
python学习之可迭代对象、迭代器、生成器
Iterable – 可迭代对象
能够逐一返回其成员项的对象。 可迭代对象的例子包括所有序列类型 (例如 list, str 和 tuple) 以及某些非序列类型例如 dict, 文件对象以及定义了__iter__()方法或是实现了序列语义的__getitem__() 方法的任意自定义类对象。
可迭代对象可用于 for 循环以及许多其他需要一个序列的地方(zip()、map() …)。当一个可迭代对象作为参数传给内置函数 iter() 时,它会返回该对象的迭代器。这种迭代器适用于对值集合的一次性遍历。在使用可迭代对象时,你通常不需要调用 iter() 或者自己处理迭代器对象。for 语句会为你自动处理那些操作,创建一个临时的未命名变量用来在循环期间保存迭代器
判断对象是否为可迭代对象:可以使用isinstance与collections模块的Iterable类型
#分别对python的各种数据类型进行判断
from collections import Iterable
a = 123
isinstance(a,Iterable) >>> False
a = 'abc'
isinstance(a,Iterable) >>> True
a = (1,2,3)
isinstance(a,Iterable) >>> True
a = [1,2,3]
isinstance(a,Iterable) >>> True
a = {'name':'wwl','age':24,'sex':'男'}
isinstance(a,Iterable) >>> True
a = {1,2,3}
isinstance(a,Iterable) >>> True
#可以看到字符串,元组,列表,字典,集合是可迭代对象;数字不是
通过上面我们得到可迭代对象有:字符串,元组,列表,字典,集合
我们可以使用内置的dir()函数对python数据类型进行操作,会发现可迭代对象(str,tuple,list,dict,set)均实现了__iter__方法,而不是可迭代对象的int类型则没有__iter__方法
dir(int) ['...(省略)', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__','...(省略)' ] dir(str) ['...(省略)', '__iter__', '...(省略)'] dir(tuple) ['...(省略)', '__iter__', '...(省略)'] dir(list) ['...(省略)', '__iter__', '...(省略)'] dir(dict) ['...(省略)', '__iter__', '...(省略)'] dir(set) ['...(省略)', '__iter__', '...(省略)']
到底是不是__iter__方法决定对象是否是可迭代对象呢?我们可以验证一下:
#自定义两个类:A类和B类,其中B类实现__iter__方法,A类则没有 from collections import Iterable class A(): ... def __init__(self): ... pass ... class B(): def __init__(self): pass def __iter__(self): return self #生成两个实例化对象:a和b a = A() b = B() #可以看到实现__iter__方法的b对象是可迭代对象,而a对象不是 isinstance(a,Iterable) >>> False isinstance(b,Iterable) >>> True
特殊情况:实现了__getitem__方法的序列也是可迭代对象
sequence – 序列
一种 iterable,它支持通过__getitem__() 特殊方法来使用整数索引进行高效的元素访问,并定义了一个返回序列长度的__len__() 方法。内置的序列类型有list、str、tuple 和 bytes。注意虽然 dict 也支持__getitem__() 和__len__(),但它被认为属于映射而非序列,因为它查找时使用任意的 immutable 键而非整数。
#自定义一个实现__getitem__方法的序列 class A(): def __init__(self,*args): self.args = args def __getitem__(self,i): return self.args[i] def __len__(self): num = 0 while True: try: self.args[num] num += 1 except: return num a = A(1,2,3,'ss','dd') #可以看到实例化后的对象是可以通过for...in进行循环访问的,表示其是可迭代对象。 for i in range(len(a)): print(a[i]) >>> 1 2 3 ss dd #我们使用collections模块的Iterable进行判断: from collections import Iterable,Iterator isinstance(a,Iterable) >>> False #结果出乎意料,判定对象a不是可迭代对象,为什么呢? #因为collections模块的Iterable自动忽略了对象的__getitem__方法,只根据对象是否有__iter__方法进行判断。一般来说,标准的序列均实现了__iter__方法。 #既然上面方法无法判断具有__getitem__方法的序列是否是可迭代对象,那又该如何判断呢? #可以使用iter()函数,如果不报错,说明是可迭代对象,报错就不是 b = iter(a) isinstance(b,Iterable) >>> True isinstance(b,Iterator) >>> True
