
python爬虫破解字体加密案例详解
本次案例以爬取起小点小说为例
案例目的:
通过爬取起小点小说月票榜的名称和月票数,介绍如何破解字体加密的反爬,将加密的数据转化成明文数据。
程序功能:
输入要爬取的页数,得到每一页对应的小说名称和月票数。
案例分析: 找到目标的url:
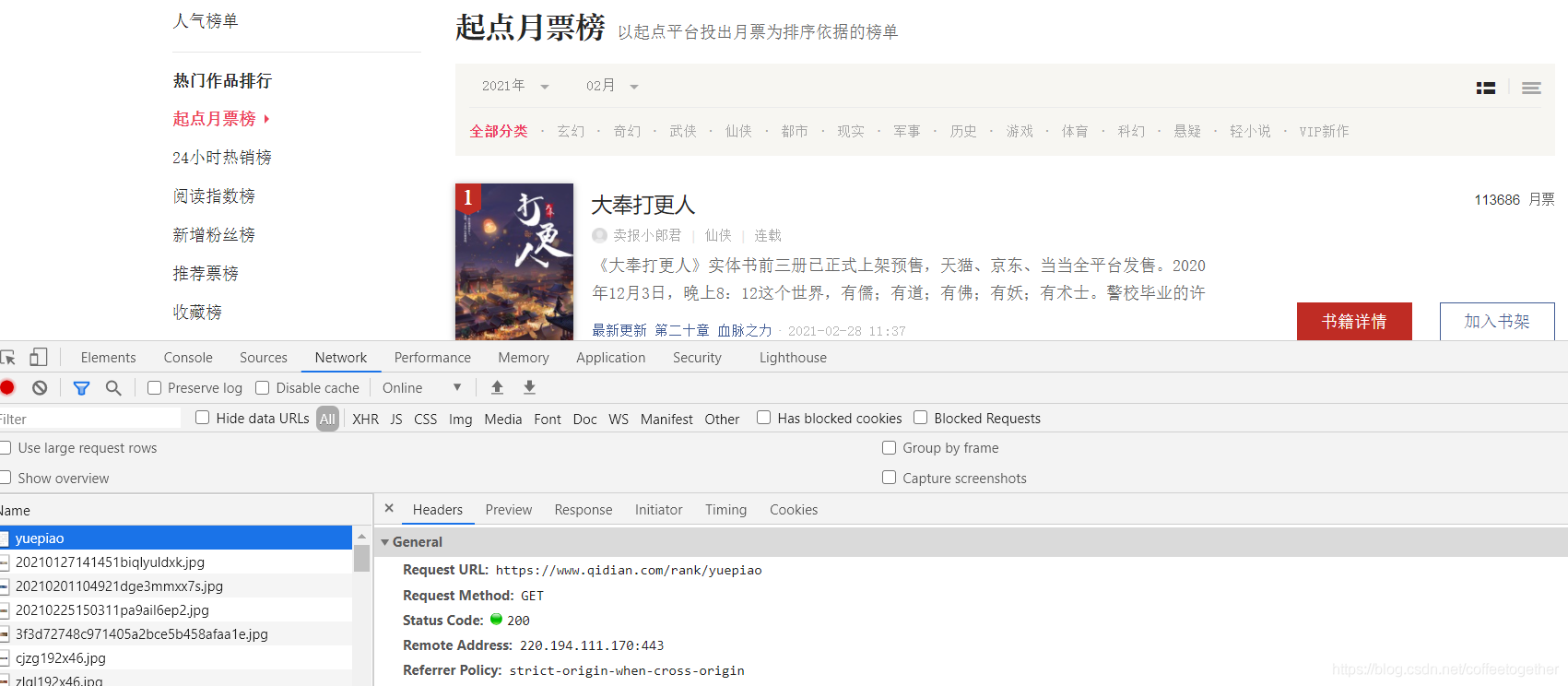
(右键检查)找到小说名称所在的位置:
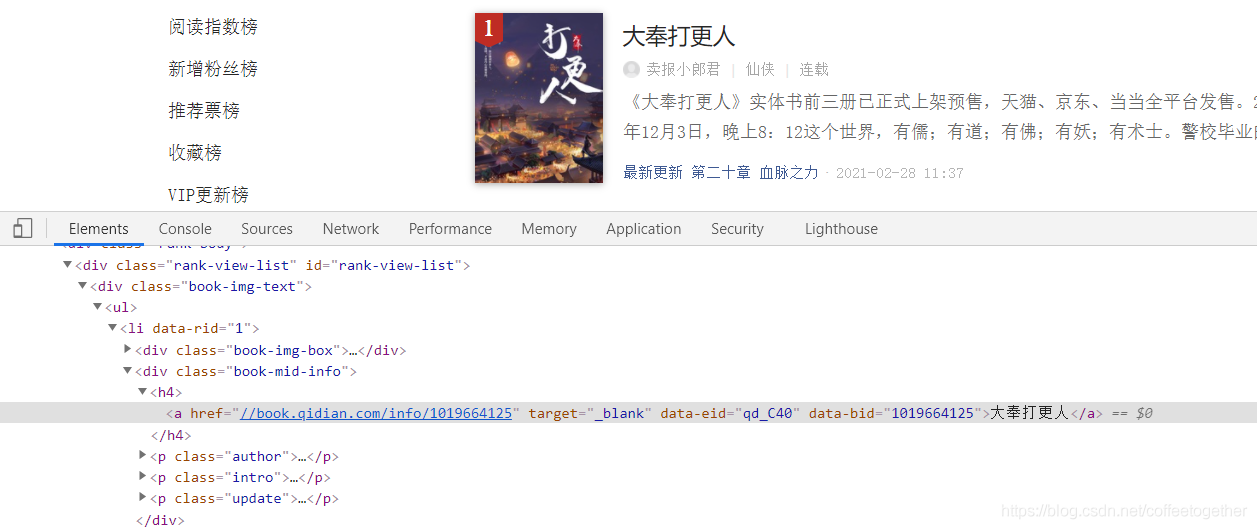
通过名称所在的节点位置,找到小说名称的xpath语法:
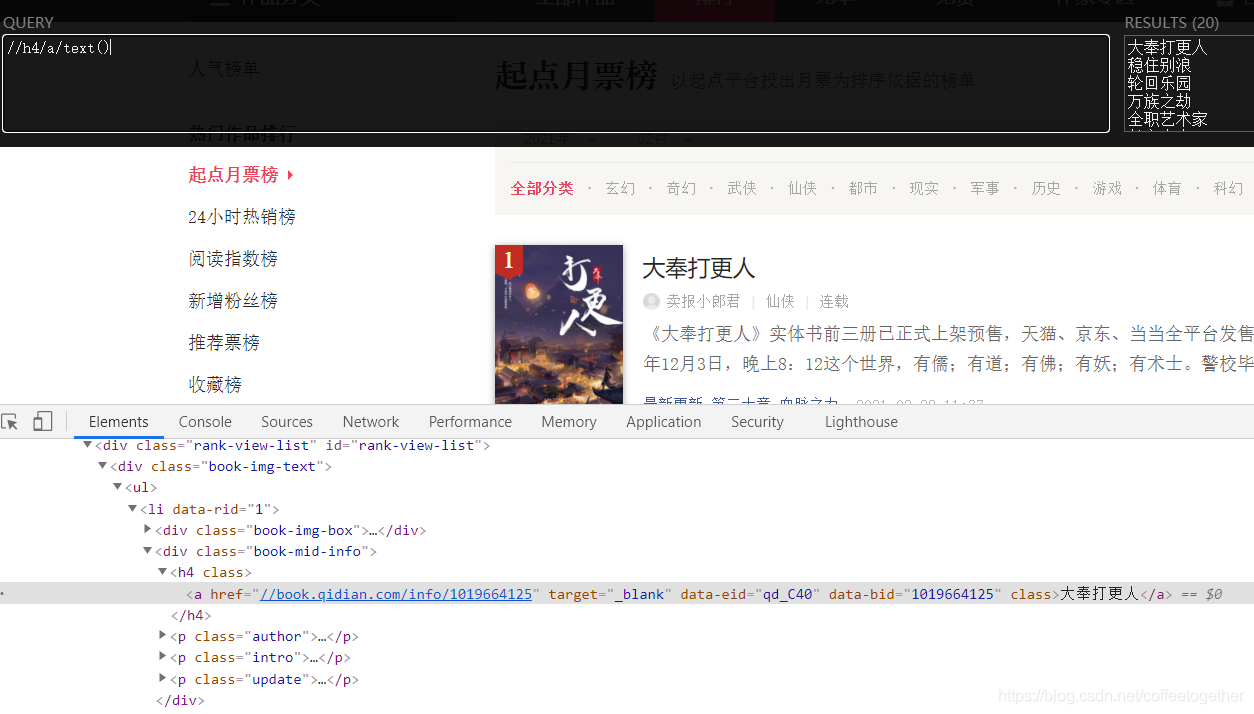
(右键检查)找到月票数所在的位置:
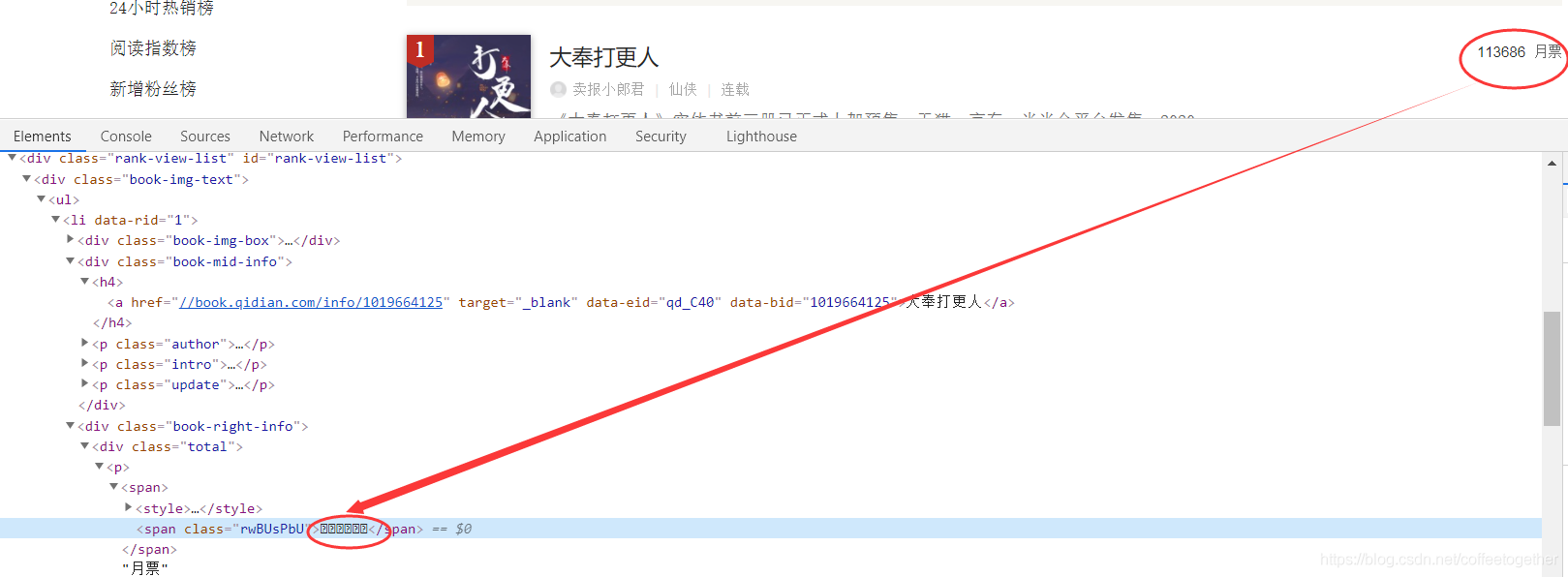
由上图发现,检查月票数据的文本,得到一串加密数据。
我们通过xpathhelper进行调试发现,无法找到加密数据的语法。因此,需要通过正则表达式进行提取。
通过正则进行数据提取。

正则表达式如下:

得到的加密数据如下:

破解加密数据是本次案例的关键:
既然是加密数据,就会有加密数据所对应的加密规则的Font文件。
通过找到Font字体文件中数据加密文件的url,发送请求,获取响应,得到加密数据的woff文件。
注:我们需要的woff文件,名称与加密月票数前面的class属性相同。
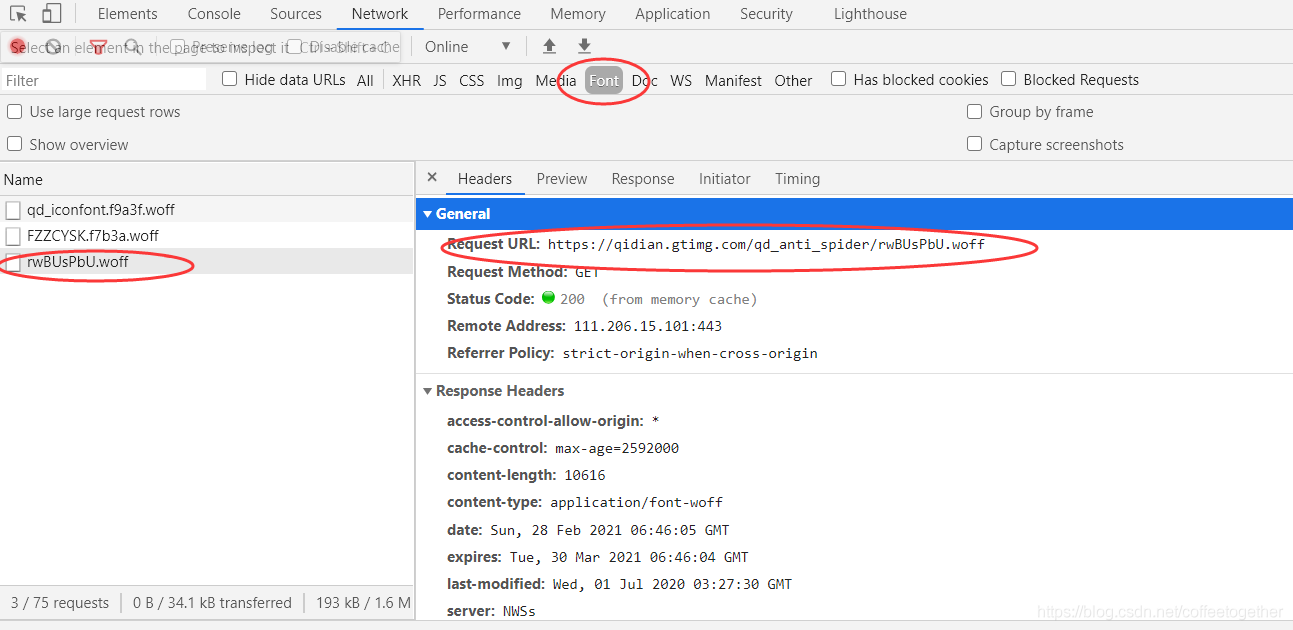
如下图,下载woff文件:
找到16进制的数字对应的英文数字。
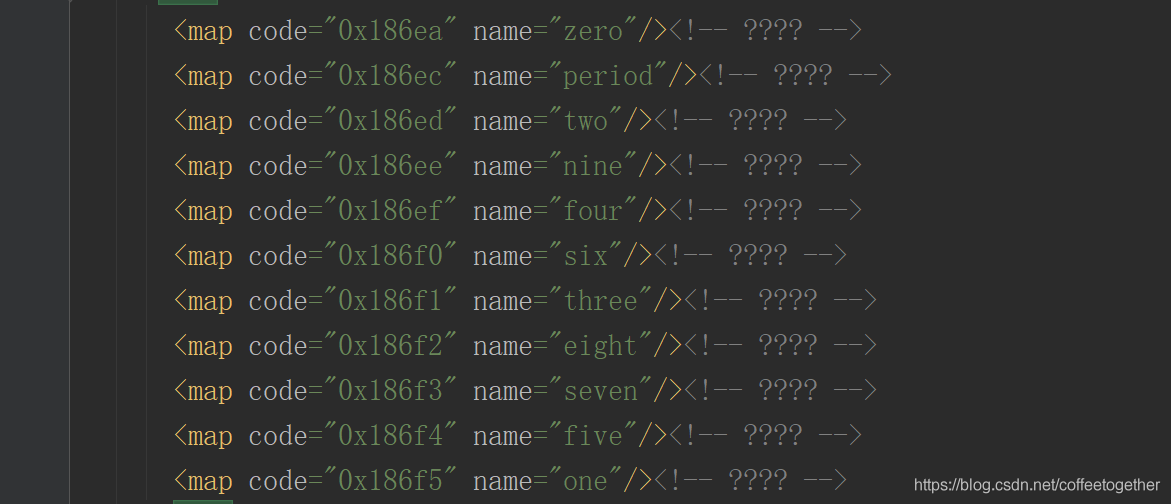
其次,我们需要通过第三方库TTFont将文件中的16进制数转换成10进制,将英文数字转换成阿拉伯数字。如下图:

解析出每个加密数据对应的对应的月票数的数字如下:

注意:
由于我们在上面通过正则表式获得的加密数据携带特殊符号
因此解析出月票数据中的数字之后,除了将特殊符号去除,还需把每个数字进行拼接,得到最后的票数。
最后,通过对比不同页的url,找到翻页的规律:



对比三个不同url发现,翻页的规律在于参数page
所以问题分析完毕,开始代码:
import requests
from lxml import etree
import re
from fontTools.ttLib import TTFont
import json
if __name__ == '__main__':
# 输入爬取的页数、
pages = int(input('请输入要爬取的页数:')) # eg:pages=1,2
for i in range(pages): # i=0,(0,1)
page = i+1 # 1,(1,2)
# 确认目标的url
url_ = f'https://www.qidian.com/rank/yuepiao?page={page}'
# 构造请求头参数
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
# 发送请求,获取响应
response_ = requests.get(url_,headers=headers)
# 响应类型为html问文本
str_data = response_.text
# 将html文本转换成python文件
py_data = etree.HTML(str_data)
# 提取文本中的目标数据
title_list = py_data.xpath('//h4/a[@target="_blank"]/text() ')
# 提取月票数,由于利用xpath语法无法提取,因此换用正则表达式,正则提取的目标为response_.text
mon_list = re.findall('</style><span class=".*?">(.*?)</span></span>',str_data)
