
pytorch 优化器(optim)不同参数组,不同学习率设置的操作
optim 的基本使用
for do:
1. 计算loss
2. 清空梯度
3. 反传梯度
4. 更新参数
optim的完整流程
cifiron = nn.MSELoss()
optimiter = torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9)
for i in range(iters):
out = net(inputs)
loss = cifiron(out,label)
optimiter.zero_grad() # 清空之前保留的梯度信息
loss.backward() # 将mini_batch 的loss 信息反传回去
optimiter.step() # 根据 optim参数 和 梯度 更新参数 w.data -= w.grad*lr
网络参数 默认使用统一的 优化器参数
如下设置 网络全局参数 使用统一的优化器参数
optimiter = torch.optim.Adam(net.parameters(),lr=0.01,momentum=0.9)
如下设置将optimizer的可更新参数分为不同的三组,每组使用不同的策略
optimizer = torch.optim.SGD([
{'params': other_params},
{'params': first_params, 'lr': 0.01*args.learning_rate},
{'params': second_params, 'weight_decay': args.weight_decay}],
lr=args.learning_rate,
momentum=args.momentum,
)
我们追溯一下构造Optim的过程
为了更好的看整个过程,去掉了很多 条件判断 语句,如 >0 <0
# 首先是 子类Adam 的构造函数
class Adam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,
weight_decay=0, amsgrad=False):
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay, amsgrad=amsgrad)
'''
构造了 参数params,可以有两种传入格式,分别对应
1. 全局参数 net.parameters()
2. 不同参数组 [{'params': other_params},
{'params': first_params, 'lr': 0.1*lr}]
和 <全局> 的默认参数字典defaults
'''
# 然后调用 父类Optimizer 的构造函数
super(Adam, self).__init__(params, defaults)
# 看一下 Optim类的构造函数 只有两个输入 params 和 defaults
class Optimizer(object):
def __init__(self, params, defaults):
torch._C._log_api_usage_once("python.optimizer")
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = [] # 自身构造的参数组,每个组使用一套参数
param_groups = list(params)
if len(param_groups) == 0:
raise ValueError("optimizer got an empty parameter list")
# 如果传入的net.parameters(),将其转换为 字典
if not isinstance(param_groups[0], dict):
param_groups = [{'params': param_groups}]
for param_group in param_groups:
#add_param_group 这个函数,主要是处理一下每个参数组其它属性参数(lr,eps)
self.add_param_group(param_group)
def add_param_group(self, param_group):
# 如果当前 参数组中 不存在默认参数的设置,则使用全局参数属性进行覆盖
'''
[{'params': other_params},
{'params': first_params, 'lr': 0.1*lr}]
如第一个参数组 只提供了参数列表,没有其它的参数属性,则使用全局属性覆盖,第二个参数组 则设置了自身的lr为全局 (0.1*lr)
'''
for name, default in self.defaults.items():
if default is required and name not in param_group:
raise ValueError("parameter group didn't specify a value of required optimization parameter " +
name)
else:
param_group.setdefault(name, default)
# 判断 是否有一个参数 出现在不同的参数组中,否则会报错
param_set = set()
for group in self.param_groups:
param_set.update(set(group['params']))
if not param_set.isdisjoint(set(param_group['params'])):
raise ValueError("some parameters appear in more than one parameter group")
# 然后 更新自身的参数组中
self.param_groups.append(param_group)
网络更新的过程(Step)
具体实现
1、我们拿SGD举例,首先看一下,optim.step 更新函数的具体操作
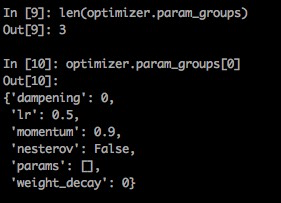
2、可见,for group in self.param_groups,optim中存在一个param_groups的东西,其实它就是我们传进去的param_list,比如我们上面传进去一个长度为3的param_list,那么 len(optimizer.param_groups)==3 , 而每一个 group 又是一个dict, 其中包含了 每组参数所需的必要参数 optimizer.param_groups:长度2的list,optimizer.param_groups[0]:长度6的字典