Iterator – 迭代器:内部实现__iter__和__next__方法的对象
用来表示一连串数据流的对象。重复调用迭代器的 next() 方法(或将其传给内置函数 next())将逐个返回流中的项。当没有数据可用时则将引发 StopIteration 异常。到这时迭代器对象中的数据项已耗尽,继续调用其 next() 方法只会再次引发 StopIteration 异常。迭代器必须具有 iter() 方法用来返回该迭代器对象自身,因此迭代器必定也是可迭代对象,可被用于其他可迭代对象适用的大部分场合。一个显著的例外是那些会多次重复访问迭代项的代码。容器对象(例如 list)在你每次向其传入 iter() 函数或是在 for 循环中使用它时都会产生一个新的迭代器。如果在此情况下你尝试用迭代器则会返回在之前迭代过程中被耗尽的同一迭代器对象,使其看起来就像是一个空容器。
判断对象是否为迭代器:使用isinstance与collections模块的Iterator类型
from collections import Iterable,Iterator #创建两个类:B类和C类,B类实现了__iter__方法,C类实现了__iter__和__next__方法 class B(): def __init__(self): pass def __iter__(self): return self class C(): def __init__(self): pass def __iter__(self): return self def __next__(self): return 123 #实例化两个对象 b = B() c = C() #可以看到b对象是可迭代对象,却不是迭代器;c对象既是可迭代对象,又是迭代器. isinstance(b,Iterable) >>> True isinstance(b,Iterator) >>> False isinstance(c,Iterator) >>> True isinstance(c,Iterable) >>> True
生成迭代器有两种方法:
1.使用内置的iter(object[, sentinel])函数;
返回迭代器对象。根据第二个参数的存在,第一个参数的解释非常不同。如果没有第二个参数,对象必须是支持迭代协议的集合对象(iter()方法),或者必须支持序列协议(getitem()方法,整数参数从0开始)。如果它不支持这两个协议中的任何一个,则会引发TypeError。如果给出了第二个参数sentinel,那么object必须是可调用的对象。在这种情况下创建的迭代器将调用对象,每次调用它的__next __()方法时都不带参数;如果返回的值等于sentinel,则将引发StopIteration,否则将返回该值。
iter()的第一种形式:不带第二个参数,第一个参数表示可迭代对象(具有__iter__()方法或者__getitem__()方法)
#自定义两个类,一个支持__iter__()方法,一个支持__getitem__()方法 #1.定义一个支持迭代协议的集合对象: class A(): def __init__(self): pass def __iter__(self): self.num = 0 return self def __next__(self): if self.num < 10: N = self.num self.num += 1 return N else: raise StopIteration a = A() b = iter(a) from collections import Iterable,Iterator #由于A类中我们定义的__iter__()函数是返回自己,同时定义了自身的__next__()方法,所以对象a既是可迭代对象,又是迭代器。 isinstance(a,Iterable) >>> True isinstance(a,Iterator) >>> True #同时我们可以看到对象a经过iter()方法后生成的b对象是迭代器。 isinstance(b,Iterator) >>> True isinstance(b,Iterable) >>> True #定义一个支持序列协议的对象 class B(): def __init__(self,*args): self.args = args def __getitem__(self,i): return self.args[i] def __len__(self): num = 0 while True: try: self.args[num] num += 1 except: return num b = B() c = iter(b) #由于b对象定义的是__getitem__()方法,所以无法使用collections模块对b对象进行判断。 #这里我们只对使用了iter()方法后生成的c对象进行判断 isinstance(c,Iterable) >>> True isinstance(c,Iterator) >>> True #可以看到使用了iter()方法后生成的对象c是迭代器
iter()的第二种形式:带第二个参数,第一个参数表示可调用对象,当返回值为第二个参数时,触发StopIteration
class A():
def __init__(self):
self.num = 1
