
python提取word文件中的所有图片
前言
办公中,偶尔会碰到一种情况,需要提取word文档中的图片,决定写这样一款工具自动提取图片。
关于脚本的使用:
情景1:如果你拿到的是一个文件夹,所有的word文件都在这个文件夹的子目录下,深度为1层,你可以直接使用该脚本
情景2:如果你拿到的是一个文件夹,打开之后,里面杂乱无章的充斥着各种文件,你也不确定word文档都在哪,那么你需要使用Everything来手动提取出所有的word文档,虽然我也可以让脚本实现这个功能,但是使用脚本需要考虑到有可能存在同名文件,再处理起来代码量会更大,还是用Everything手动移动文件吧,谁让现在的代码量已经远超我预期了呢?
3:预处理前面的两步之后,就可以直接运行脚本了
4:脚本注释很详细,这里不再赘述
5:目前仅支持docx格式的,主要原因是,如果支持doc的话,需要把doc转为docx,转换略慢,并且,我也用不到。如果你感兴趣的话,我再最下面介绍了互转的方法,你可以把这个函数加进去即可
代码
import zipfile
import os
import shutil
import hashlib
import send2trash
'''
假设所有的word文档存放在某路径中,这个路径中包含各种杂七杂八的玩意
使用Everything,或者"筛选文件.py"把所有的docx文件移动到C:\\Users\\asuka\\Desktop\\123
逐个解压每个docx文档,并提取图片
强烈建议使用Everything用来筛选出所有的word文档,这样假如有两个重名的文档,可以手动处理
如果编写软件来实现的话,会麻烦很多
'''
# 一个用来解压文件的函数
def extract_zip(zip_path):
os.chdir(os.path.dirname(zip_path)) # 需要进入到这个路径下,这样解压的文件,才在这个路径下
a = zipfile.ZipFile(zip_path) # 调用zipfile.ZipFile()函数,创建一个ZipFile对象
a.extractall()
a.close()
os.chdir(path) # 恢复到之前的路径
# 用来获取所有的图片
'''
测试的时候发现,不同word文件解压之后,里面的图片命名格式一致,
导致不能直接移动图片,否则会造成文件覆盖,这里需要对找到的每一个文件,进行重命名
'''
def get_picture(demo_path):
count = 1 # 用来个图片进行重命名
for current_folder, list_folders, files in os.walk(demo_path):
for f in files:
if f.endswith('png') or f.endswith('jpg') or f.endswith('jpeg'): # 设置图片类型是这种
move_f = current_folder + '\\' + f # 给出要移动的文件的路径
new_file_path = path1 + '\\' + str(count) + '.' + f.rpartition('.')[-1] # 指定新文件的文件路径,文件名数字递增,文件后缀
shutil.move(move_f, new_file_path) # 移动文件
count += 1
print('[-] 总共获取图片{}张'.format(count - 1))
# 对图片去重
# 计算每个图片的md5值,据此进行去重,去重的文件会被删除到回收站中
def only_one(test_path):
md5_list = []
count = 0
for current_folder, list_folders, files in os.walk(test_path):
for file in files:
picture_path = current_folder + '\\' + file # 获取每个图片的路径
f = open(picture_path, 'rb') # 开始计算每个图片的md5值
md5obj = hashlib.md5()
md5obj.update(f.read())
get_hash = md5obj.hexdigest()
f.close()
md5_value = str(get_hash).upper()
# 开始去重
if md5_value in md5_list:
send2trash.send2trash(picture_path) # 如果这个文件的md5值曾经出现过,就删除这张图片
count += 1
print('[-] 删除重复图片:' + str(file))
else:
md5_list.append(md5_value) # 如果这个图片的md5值不存在列表中,就添加进列表中
print('[-] 共删除重复图片:{}张'.format(count))
print('[+] 只有后缀是docx的word文档才可以提取图片!!!')
