
python爬虫今日热榜数据到txt文件的源码
更新时间:2021年02月23日 10:27:08 作者:一个超会写Bug的安太狼
这篇文章主要介绍了python爬虫今日热榜数据到txt文件的源码,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
今日热榜:https://tophub.today/
爬取数据及保存格式:
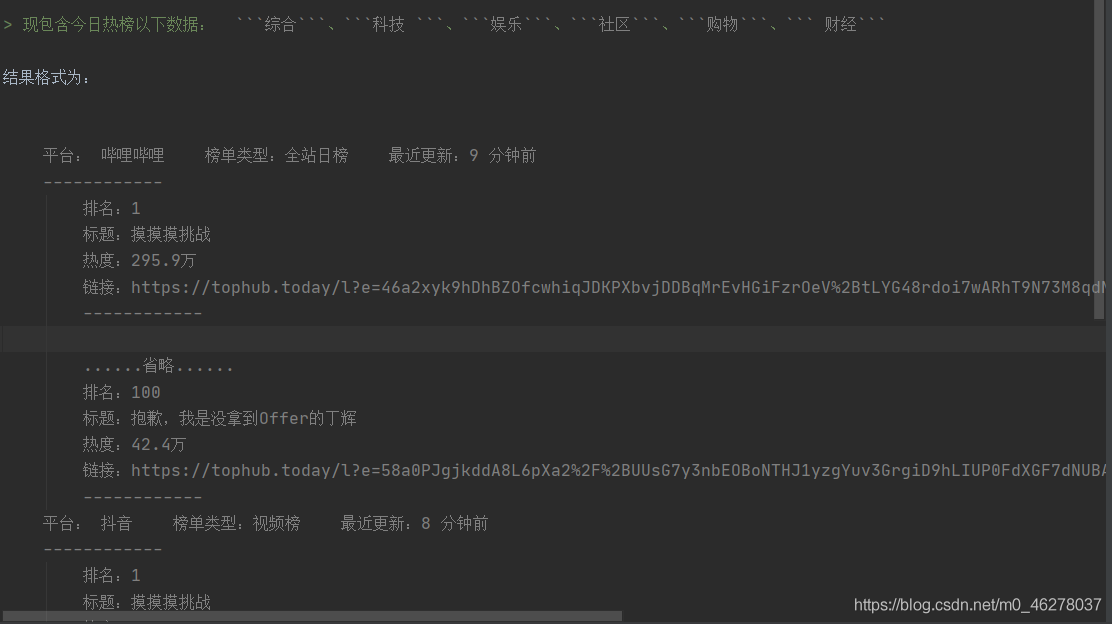
爬取后保存为.txt文件:
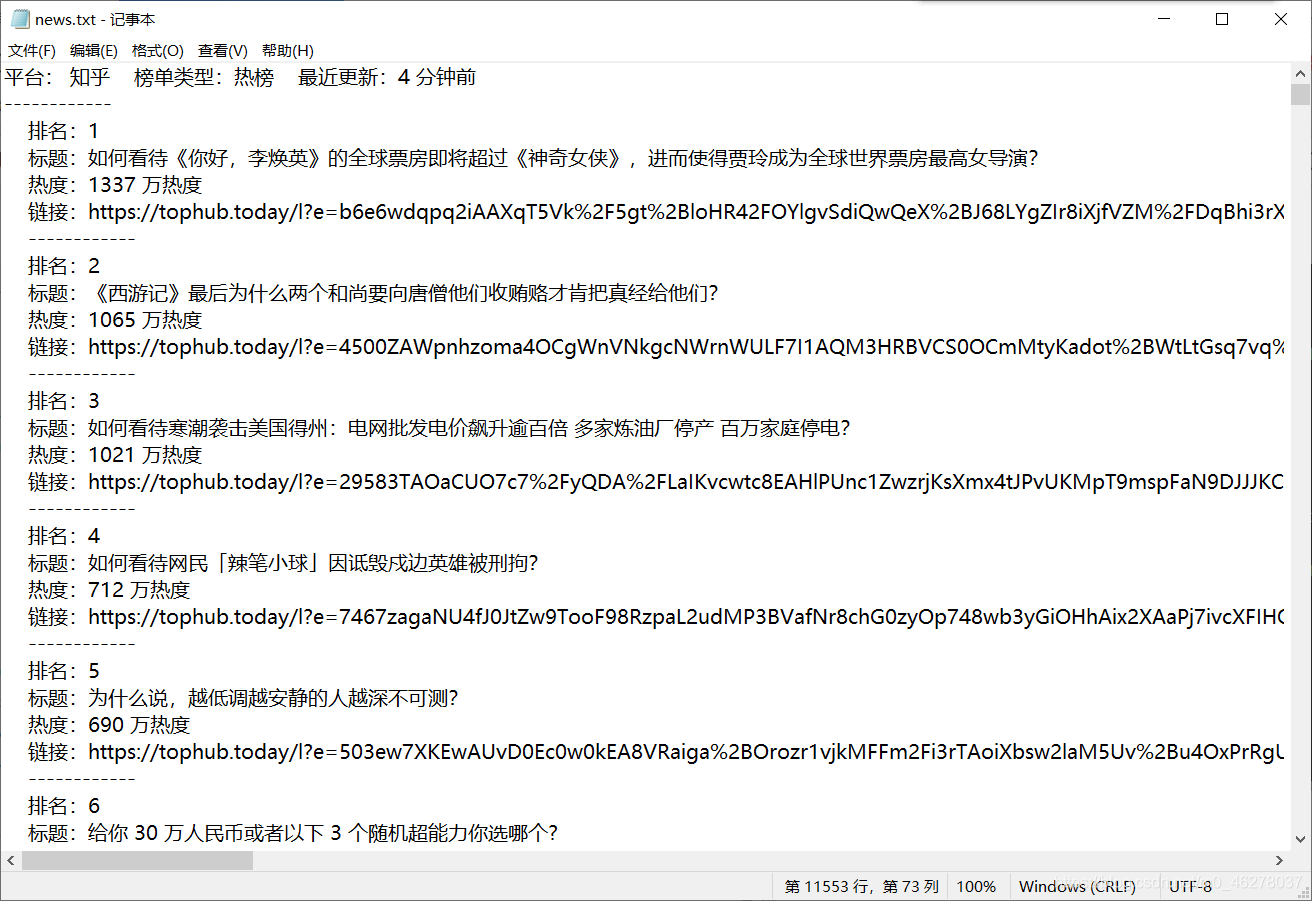
部分内容:
源码及注释:
import requests
from bs4 import BeautifulSoup
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
try:
r = requests.get(url,timeout = 30,headers=headers)
return r.text
except:
return "please inspect your url or setup"
def get_content(html,tag):
output = """ 排名:{}\n 标题:{} \n 热度:{}\n 链接:{}\n ------------\n"""
output2 = """平台:{} 榜单类型:{} 最近更新:{}\n------------\n"""
num=[]
title=[]
hot=[]
href=[]
soup = BeautifulSoup(html, 'html.parser')
con = soup.find('div',attrs={'class':'bc-cc'})
con_list = con.find_all('div', class_="cc-cd")
for i in con_list:
author = i.find('div', class_='cc-cd-lb').get_text() # 获取平台名字
time = i.find('div', class_='i-h').get_text() # 获取最近更新
link = i.find('div', class_='cc-cd-cb-l').find_all('a') # 获取所有链接
gender = i.find('span', class_='cc-cd-sb-st').get_text() # 获取类型
save_txt(tag,output2.format(author, gender,time))
for k in link:
href.append(k['href'])
num.append(k.find('span', class_='s').get_text())
title.append(str(k.find('span', class_='t').get_text()))
hot.append(str(k.find('span', class_='e').get_text()))
for h in range(len(num)):
save_txt(tag,output.format(num[h], title[h], hot[h], href[h]))
def save_txt(tag,*args):
for i in args:
with open(tag+'.txt', 'a', encoding='utf-8') as f:
f.write(i)
def main():
# 综合 科技 娱乐 社区 购物 财经
page=['news','tech','ent','community','shopping','finance']
for tag in page:
url = 'https://tophub.today/c/{}'.format(tag)
html = download_page(url)
get_content(html,tag)
if __name__ == '__main__':
main()
到此这篇关于python爬虫今日热榜数据到txt文件的源码的文章就介绍到这了,更多相关python爬虫今日热榜数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要为大家详细介绍了python requests+pywin32实现桌面壁纸切换,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-01-01
