
python实现线性回归的示例代码
更新时间:2024年04月30日 09:34:16 作者:邀_灼灼其华
本文主要介绍了python实现线性回归的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
1、导入第三方库
import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split import numpy as np
2、生成数据集
def generateData():
X = []
y = []
for i in range(0, 100):
tem_x = []
tem_x.append(i)
X.append(tem_x)
tem_y = []
tem_y.append(i + 2.128 + np.random.uniform(-15,15))
y.append(tem_y)
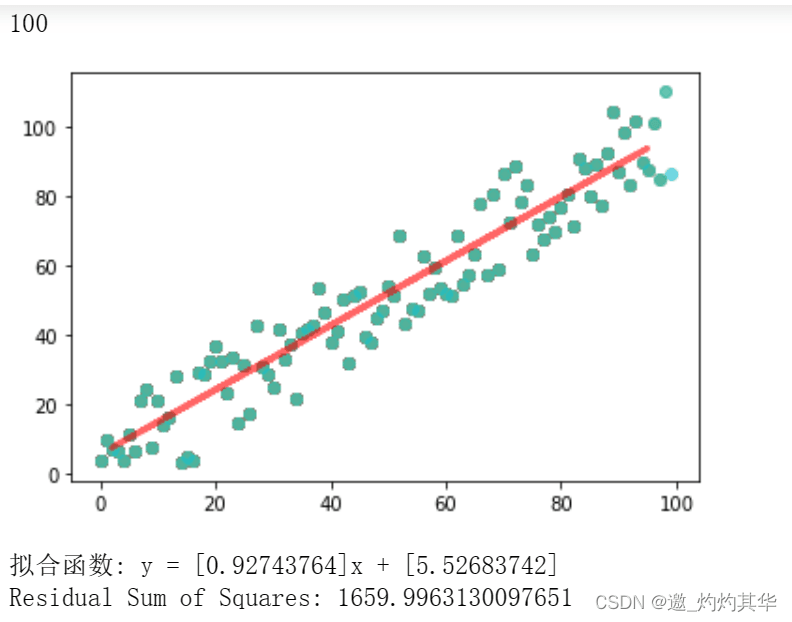
plt.scatter(X, y, alpha=0.6)
return X,y
3、计算残差平方
def residual_sum_of_squares(y_true, y_pred):
# 计算残差
residuals = y_true - y_pred
# 计算残差平方
squared_residuals = residuals ** 2
# 计算残差平方和
rss = np.sum(squared_residuals)
return rss
4、训练模型
if __name__ == '__main__':
np.random.seed(0)
X,y = generateData()
print(len(X))
X_train,X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=0)
regressor = LinearRegression()
regressor.fit(X_train, y_train)
y_result = regressor.predict(X_test)
plt.plot(X_test, y_result, color='red',alpha=0.6, linewidth=3,
label='Predicted Line')
plt.show()
# 提取模型的斜率和截距
slope = regressor.coef_[0]
intercept = regressor.intercept_
# 输出拟合函数
print(f"拟合函数: y = {slope}x + {intercept}")
# 计算残差平方和
rss = residual_sum_of_squares(y_test, y_result)
print("Residual Sum of Squares:", rss)
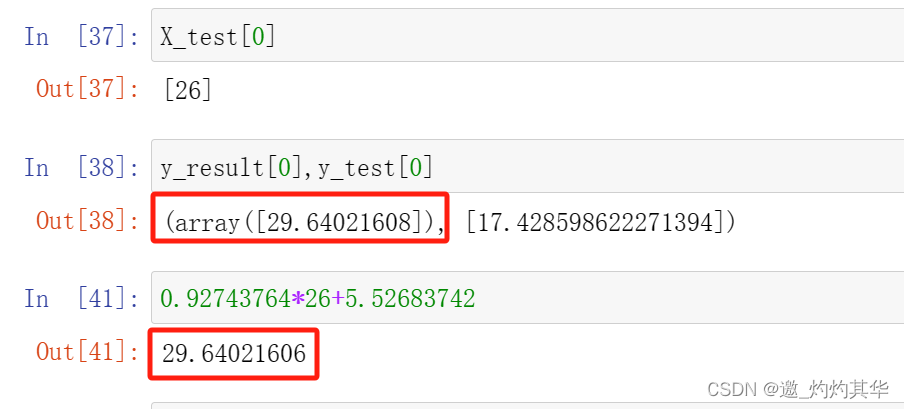
5、数据验证
6、模型优缺点
优点
运算速度快。由于算法很简单,而且符合非常简洁的数学原理,不管是建模速度,还是预测速度都
是非常快的。
可解释性强。由于最终我们可以得到一个函数公式,根据计算出的公式系数就可以很明确地知道每
个变量的影响大小。
对线性关系拟合效果好。当然,相比之下,如果数据是非线性关系,那么就不合适了。
缺点
预测的精确度较低。由于获得的模型只是要求最小的损失,而不是对数据良好的拟合,所以精确度略低。
不相关的特征会影响结果。对噪声数据也比较难处理,所以在数据处理阶段需要剔除不相关的特征以及噪声数据。
容易出现过拟合。尤其在数据量较少的情况下,可能出现这种问题。
到此这篇关于python实现线性回归的示例代码的文章就介绍到这了,更多相关python 线性回归内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 用ASP生成UTF-8网页文件的两种方法...2007-07-07
用ASP生成UTF-8网页文件的两种方法...2007-07-07 asp下制做行背景颜色交替变换的表格...2007-04-04
asp下制做行背景颜色交替变换的表格...2007-04-04 禁止站外提交表单...2006-08-08
禁止站外提交表单...2006-08-08 利用 cache 做对比静态页的网页技术...2007-10-10
利用 cache 做对比静态页的网页技术...2007-10-10
P3P 和 跨域 (cross-domain) cookie 访问(读取和设置)
在IE 里面跨域去设置 cookie跨域的实现,尝试了n中方法都不行,查了一下资料,可以通过设置header中的p3p值来实现,真不错:)2009-06-06 比较不错的asp模板引终极讲解(WEB开发之ASP模式)...2007-08-08
比较不错的asp模板引终极讲解(WEB开发之ASP模式)...2007-08-08 正则匹配(正则表达式)模式进行数据匹配替换2010-03-03
正则匹配(正则表达式)模式进行数据匹配替换2010-03-03
ASP.Net MVC利用NPOI导入导出Excel的示例代码
这篇文章主要介绍了ASP.Net MVC利用NPOI导入导出Excel的问题记录,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-05-05 asp下实现记录集内随机取记录的代码...2007-11-11
asp下实现记录集内随机取记录的代码...2007-11-11
ASP中实现的URLEncode、URLDecode自定义函数
这篇文章主要介绍了ASP中实现的URLEncode、URLDecode自定义函数,和ASP自带的server.urlencode是不一样的哦,需要的朋友可以参考下2014-07-07










最新评论