path = input('[+] 请输入word文档所在文件夹:') # 获取原始的word文档所在路径
os.chdir(path)
print("[+] 请输入一个路径,用来存放所有的图片")
print("[+] 或者按回车键,我将自动把图片整理之后存放在你的桌面")
path1 = input('') # path1 用来存放所有的图片文件
if len(path1):
pass
else:
desktop_path = os.path.join(os.path.expanduser("~"), 'Desktop') # 获取桌面路径
path1 = os.path.join(desktop_path, '所有word文件中的图片')
os.makedirs(path1)
files = os.listdir(path) # 获取指定文件夹下的所有文件
for file in files: # 遍历指定文件夹下的所有文件
if file.endswith('docx'): # 加一个判断,这样即使path路径下有别的类型文件也无妨
filename = file.rpartition('.')[0] # 获取文件的文件名
file_path = os.path.join(path, filename)
os.makedirs(file_path) # 为获取到的文件名创建一个文件夹
shutil.move(file, file_path) # 把word文档移动到同名文件夹中
word_path = os.path.join(file_path, file) # 获取此时word文件的文件路径
extract_zip(word_path) # 不用改后缀,直接解压docx文件
get_picture(path)
only_one(path1)
print('[-] 现有图片:{}张'.format(len(os.listdir(path1))))
GIF示例