def __call__(self):
x = self.num
self.num += 1
return x
a = A()
b = iter(a,5)
from collections import Iterable,Iterator
#我们可以看到a对象既不是可迭代对象也不是迭代器,但通过iter()方法返回的对象b确实迭代器
isinstance(a,Iterable) >>> False
isinstance(a,Iterator) >>> False
isinstance(b,Iterator) >>> True
isinstance(b,Iterable) >>> True
#通过for...in循环遍历打印(每次循环都调用__call__()方法,直至返回值等于5,触发StopIteration停止迭代)
for i in b:
print(i) >>> 1 2 3 4
#iter()的第二种形式的一个有用的应用是构建块读取器。例如,从二进制数据库文件中读取固定宽度的块,直到到达文件结尾:
from functools import partial
with open('mydata.db', 'rb') as f:
for block in iter(partial(f.read, 64), b''):
process_block(block)
2.直接调用可迭代对象的__iter__方法;
#定义__iter__()方法,可以返回自己,但自己要定义__next__()方法;也可以返回其他对象的迭代器 #第一种:返回自身,同时定义自身的__next__()方法 class A(): def __init__(self): pass def __iter__(self): self.num = 0 return self def __next__(self): if self.num < 10: N = self.num self.num += 1 return N else: raise StopIteration a = A() b = a.__iter__() from collections import Iterable,Iterator #由于A类中我们定义的__iter__()函数是返回自己,同时定义了自身的__next__()方法,所以对象a既是可迭代对象,又是迭代器。 isinstance(a,Iterable) >>> True isinstance(a,Iterator) >>> True #同时我们可以看到对象a经过iter()方法后生成的b对象是迭代器。 isinstance(b,Iterable) >>> True isinstance(b,Iterator) >>> True #第二种:返回其他对象的迭代器 class A(): def __init__(self): pass def __iter__(self): self.num = 0 return b class B(A): def __next__(self): if self.num < 10: N = self.num self.num += 1 return N else: raise StopIteration #实例化两个对象:a和b,当调用对象a的__iter__()方法时,返回对象b,B继承于A类,所以b对象是一个迭代器。 a = A() b = B() #调用a的__iter__()方法 c = a.__iter__() from collections import Iterable,Iterator #由于对象a不具备__next__()方法,因此仅仅是一个可迭代对象 isinstance(a,Iterable) >>> True isinstance(a,Iterator) >>> False #但是调用对象a的__iter()方法生成的c,同时具备__iter__()和__next__()方法,是一个迭代器。 isinstance(c,Iterable) >>> True isinstance(c,Iterator) >>> True
上面两种方式表示可以生成迭代器,但并不是使用这两个函数就一定生成迭代器,这取决于运行这两个函数返回的是什么
#iter()函数:其运行机制是寻找对象中的__iter__()方法,运行并返回结果,如果__iter__()方法返回的不是迭代器,则此方法会报错;如果没有此方法,则寻找__getitem__()方法。 class A(): def __init__(self): pass def __iter__(self): return 1 #我们知道数字1不是迭代器,此函数返回的是一个非迭代器 a = A() b = iter(a) Traceback (most recent call last): File "<input>", line 10, in <module> TypeError: iter() returned non-iterator of type 'int' #直接调用__iter__()方法:如果想通过调用此方法生成迭代器,只能定义在此函数下返回一个迭代器;如果定义返回的不是迭代器,调用此方法是不会生成迭代器的。 class A(): def __init__(self): pass def __iter__(self): return 1 a = A() #直接调用__iter__()方法 b = a.__iter__() #我们可以看到返回的是1,而不是迭代器,只有当你定义返回迭代器时,调用此方法才会返回迭代器 print(b) >>> 1
判断对象是否是可迭代对象:
1.collections模块的Iterable类型,使用isinstance()判断(此方法不太准)
#我们定义一个类:具有__iter__()方法,但返回的不是迭代器 class A(): def __init__(self): pass def __iter__(self): return 1 a = A() from collections import Iterable #我们使用isinstance()结合collections看一下:会发现此方法认为他是一个可迭代对象 isinstance(a,Iterable) >>> True #我们使用for...in进行循环访问,发现并不能 for i in a: print(i) Traceback (most recent call last): File "<input>", line 1, in <module> TypeError: iter() returned non-iterator of type 'int' #接下来,我们再定义一个类:具有__iter__()方法和__next__()方法,但返回的不是迭代器 class A(): def __init__(self): pass def __iter__(self): pass def __next__(self): pass a = A() from collections import Iterator #我们使用isinstance()结合collections看一下:会发现此方法认为他是一个迭代器 isinstance(a,Iterator) >>> True #我们使用for...in进行循环访问,发现并不能 for i in a: print(a) Traceback (most recent call last): File "<input>", line 1, in <module> TypeError: iter() returned non-iterator of type 'NoneType'
2.使用iter()内置函数进行判断:
class A(): def __init__(self): pass def __iter__(self): return 1 a = A() #使用iter()函数如果报错,则不是可迭代对象,如果不报错,则是可迭代对象 b = iter(a) Traceback (most recent call last): File "<input>", line 1, in <module> TypeError: iter() returned non-iterator of type 'int'
3.使用for…in方法进行遍历,如果可以遍历,即为可迭代对象
#for...in循环的实质是:先调用对象的__iter__()方法,返回一个迭代器,然后不断的调用迭代器的__next__()方法。 class A(): def __init__(self): pass def __iter__(self): self.num = 0 return self def __next__(self): if self.num < 10: N = self.num self.num += 1 return N else: raise StopIteration a = A() for i in a: print(i) >>> 0 1 2 3 4 5 6 7 8 9 #等同于:先调用对象的__iter__()方法,返回一个迭代器,然后不断的调用迭代器的__next__()方法,调用完返回StopIteration,结束迭代 b = iter(a) while True: try: next(b) except: raise StopIteration 0 1 2 3 4 5 6 7 8 9 Traceback (most recent call last): File "<stdin>", line 3, in <module> File "<stdin>", line 13, in __next__ StopIteration
经过上面三种判断方法的分析,我们可以得出一些结论:
1.collection模块的Iterable,Iterator类型并不能准确的判断对象是否是可迭代对象,或者是否是迭代器,它的判断原理只是检查对象内部是否定义了__iter__()和__next__()方法,而不注重这两个函数所返回的内容。
2.相比于collections模块,iter()函数则与其不同,它更注重__iter__()函数返回的内容,如果返回的是迭代器,则iter()的参数即为可迭代对象,否则,使用iter()函数会报错。此方法比较常用,也相对好用。
3.for…in循环方法,也可以用来判断对象是否是可迭代对象,此方法本质就是调用对象__iter__()和__next__()方法,他同样注重函数的返回内容。
经过以上种种实例的分析,我们发现仅仅具有__iter__()和__next__方法并不能算真正意义上的可迭代对象或者迭代器,如果不注重方法返回的内容,实例化的对象却不能进行迭代访问,又怎么能称为可迭代对象和迭代器呢?因此我们在这里对可迭代对象和迭代器进行重新定义
| 类型 | 定义 | 判断方法 |
|---|---|---|
| - 可迭代对象 | 内部定义了__iter__()方法且返回迭代器,可以返回自己也可以返回其他迭代器,如果返回自己,则自己还必须定义__next__()方法;也可以是定义__getitem__()方法的序列,整数参数可以从0进行索引,一般来说,标准的序列均定义了__iter__()方法,所以序列也是符合可迭代对象的要求的 | 可以使用iter()方法进行判断,将对象作为参数输入,如果不报错则为可迭代对象;反之,则不是。除此之外,使用for循环进行遍历,也可以识别;还有就是能够看到对象的源码,直接根据定义进行判断 |