3、然后取回每组 所需更新的参数for p in group['params'] ,根据设置 计算其 正则化 及 动量累积,然后更新参数 w.data -= w.grad*lr
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
# 本组参数更新所必需的 参数设置
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']: # 本组所有需要更新的参数 params
if p.grad is None: # 如果没有梯度 则直接下一步
continue
d_p = p.grad.data
# 正则化 及 动量累积 操作
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
# 当前组 学习参数 更新 w.data -= w.grad*lr
p.data.add_(-group['lr'], d_p)
return loss
如何获取指定参数
1、可以使用model.named_parameters() 取回所有参数,然后设定自己的筛选规则,将参数分组
2、取回分组参数的id map(id, weight_params_list)
3、取回剩余分特殊处置参数的id other_params = list(filter(lambda p: id(p) not in params_id, all_params))
all_params = model.parameters()
weight_params = []
quant_params = []
# 根据自己的筛选规则 将所有网络参数进行分组
for pname, p in model.named_parameters():
if any([pname.endswith(k) for k in ['cw', 'dw', 'cx', 'dx', 'lamb']]):
quant_params += [p]
elif ('conv' or 'fc' in pname and 'weight' in pname):
weight_params += [p]
# 取回分组参数的id
params_id = list(map(id, weight_params)) + list(map(id, quant_params))
# 取回剩余分特殊处置参数的id
other_params = list(filter(lambda p: id(p) not in params_id, all_params))
# 构建不同学习参数的优化器
optimizer = torch.optim.SGD([
{'params': other_params},
{'params': quant_params, 'lr': 0.1*args.learning_rate},
{'params': weight_params, 'weight_decay': args.weight_decay}],
lr=args.learning_rate,
momentum=args.momentum,
)
获取指定层的参数id
# # 以层为单位,为不同层指定不同的学习率
# ## 提取指定层对象
special_layers = t.nn.ModuleList([net.classifiter[0], net.classifiter[3]])
# ## 获取指定层参数id
special_layers_params = list(map(id, special_layers.parameters()))
print(special_layers_params)
# ## 获取非指定层的参数id
base_params = filter(lambda p: id(p) not in special_layers_params, net.parameters())
optimizer = t.optim.SGD([{'params': base_params},
{'params': special_layers.parameters(), 'lr': 0.01}], lr=0.001)
补充:【pytorch】筛选冻结部分网络层参数同时设置有参数组的时候该怎么办?
在进行神经网络训练的时候,常常需要冻结部分网络层的参数,不想让他们回传梯度。这个其实很简单,其他博客里教程很多~
那如果,我想对不同的参数设置不同的学习率呢?这个其他博客也有,设置参数组就好啦,优化器就可以分别设置学习率了。
那么,如果我同时想冻结参数和设置不同的学习率呢?是不是把两个人给合起来就好了?好的那你试试吧看看行不行。
我最近工作中需要对two-stream的其中的一只进行冻结,并且设置不同的学习率。下面记录一下我踩的坑。
首先,我们需要筛选所需要的层。我想要把名字里含有特定符号的层给筛选出来。在这里我要强烈推荐这个利用正则表达式来进行字符串筛选的方式!
import re str = 'assdffggggg' word = 'a' a = [m.start() for m in re.finditer(word, str)]
这里的a是一个列表,它里面包含的是word在字符串str中所在的位置,这里自然就是0了。
在进行网络层参数冻结的时候,网上会有两种for循环:
for name, p in net.named_parameters(): for p in net.parameters():
这两种都行,但是对于需要对特定名称的网络层进行冻结的时候就需要选第一个啦,因为我们需要用到参数的"name"属性。
下面就是简单的筛选和冻结,和其他教程里面的一样:
word1 = 'seg'
for name, p in decode_net.named_parameters():
str = name
a = [m.start() for m in re.finditer(word1, str)]
if a: #列表a不为空的话就设置回传的标识为False
p.requires_grad = False
else:
p.requires_grad = True
#if p.requires_grad:#这个判断可以打印出需要回传梯度的层的名称
#print(name)
到这里我们就完成了网络参数的冻结。我真正想要分享的在下面这个部分!!看了四天的大坑!