print(mon_list)
# 获取字体反爬woff文件对应的url,xpath配合正则使用
fonturl_str = py_data.xpath('//p/span/style/text()')
font_url = re.findall(r"format\('eot'\); src: url\('(.*?)'\) format\('woff'\)",str_data)[0]
print(font_url)
# 获得url之后,构造请求头获取响应
headers_ = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'Referer':'https://www.qidian.com/'
}
# 发送请求,获取响应
font_response = requests.get(font_url,headers=headers_)
# 文件类型未知,因此用使用content格式
font_data = font_response.content
# 保存到本地
with open('加密font文件.woff','wb')as f:
f.write(font_data)
# 解析加密的font文件
font_obj = TTFont('加密font文件.woff')
# 将文件转成明文的xml文件
font_obj.saveXML('加密font文件.xml')
# 获取字体加密的关系映射表,将16进制转换成10进制
cmap_list = font_obj.getBestCmap()
print('字体加密关系映射表:',cmap_list)
# 创建英文转英文的字典
dict_e_a = {'one':'1','two':'2','three':'3','four':'4','five':'5','six':'6',
'seven':'7','eight':'8','nine':'9','zero':'0'}
# 将英文数据进行转换
for i in cmap_list:
for j in dict_e_a:
if j == cmap_list[i]:
cmap_list[i] = dict_e_a[j]
print('转换为阿拉伯数字的映射表为:',cmap_list)
# 去掉加密的月票数据列表中的符号
new_mon_list = []
for i in mon_list:
list_ = re.findall(r'\d+',i)
new_mon_list.append(list_)
print('去掉符号之后的月票数据列表为:',new_mon_list)
# 最终解析月票数据
for i in new_mon_list:
for j in enumerate(i):
for k in cmap_list:
if j[1] == str(k):
i[j[0]] = cmap_list[k]
print('解析之后的月票数据为:',new_mon_list)
# 将月票数据进行拼接
new_list = []
for i in new_mon_list:
j = ''.join(i)
new_list.append(j)
print('解析出的明文数据为:',new_list)
# 将名称和对应的月票数据放进字典,并转换成json格式及进行保存
for i in range(len(title_list)):
dict_ = {}
dict_[title_list[i]] = new_list[i]
# 将字典转换成json格式
json_data = json.dumps(dict_,ensure_ascii=False)+',\n'