| 迭代器 | 内部定义了__iter__()方法,与可迭代对象不同的是,对象的__iter__()方法必须返回的是自己,同时自己定义了__next__()方法 | 如果是迭代器,是可以调用__next__()方法的,调用所有元素后,抛出StopIteration错误;判断Iterator最好是能够看到源码,直接根据定义判断。 |
generator – 生成器:
生成器是一个用于创建迭代器的简单而强大的工具。它们的写法类似于标准的函数,但当它们要返回数据时会使用yield 语句。每次在生成器上调用next() 时,它会从上次离开的位置恢复执行(它会记住上次执行语句时的所有数据值)。
可以用生成器来完成的操作同样可以用基于类的迭代器来完成。 但生成器的写法更为紧凑,因为它会自动创建 iter() 和 next() 方法。
另一个关键特性在于局部变量和执行状态会在每次调用之间自动保存。 这使得该函数相比使用 self.index 和 self.data 这种实例变量的方式更易编写且更为清晰。
除了会自动创建方法和保存程序状态,当生成器终结时,它们还会自动引发 StopIteration。 这些特性结合在一起,使得创建迭代器能与编写常规函数一样容易。
def A(): yield 1 yield 2 a = A() print(a) #可以看出a显示的是一个生成器对象 <generator object A at 0x7f4f94409eb8> #我们使用dir()函数看一下生成器的方法: dir(a) ['省略', '__iter__', '省略', '__next__', 'send', 'throw','省略'] #可以看到生成器里面自动完成了对__iter__()和__next__()方法的定义 #我们调用对象的__iter__()方法 print(iter(a)) >>> <generator object A at 0x7f4f94409eb8> print(a) >>> <generator object A at 0x7f4f94409eb8> #可以看到,调用__iter__()方法,返回的是对象自己 #我们调用对象的__next__()方法 next(a) >>> 1 #可以看到,再次调用next()方法,是在上次的基础上继续运行的,返回的是2,而不是像普通函数一样,从头开始重新运行 next(a) >>> 2 next(a) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration #可以看到生成器a调用next()方法后生成下一个元素,同时当元素耗尽时,抛出StopIteration错误,这和迭代器完全相似 #生成器完全符合迭代器的要求,所以生成器也属于迭代器
除了定义一个yield函数外,还可以利用推导式生成一个生成器
#一般的推导式有列表推导式和字典推导式,与两者不同,生成器的推导式是写在小括号中的,而且只能是比较简单的生成器,比较复杂的生成器一般是写成yield函数的形式. a = (i for i in range(5)) print(a) <generator object <genexpr> at 0x03CFDE28>
| 类型 | 定义 | 判断方法 |
|---|---|---|
| 生成器 | 使用yield的函数,或者类似(i for i in range(5))这样的推导式,自动实现__iter__()和__next__()方法 | 根据定义判断 |
1.生成器是一种特殊的迭代器,其内部自动实现__iter__()和__next__()方法,可用for循环遍历输出;
2.迭代器一定是可迭代对象,但可迭代对象不一定是迭代器。
迭代器存在的意义:
在说明迭代器之前,我们需要引入一个容器的概念。什么是容器?容器是众多对象(在python中对象的抽象是类class)的集合,根据存储方式不同,python可分为四种容器:
列表(list):对象以队列方式进行存储 元组(tuple):对象以队列方式进行存储,和列表一样,只是存储数据后,不可更改, 集合(set):对象以无序的方式进行存储 字典(dict):对象以键值对映射的方式存储数据
在编程中,最常见的操作就是从这些容器中拿出数据。而容器一般是不具备取出数据的功能的。我们平时取出数据的操作实际上是先经过__iter__()方法转为迭代器,之后再通过__next__()方法拿取的(参考for循环,map(),filter())。可以说迭代器赋予了容器取出数据的能力,但迭代器每次调用__next__()方法只能取出一个数据,这种方法显然是很笨拙的,于是引入for循环,每次循环自动调用__next__()方法,这使得访问容器中的对象变得十分方便。
个人理解:迭代器的存在类似指针。
迭代器具有__iter__()方法就好比具备存放指针的资格,而__next__()方法,表示指针调度的规则。每次访问容器中的元素,首先调用__iter__()方法在容器元素头部放一个指针,此指针不指向任何元素,位于所有元素前面,为待操作状态,随时准备被调用。然后通过__next__()方法制定的规则来调度这个指针,使其指向不同的对象,指针所指之处便是所访问对象。此指针默认有一些属性:只能向前,不能回退,当没有元素时,抛出StopIteration,过程结束。
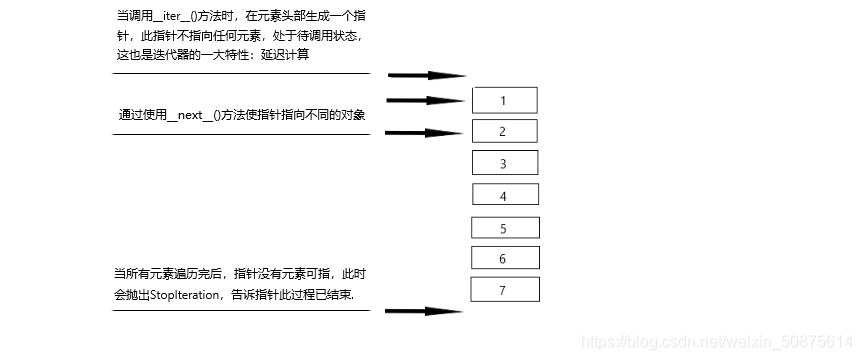
