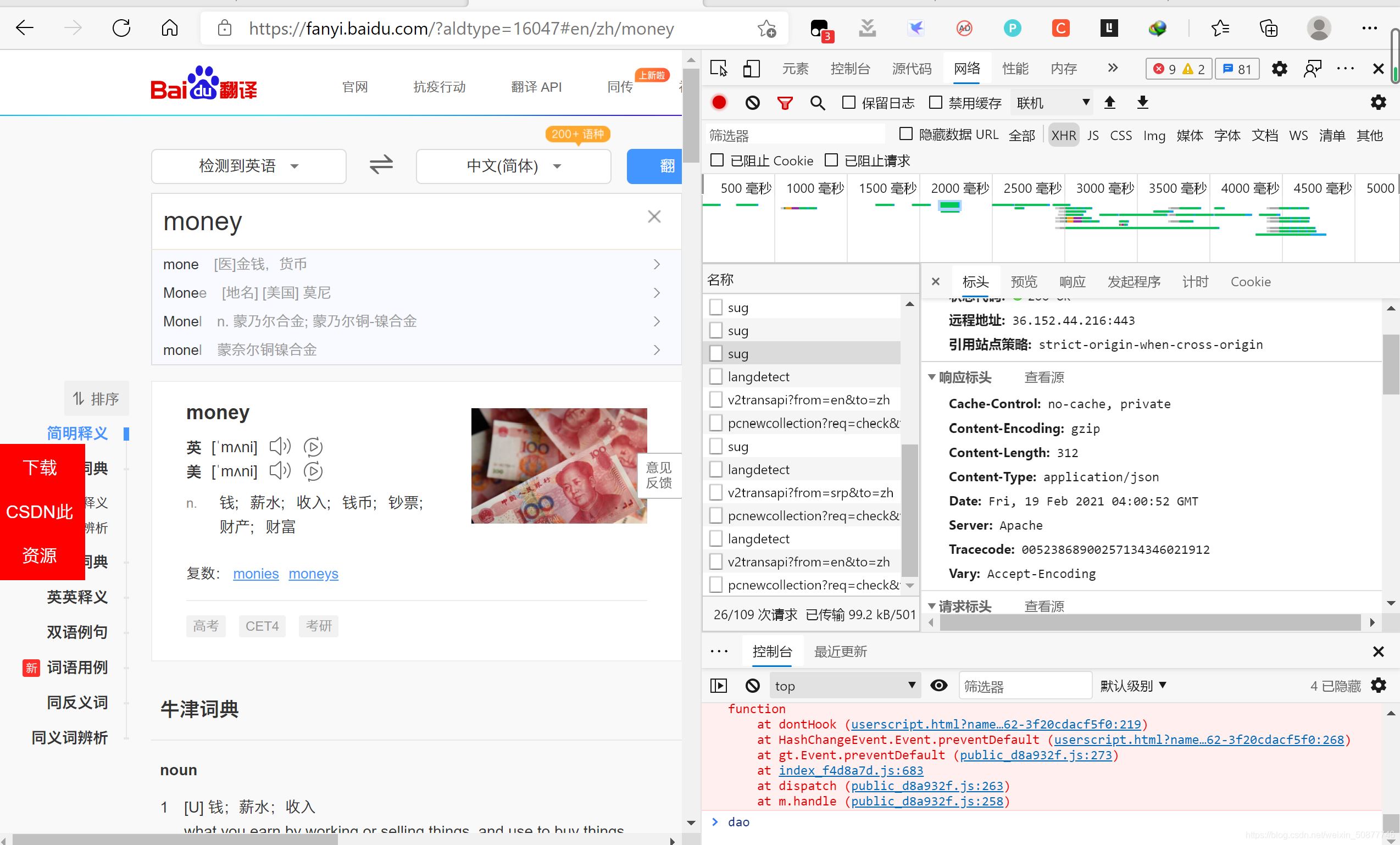
我们要爬的是sug,爬它的响应信息

程序如下
import json
import requests
if __name__ == "__main__":
url = "https://fanyi.baidu.com/sug"
header = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.68'
}
while 1:
a = input("输入单词(中文):")
data = {
"kw": a
}
res = requests.post(url=url, data=data, headers=header)
data = json.loads(res.text)
result = [(d['k'], d['v']) for d in data['data']]
print("具体意思: "+data['data'][0]['v'])
print("其他词性拓展: "+data['data'][1]['k']+" "+data['data'][1]['v'])
for i in range(2, len(result)):
print(" "+data['data'][i]['k']+" "+data['data'][i]['v'])
效果如下