Everything提取文件的演示(手动处理同名word文件,我这里对同名文件进行替换):

附:doc转docx
介绍一下实现二者互转
需要说明的是:
要安装OFFICE,如果是使用金山WPS的,则还不能应用
转换速度略慢,但还能接受
如果想转换为其他格式文件,需要在format文件名内修改,并用如下save as 参数
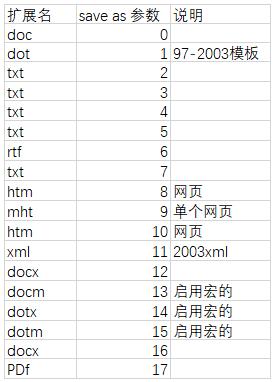
代码
关于第9行、第19行代码:
第9行doc.SaveAs("{}x".format(fn), 12):
"{}x".format(fn)相当于把C:\Users\asuka\Desktop\11\123.doc变成了C:\Users\asuka\Desktop\11\123.docx,首先是指定了路径和文件名,然后12表示存储成docx格式的,保证了后缀名和格式是对应的。
第19行doc.SaveAs("{}".format(fn[:-1]), 0):
"{}".format(fn[:-1])相当于把C:\Users\asuka\Desktop\11\456.docx变成了C:\Users\asuka\Desktop\11\456.doc,指定了要另外保存的文件,保存的路径和文件名,然后0表示存储成doc格式的,保证了后缀名和格式是对应的。
from win32com import client
# 转换doc为docx
def doc2docx(fn):
word = client.Dispatch("Word.Application") # 打开word应用程序
# for file in files:
doc = word.Documents.Open(fn) # 打开word文件
doc.SaveAs("{}x".format(fn), 12) # 另存为后缀为".docx"的文件,其中参数12或16指docx文件
doc.Close() # 关闭原来word文件