使用迭代器一个明显的优势是:减少内存占用
不使用迭代器:如果我们想访问一个容器中的所有元素,就需要将所有的元素都加载到内存中,然后一次性打印,对于少量元素来说,这无关紧要,但当数据量非常大时,这种做法将占用很大的内存,影响程序性能。
使用迭代器:我们访问一个容器中的所有元素,不会将所有元素都加载出来,而是一个一个的加载,然后打印,这样会极大的减少内存的占用。
生成器存在的意义:
生成器的存在,给我更多的感受是:简化迭代器的生成。我们只需使用yield关键字,将数据处理的逻辑写出,对象内部将自动完成对__iter__()和__next__()方法的定义,使我们不用再耗费精力处理实例变量,以及自己定义__iter__()和__next__()方法。
特性:
1.生成器中的成员并不存在,使用一个成员立刻用yield生成一个成员(按需计算)
2.生成器很节省内存,因为是立刻生成的,所以耗费CPU进行计算;
到此这篇关于python学习之可迭代对象、迭代器、生成器的文章就介绍到这了,更多相关python可迭代对象、迭代器、生成器内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

苹果Macbook Pro13 M1芯片安装Pillow的方法步骤
Pillow作为python的第三方图像处理库,提供了广泛的文件格式支持,本文主要介绍了苹果Macbook Pro13 M1芯片安装Pillow,具有一定的参考价值,感兴趣的可以了解一下2021-11-11 这篇文章主要介绍了Python 运行.py文件和交互式运行代码的区别详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07
这篇文章主要介绍了Python 运行.py文件和交互式运行代码的区别详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07 本文主要介绍了Pandas中MultiIndex选择并提取任何行和列,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02
本文主要介绍了Pandas中MultiIndex选择并提取任何行和列,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02 这篇文章主要介绍了关于python3中setup.py小概念解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了关于python3中setup.py小概念解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08 作为数据分析师,我们需要经常制作统计分析图表。但是报表太多的时候往往需要花费我们大部分时间去制作报表。本文将利用Python实现报表自动化并发送到邮箱,需要的可以参考一下2022-07-07
作为数据分析师,我们需要经常制作统计分析图表。但是报表太多的时候往往需要花费我们大部分时间去制作报表。本文将利用Python实现报表自动化并发送到邮箱,需要的可以参考一下2022-07-07 本文主要介绍了python实现定时器的5种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03
本文主要介绍了python实现定时器的5种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-03-03 今天小编就为大家分享一篇Python过滤txt文件内重复内容的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-10-10
今天小编就为大家分享一篇Python过滤txt文件内重复内容的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-10-10 zip函数接受任意多个可迭代对象作为参数,将对象中对应的元素打包成一个tuple,然后返回一个可迭代的zip对象.这个可迭代对象可以使用循环的方式列出其元素,若多个可迭代对象的长度不一致,则所返回的列表与长度最短的可迭代对象相同.2018-06-06
zip函数接受任意多个可迭代对象作为参数,将对象中对应的元素打包成一个tuple,然后返回一个可迭代的zip对象.这个可迭代对象可以使用循环的方式列出其元素,若多个可迭代对象的长度不一致,则所返回的列表与长度最短的可迭代对象相同.2018-06-06 这篇文章主要介绍了sklearn和keras的数据切分与交叉验证的实例详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06
这篇文章主要介绍了sklearn和keras的数据切分与交叉验证的实例详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-06-06 学好Python和条件语句,将方便有效提高工作效率,这篇文章主要给大家介绍了关于python条件语句的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考下2021-08-08
学好Python和条件语句,将方便有效提高工作效率,这篇文章主要给大家介绍了关于python条件语句的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考下2021-08-08










最新评论