到此这篇关于Python爬虫制作翻译程序的示例代码的文章就介绍到这了,更多相关Python爬虫翻译程序内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了python查看zip包中文件及大小的方法,实例分析了Python基于zipfile模块操作zip压缩文件的相关技巧,非常简单实用,需要的朋友可以参考下2015-07-07
这篇文章主要介绍了python查看zip包中文件及大小的方法,实例分析了Python基于zipfile模块操作zip压缩文件的相关技巧,非常简单实用,需要的朋友可以参考下2015-07-07
Python3实现的爬虫爬取数据并存入mysql数据库操作示例
这篇文章主要介绍了Python3实现的爬虫爬取数据并存入mysql数据库操作,涉及Python正则爬取数据及针对mysql数据库的存储操作相关实现技巧,需要的朋友可以参考下2018-06-06 这篇文章主要介绍了Python数据持久化存储实现方法,结合实例形式分析了Python基于pymongo及mysql模块的数据持久化存储操作相关实现技巧,需要的朋友可以参考下2019-12-12
这篇文章主要介绍了Python数据持久化存储实现方法,结合实例形式分析了Python基于pymongo及mysql模块的数据持久化存储操作相关实现技巧,需要的朋友可以参考下2019-12-12 工作中最常见的配置文件有四种:普通key=value的配置文件、Json格式的配置文件、HTML格式的配置文件以及YMAML配置文件。这篇文章主要介绍了Python比较配置文件的方法 ,需要的朋友可以参考下2019-06-06
工作中最常见的配置文件有四种:普通key=value的配置文件、Json格式的配置文件、HTML格式的配置文件以及YMAML配置文件。这篇文章主要介绍了Python比较配置文件的方法 ,需要的朋友可以参考下2019-06-06 这篇文章主要为大家详细介绍了如何解决Python中保存CSV文件内容乱码的问题,并提供详细的示例代码以更好地理解和解决这个问题,希望对大家有所帮助2024-03-03
这篇文章主要为大家详细介绍了如何解决Python中保存CSV文件内容乱码的问题,并提供详细的示例代码以更好地理解和解决这个问题,希望对大家有所帮助2024-03-03 这篇文章主要介绍了pytorch如何冻结某层参数的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-01-01
这篇文章主要介绍了pytorch如何冻结某层参数的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-01-01 下面小编就为大家带来一篇浅谈Python 对象内存占用。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-07-07
下面小编就为大家带来一篇浅谈Python 对象内存占用。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2016-07-07 文本查重,也称为文本去重,是一项旨在识别文本文档之间的相似性或重复性的技术或任务,它的主要目标是确定一个文本文档是否包含与其他文档相似或重复的内容,本文给大家介绍了利用python检测文本相似性的原理和方法,需要的朋友可以参考下2023-11-11
文本查重,也称为文本去重,是一项旨在识别文本文档之间的相似性或重复性的技术或任务,它的主要目标是确定一个文本文档是否包含与其他文档相似或重复的内容,本文给大家介绍了利用python检测文本相似性的原理和方法,需要的朋友可以参考下2023-11-11 今天小编就为大家分享一篇利用pandas读取中文数据集的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-07-07
今天小编就为大家分享一篇利用pandas读取中文数据集的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-07-07 今天小编就为大家分享一篇Python计算一个点到所有点的欧式距离实现方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-07-07
今天小编就为大家分享一篇Python计算一个点到所有点的欧式距离实现方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-07-07










最新评论