这篇文章主要为大家详细介绍了python requests+pywin32实现桌面壁纸切换,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-01-01 这篇文章主要介绍了Python从视频中提取音频的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-04-04
这篇文章主要介绍了Python从视频中提取音频的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-04-04 这篇文章主要介绍了pytorch中fuse_modules,fuse_known_modules将给定的模块列表mod_list中的一些常见模块进行融合,返回融合后的模块列表,本文通过实例代码详细讲解,需要的朋友可以参考下2023-05-05
这篇文章主要介绍了pytorch中fuse_modules,fuse_known_modules将给定的模块列表mod_list中的一些常见模块进行融合,返回融合后的模块列表,本文通过实例代码详细讲解,需要的朋友可以参考下2023-05-05
面向新手解析python Beautiful Soup基本用法
这篇文章主要介绍了面向新手解析python Beautiful Soup基本用法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07 这篇文章给大家分享Python基础实现与电脑对战的剪刀石头布小游戏,练习if while输入和输出,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友参考下吧2019-12-12
这篇文章给大家分享Python基础实现与电脑对战的剪刀石头布小游戏,练习if while输入和输出,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友参考下吧2019-12-12 今天小编就为大家分享一篇python抓取网站的图片并下载到本地的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05
今天小编就为大家分享一篇python抓取网站的图片并下载到本地的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05 这篇文章主要介绍了解决jupyter (python3) 读取文件遇到的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-03-03
这篇文章主要介绍了解决jupyter (python3) 读取文件遇到的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-03-03 echarts是百度开源的一个数据可视化JS库,主要用于数据可视化。pyecharts是一个用于生成Echarts图表的类库。实际上就是Echarts与Python的对接。本文将利用pyecharts库绘制象形柱状图,感兴趣的可以了解一下2022-01-01
echarts是百度开源的一个数据可视化JS库,主要用于数据可视化。pyecharts是一个用于生成Echarts图表的类库。实际上就是Echarts与Python的对接。本文将利用pyecharts库绘制象形柱状图,感兴趣的可以了解一下2022-01-01 谱聚类是从图论中演化出来的算法,它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来,今天通过本文给大家介绍Spectral clustering谱聚类算法的实现,感兴趣的朋友一起看看吧2022-04-04
谱聚类是从图论中演化出来的算法,它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来,今天通过本文给大家介绍Spectral clustering谱聚类算法的实现,感兴趣的朋友一起看看吧2022-04-04 快速排序和归并排序是两种常见的排序算法,在Python中有着重要的应用,本文将深入探讨这两种算法的原理和实现,并提供丰富的示例代码来说明它们的工作方式2024-01-01
快速排序和归并排序是两种常见的排序算法,在Python中有着重要的应用,本文将深入探讨这两种算法的原理和实现,并提供丰富的示例代码来说明它们的工作方式2024-01-01










最新评论