word.Quit()
# 转换docx为doc
def docx2doc(fn):
word = client.Dispatch("Word.Application") # 打开word应用程序
# for file in files:
doc = word.Documents.Open(fn) # 打开word文件
doc.SaveAs("{}".format(fn[:-1]), 0) # 另存为后缀为".docx"的文件,其中参数0指doc
print(fn[:-1])
doc.Close() # 关闭原来word文件
word.Quit()
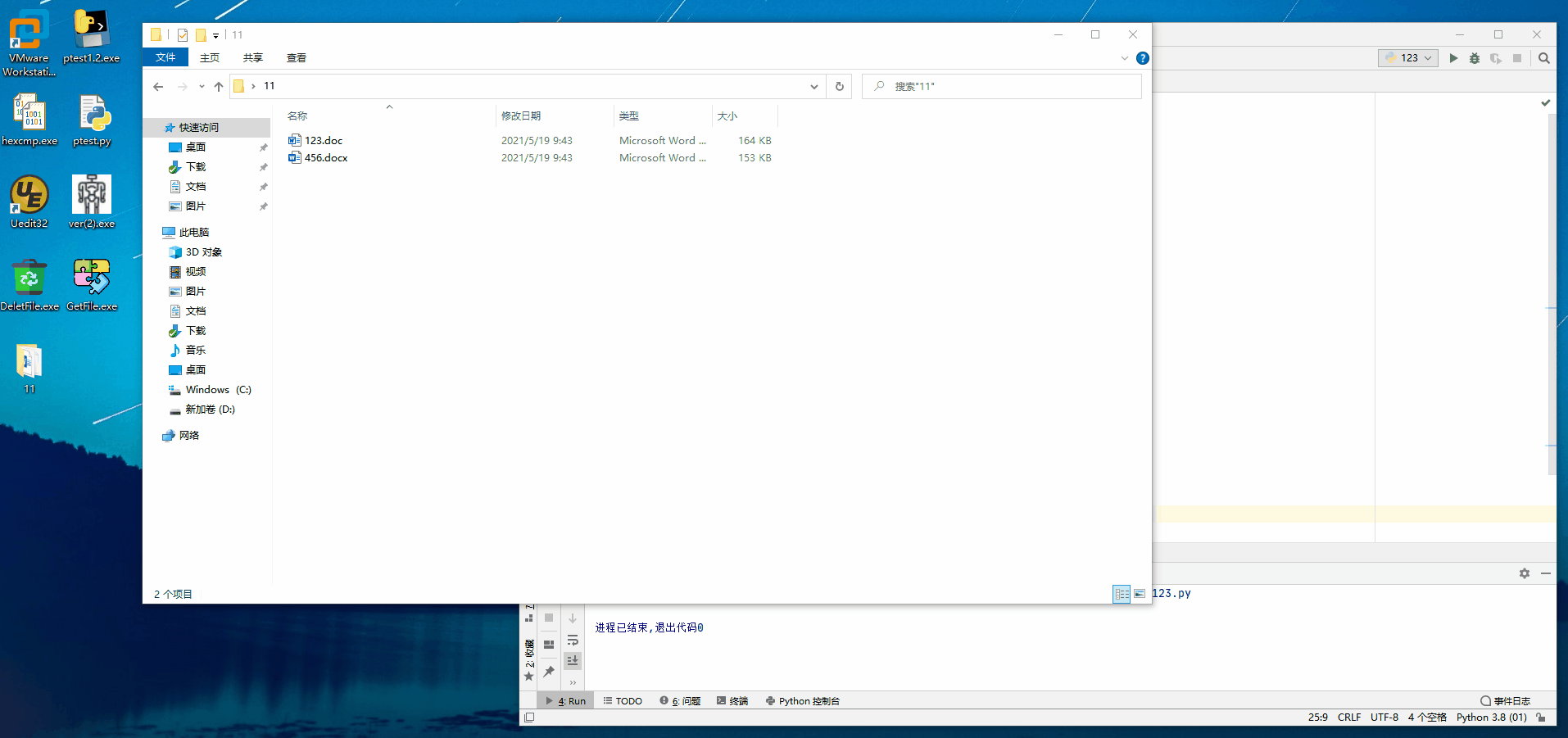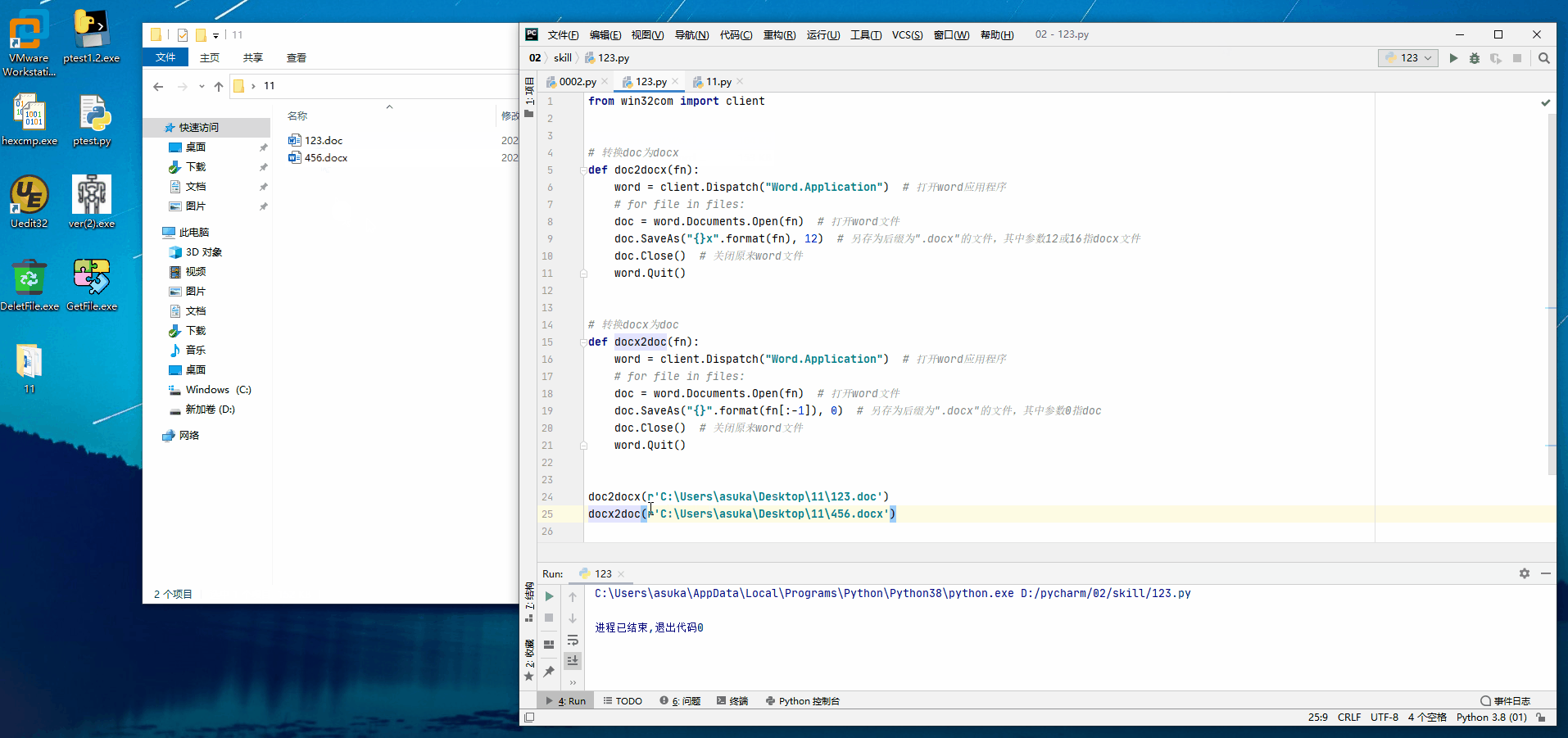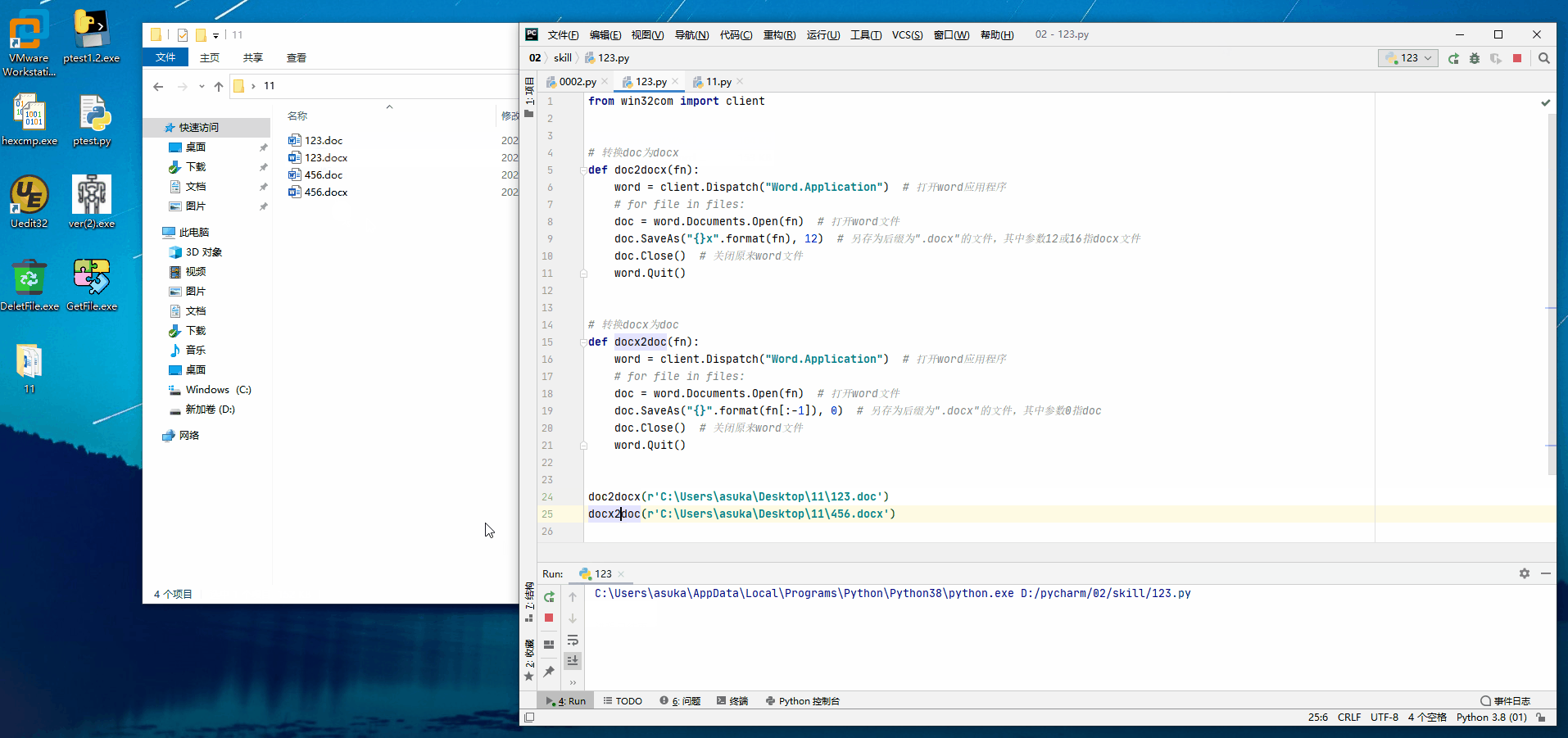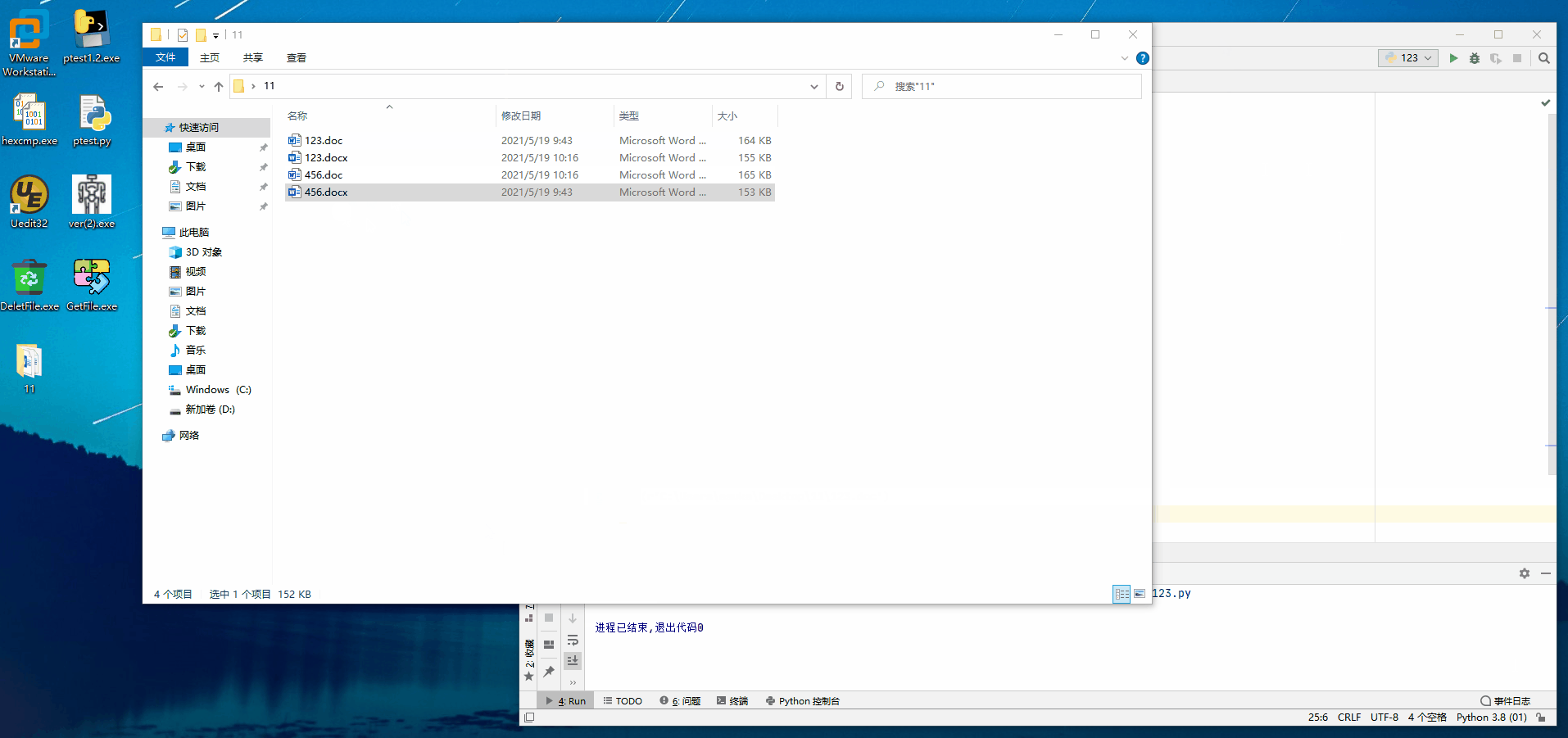
doc2docx(r'C:\Users\asuka\Desktop\11\123.doc')
docx2doc(r'C:\Users\asuka\Desktop\11\456.docx')
到此这篇关于python提取word文件中的所有图片的文章就介绍到这了,更多相关python提取word图片内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Python通过调用有道翻译api实现翻译功能,结合实例形式分析了基于Python实现的有道翻译api调用相关操作技巧,需要的朋友可以参考下2018-07-07
这篇文章主要介绍了Python通过调用有道翻译api实现翻译功能,结合实例形式分析了基于Python实现的有道翻译api调用相关操作技巧,需要的朋友可以参考下2018-07-07 numpy里有一个非常神奇的函数叫做np.where()函数,下面这篇文章主要给大家介绍了关于Python np.where()的详解以及代码应用的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-08-08