# 将数据保存到本地
with open('翻页起小点月票榜数据爬取.json','a',encoding='utf-8')as f:
f.write(json_data)
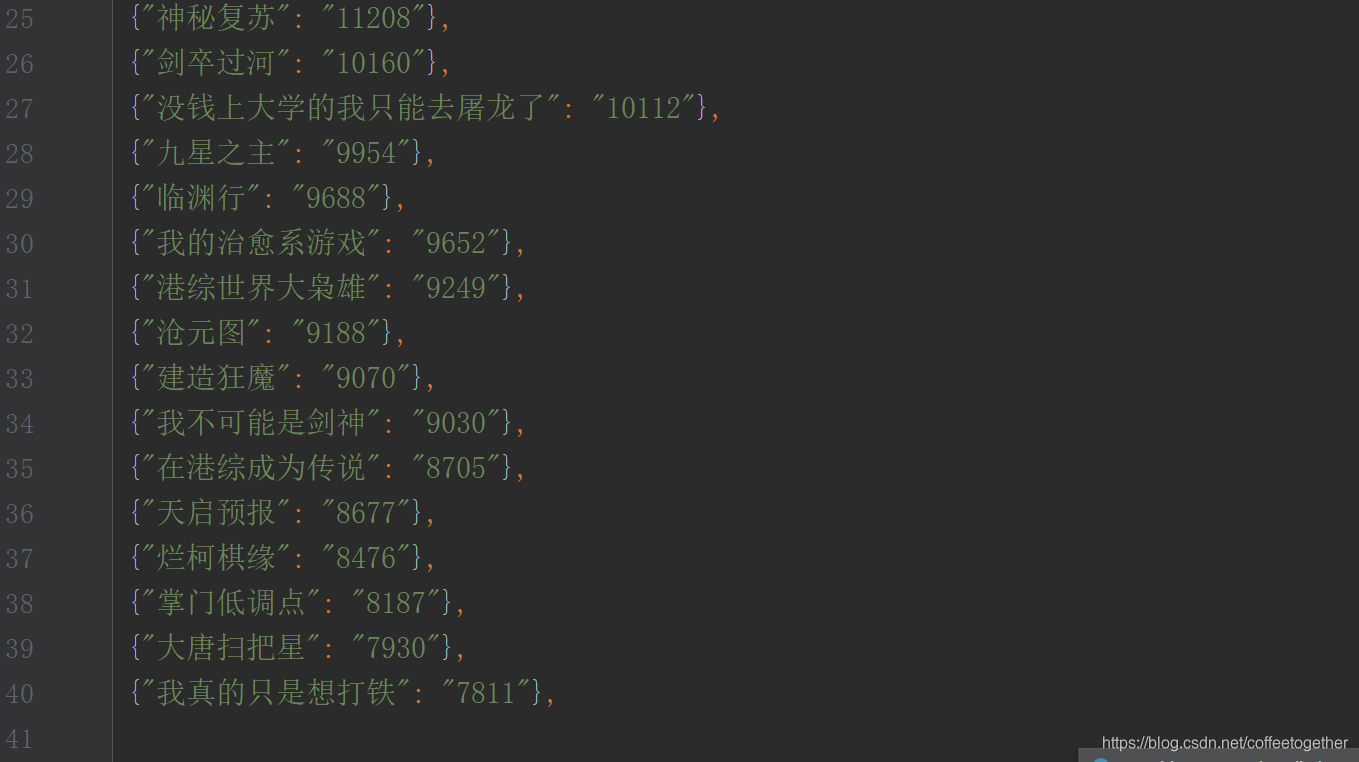
爬取了两页的数据,每一页包含20个数据
执行结果如下:
到此这篇关于python爬虫破解字体加密案例详解的文章就介绍到这了,更多相关python爬虫破解字体加密内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
- Python7个爬虫小案例详解(附源码)下篇
- Python7个爬虫小案例详解(附源码)中篇
- Python7个爬虫小案例详解(附源码)上篇
- 利用Python爬虫爬取金融期货数据的案例分析
- Python爬虫采集Tripadvisor数据案例实现
- Python Ajax爬虫案例分享
- Python爬虫入门案例之爬取去哪儿旅游景点攻略以及可视化分析
- Python爬虫入门案例之爬取二手房源数据
- Python爬虫入门案例之回车桌面壁纸网美女图片采集
- Python爬虫之Scrapy环境搭建案例教程
- 用Python爬虫破解滑动验证码的案例解析
- python爬虫系列网络请求案例详解
- python爬虫线程池案例详解(梨视频短视频爬取)
- python爬虫scrapy框架的梨视频案例解析
- python爬虫利器之requests库的用法(超全面的爬取网页案例)
- Python爬虫实战案例之爬取喜马拉雅音频数据详解
- Python爬虫Scrapy框架CrawlSpider原理及使用案例
- Python爬虫之对CSDN榜单进行分析
相关文章
 今天小编就为大家分享一篇Python2.7.10以上pip更新及其他包的安装教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06