冻结部分层的参数之后,我们在使用优化器的时候就需要先把不需要回传梯度的参数给过滤掉,如果不过滤就会报错,优化器就会抱怨你怎么把不需要优化的参数给放进去了balabala的。所以我们加一个:
optimizer = optim.SGD(
filter(lambda p: p.requires_grad, net.parameters()), # 记住一定要加上filter(),不然会报错
lr=0.01, weight_decay=1e-5, momentum=0.9)
到这里也没有任何的问题。但是!我做分割的encode部分是pre-trained的resnet,这部分我的学习率不想和我decode的部分一样啊!不然我用pre-trained的有啥用??so,我划分了一个参数组:
base_params_id = list(map(id, net.conv1.parameters())) + list(map(id,net.bn1.parameters()))+\ list(map(id,net.layer1.parameters())) + list(map(id,net.layer2.parameters())) \ + list(map(id,net.layer3.parameters())) + list(map(id,net.layer4.parameters())) new_params = filter(lambda p: id(p) not in base_params_id , net.parameters()) base_params = filter(lambda p: id(p) in base_params_id, net.parameters())
好了,那么这个时候,如果我先不考虑过滤的话,优化器的设置应该是这样的:
optimizerG = optim.SGD([{'params': base_params, 'lr': 1e-4},
{'params': new_params}], lr = opt.lr, momentum = 0.9, weight_decay=0.0005)
那么,按照百度出来的教程,我下一步要加上过滤器的话是不是应该:
optimizerG = optim.SGD( filter(lambda p: p.requires_grad, net.parameters()),
[{'params': base_params, 'lr': 1e-4},
{'params': new_params}], lr = opt.lr, momentum = 0.9, weight_decay=0.0005)
好的看起来没有任何的问题,但是运行的时候就开始报错:

就是这里!!一个刚开始用pytorch的我!什么都不懂!然后我看了四天!!最后查阅了官方文档才知道为什么报错。以后看到这种提示init函数错误的都要记得去官方doc上看说明。

这里其实写的很清楚了,SGD优化器每个位置都是什么参数。到这里应该已经能看出来哪里有问题了吧?
optimizerG = optim.SGD( filter(lambda p: p.requires_grad, net.parameters()),
[{'params': base_params, 'lr': 1e-4},
{'params': new_params}], lr = opt.lr, momentum = 0.9, weight_decay=0.0005)
看我的SGD函数每个参数的位置,第一个放的是过滤器,第二个是参数组,然后是lr,对比官方的定义:第一个参数,第二个是lr等等。
所以错误就在这里!我第一个位置放了过滤器!第二个位置是参数组!所以他把过滤器当作参数,参数组当作学习率,然后就报错说lr接受到很多个值……
仔细去看其他博客的教程,基本是只有分参数组的优化器设置和冻结层了之后优化器的设置。没有又分参数组又冻结部分层参数的设置。所以设置过滤器把不需要优化的参数给踢掉这个步骤还是要的,但是在现在这种情况下不应该放在SGD里!
new_params = filter(lambda p: id(p) not in base_params_id and p.requires_grad,\
netG.parameters())
base_params = filter(lambda p: id(p) in base_params_id,
netG.parameters())
应该在划分参数组的时候就添加过滤器,将不需要回传梯度的参数过滤掉(这里就是直接筛选p.requires_grad即可)。如此便可以顺利冻结参数并且设置参数组啦!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
相关文章
 这篇文章主要为大家详细介绍了Python实现代码统计工具,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-09-09
这篇文章主要为大家详细介绍了Python实现代码统计工具,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-09-09 这篇文章主要介绍了python wordcloud库实例,词云通过以词语为基本单位,更加直观和艺术地展示文本。wordcloud是优秀的词云展示的python第三方库2022-12-12
这篇文章主要介绍了python wordcloud库实例,词云通过以词语为基本单位,更加直观和艺术地展示文本。wordcloud是优秀的词云展示的python第三方库2022-12-12
Linux(Redhat)安装python3.6虚拟环境(推荐)
这篇文章主要介绍了Linux(Redhat)安装python3.6虚拟环境,非常不错,具有参考借鉴价值 ,需要的朋友可以参考下2018-05-05
python版本坑:md5例子(python2与python3中md5区别)
这篇文章主要介绍了python版本坑:md5例子(python2与python3中md5区别),需要的朋友可以参考下2017-06-06 本文主要介绍了jupyter-lab设置自启动及远程连接开发环境,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02
本文主要介绍了jupyter-lab设置自启动及远程连接开发环境,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02 这篇文章主要介绍了Linux CentOS Python开发环境搭建方法,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2018-11-11
这篇文章主要介绍了Linux CentOS Python开发环境搭建方法,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下2018-11-11 这篇文章主要介绍了用Python快速实现视频的人脸融合功能,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了用Python快速实现视频的人脸融合功能,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-06-06 在本篇文章里小编给大家整理的是关于Python API自动化框架总结内容,需要的朋友们学习下。2019-11-11
在本篇文章里小编给大家整理的是关于Python API自动化框架总结内容,需要的朋友们学习下。2019-11-11 这篇文章主要为大家详细介绍了SVM基本概念及Python实现代码,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-12-12
这篇文章主要为大家详细介绍了SVM基本概念及Python实现代码,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-12-12 这篇文章主要介绍了python读取并定位excel数据坐标系详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-06-06
这篇文章主要介绍了python读取并定位excel数据坐标系详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-06-06










最新评论