numpy里有一个非常神奇的函数叫做np.where()函数,下面这篇文章主要给大家介绍了关于Python np.where()的详解以及代码应用的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-08-08
解决keras.datasets 在loaddata时,无法下载的问题
这篇文章主要介绍了解决keras.datasets 在loaddata时,无法下载的问题,具有很好的参考价值,希望对大家有所帮助。2021-05-05 这篇文章主要介绍了Python pandas对excel的操作实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-07-07
这篇文章主要介绍了Python pandas对excel的操作实现示例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-07-07 学Python那么久了,才知道自己不会把脚本编译成可执行exe文件,下面这篇文章主要给大家介绍了关于将.py文件转化为.exe文件的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-09-09
学Python那么久了,才知道自己不会把脚本编译成可执行exe文件,下面这篇文章主要给大家介绍了关于将.py文件转化为.exe文件的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下2022-09-09 这篇文章主要介绍了利用Python实现外观数列求解,文章利用举例说明文章的主题内容,具有一定的参考价值,需要的小伙伴乐意参考一下2022-03-03
这篇文章主要介绍了利用Python实现外观数列求解,文章利用举例说明文章的主题内容,具有一定的参考价值,需要的小伙伴乐意参考一下2022-03-03 这篇文章主要介绍了使用pandas读取表格数据并进行单行数据拼接的详细教程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03
这篇文章主要介绍了使用pandas读取表格数据并进行单行数据拼接的详细教程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-03-03 这篇文章主要为大家详细介绍了Python+OpenCV图片局部区域像素值处理,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-01-01
这篇文章主要为大家详细介绍了Python+OpenCV图片局部区域像素值处理,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2019-01-01 这篇文章主要介绍了8段用于数据清洗Python代码(小结),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-10-10
这篇文章主要介绍了8段用于数据清洗Python代码(小结),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-10-10 这篇文章主要介绍了Numpy中对向量、矩阵的使用详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-10-10
这篇文章主要介绍了Numpy中对向量、矩阵的使用详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-10-10










最新评论