今天小编就为大家分享一篇Python2.7.10以上pip更新及其他包的安装教程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-06-06 这篇文章主要介绍了Pycharm编辑器功能之代码折叠效果的实现代码,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-10-10
这篇文章主要介绍了Pycharm编辑器功能之代码折叠效果的实现代码,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-10-10 这篇文章主要为大家详细介绍了python实现BackPropagation算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-12-12
这篇文章主要为大家详细介绍了python实现BackPropagation算法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-12-12 这篇文章主要介绍了Python合并字符串的3种方法,本文讲解了使用+=操作符、使用%操作符、使用String的' '.join()方法3种方法,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了Python合并字符串的3种方法,本文讲解了使用+=操作符、使用%操作符、使用String的' '.join()方法3种方法,需要的朋友可以参考下2015-05-05 这篇文章主要介绍了Python多线程应用于自动化测试操作,结合实例形式分析了Python多线程基于Selenium进行自动化操作相关实现技巧,需要的朋友可以参考下2018-12-12
这篇文章主要介绍了Python多线程应用于自动化测试操作,结合实例形式分析了Python多线程基于Selenium进行自动化操作相关实现技巧,需要的朋友可以参考下2018-12-12
python GUI库图形界面开发之PyQt5信号与槽基础使用方法与实例
这篇文章主要介绍了python GUI库图形界面开发之PyQt5信号与槽基础使用方法与实例,需要的朋友可以参考下2020-03-03 今天小编就为大家分享一篇Numpy 改变数组维度的几种方法小结,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-08-08
今天小编就为大家分享一篇Numpy 改变数组维度的几种方法小结,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-08-08 这篇文章主要介绍了python批量处理打开多个文件,文章围绕主题的相关内容展开详细的内容介绍,具有一定的参考价值,需要的朋友可以参考一下2022-06-06
这篇文章主要介绍了python批量处理打开多个文件,文章围绕主题的相关内容展开详细的内容介绍,具有一定的参考价值,需要的朋友可以参考一下2022-06-06
python爬取w3shcool的JQuery课程并且保存到本地
本文主要介绍python爬取w3shcool的JQuery的课程并且保存到本地的方法解析。具有很好的参考价值。下面跟着小编一起来看下吧2017-04-04 如果想要批量把Word文档转换为PDF文档,我们可以使用第三方模块win32com,本文就来详细的介绍一下Python批量将Word文件转为PDF文件的实现示例,感兴趣的可以了解一下2023-08-08
如果想要批量把Word文档转换为PDF文档,我们可以使用第三方模块win32com,本文就来详细的介绍一下Python批量将Word文件转为PDF文件的实现示例,感兴趣的可以了解一下2023-08-08










最新评论