
pandas中DataFrame检测重复值的实现
更新时间:2021年05月26日 10:20:10 作者:乘风破浪的熊爸
本文主要介绍了pandas DataFrame检测重复值,主要包括了检查整行整列的检测,以及多列是否重复,需要的朋友们下面随着小编来一起学习学习吧
本文详解如何使用pandas查看dataframe的重复数据,判断是否重复,以及如何去重
DataFrame.duplicated(subset=None, keep='first')
subset:如果你认为几个字段重复,则数据重复,就把那几个字段以列表形式放到subset后面。默认是所有字段重复为重复数据。
keep:
- 默认为'first' ,也就是如果有重复数据,则第一条出现的定义为False,后面的重复数据为True。
- 如果为'last',也就是如果有重复数据,则最后一条出现的定义为False,后面的重复数据为True。
- 如果为False,则所有重复的为True
下面举例
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
df

# 默认为keep="first",第一条重复的为False,后面重复的为True # 一般不会设置keep,保持keep为默认值。 df.duplicated() 结果 0 False 1 True 2 False 3 False 4 False dtype: bool # keep="last",,最后一条重复的为False,后面重复的为True df.duplicated(keep="last") 结果 0 True 1 False 2 False 3 False 4 False dtype: bool # keep=False,,所有重复的为True df.duplicated(keep=False) 结果 0 True 1 True 2 False 3 False 4 False dtype: bool # sub是子,subset是子集 # 标记只要brand重复为重复值。 df.duplicated(subset='brand') 结果 0 False 1 True 2 False 3 True 4 True dtype: bool # 只要brand重复brand和style重复的为重复值。 df.duplicated(subset=['brand','style']) 结果 0 False 1 True 2 False 3 False 4 True dtype: bool # 显示重复记录,通过布尔索引 df[df.duplicated()]
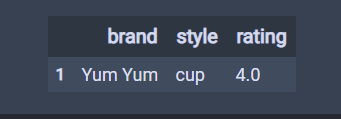
# 查询重复值的个数。 df.duplicated().sum() 结果 1
到此这篇关于pandas中DataFrame检测重复值的实现的文章就介绍到这了,更多相关pandas DataFrame检测重复值内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要为大家详细介绍了pygame游戏之旅,教大家如何创建游戏窗口界面,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-11-11
这篇文章主要为大家详细介绍了pygame游戏之旅,教大家如何创建游戏窗口界面,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-11-11
Python 实现Numpy中找出array中最大值所对应的行和列
今天小编就为大家分享一篇Python 实现Numpy中找出array中最大值所对应的行和列,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-11-11
python GUI库图形界面开发之PyQt5不规则窗口实现与显示GIF动画的详细方法与实例
这篇文章主要介绍了python GUI库图形界面开发之PyQt5不规则窗口与显示GIF动画的详细方法与实例,需要的朋友可以参考下2020-03-03 这篇文章主要介绍了教你如何用pycharm安装pyqt5及其相关配置,首先通过单独创建一个文件夹来专门存放pyqt5的代码并建立虚拟环境展开文章叙述,需要的小伙伴可以参考一下2022-04-04
这篇文章主要介绍了教你如何用pycharm安装pyqt5及其相关配置,首先通过单独创建一个文件夹来专门存放pyqt5的代码并建立虚拟环境展开文章叙述,需要的小伙伴可以参考一下2022-04-04 这篇文章主要介绍了Pycharm如何对python文件进行打包,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02
这篇文章主要介绍了Pycharm如何对python文件进行打包,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02 这篇文章主要为大家详细介绍了python使用matplotlib画饼状图,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-09-09
这篇文章主要为大家详细介绍了python使用matplotlib画饼状图,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-09-09 这篇文章主要为大家介绍了Python机器学习性能度量利用鸢尾花数据绘制P-R曲线示例学习,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-02-02
这篇文章主要为大家介绍了Python机器学习性能度量利用鸢尾花数据绘制P-R曲线示例学习,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-02-02 这篇文章主要为大家介绍了使用python和shell监控linux服务器的详细代码,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06
这篇文章主要为大家介绍了使用python和shell监控linux服务器的详细代码,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06 使用VSCode远程切换Python虚拟环境涉及安装VSCode和必要扩展、连接远程服务器、创建或激活虚拟环境,并选择对应Python解释器,详细步骤包括安装Python和Remote-SSH扩展,感兴趣的朋友一起看看吧2024-09-09
使用VSCode远程切换Python虚拟环境涉及安装VSCode和必要扩展、连接远程服务器、创建或激活虚拟环境,并选择对应Python解释器,详细步骤包括安装Python和Remote-SSH扩展,感兴趣的朋友一起看看吧2024-09-09 这篇文章主要给大家分享的是Python单元测试常见的几个技巧,文章会讲解requests的一些细节实现以及pytest的使用等,感兴趣的小伙伴不妨和小编一起阅读下面文章 的具体内容吧2021-09-09
这篇文章主要给大家分享的是Python单元测试常见的几个技巧,文章会讲解requests的一些细节实现以及pytest的使用等,感兴趣的小伙伴不妨和小编一起阅读下面文章 的具体内容吧2021-09-09










最新评论