
端午节将至,用Python爬取粽子数据并可视化,看看网友喜欢哪种粽子吧!
一、前言
本文就从数据爬取、数据清洗、数据可视化,这三个方面入手,但你简单完成一个小型的数据分析项目,让你对知识能够有一个综合的运用。
整个思路如下:
- 爬取网页:https://www.jd.com/
- 爬取说明: 基于京东网站,我们搜索网站“粽子”数据,大概有100页。我们爬取的字段,既有一级页面的相关信息,还有二级页面的部分信息;
- 爬取思路: 先针对某一页数据的一级页面做一个解析,然后再进行二级页面做一个解析,最后再进行翻页操作;
- 爬取字段: 分别是粽子的名称(标题)、价格、品牌(店铺)、类别(口味);
- 使用工具: requests+lxml+pandas+time+re+pyecharts
- 网站解析方式: xpath
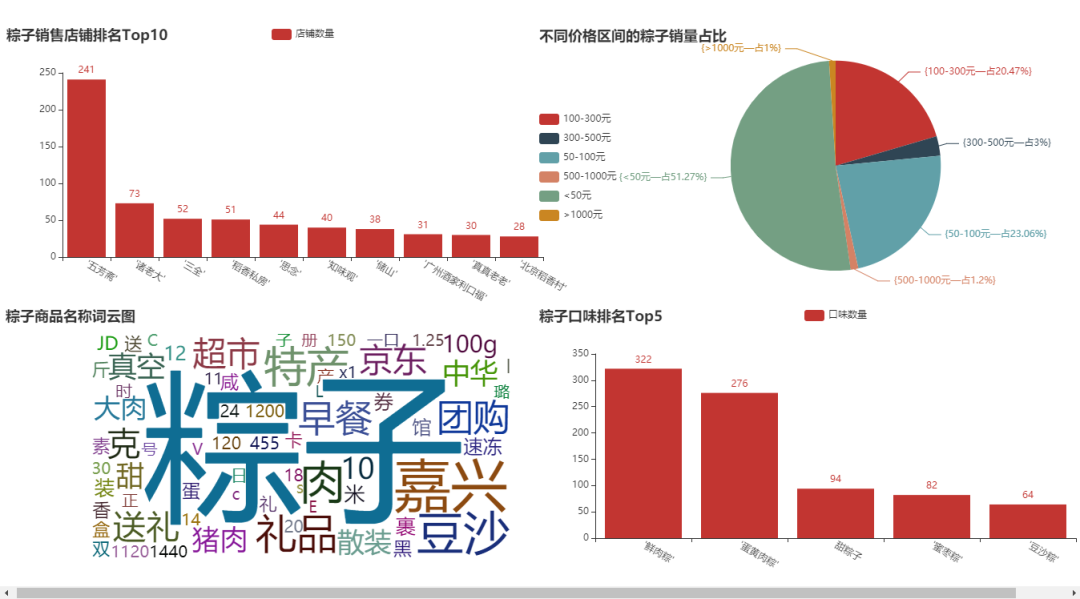
最终的效果如下:
二、数据爬取
京东网站,一般是动态加载的,也就是说,采用一般方式只能爬取到某个页面的前30个数据(一个页面一共60个数据)。
基于本文,我仅用最基本的方法,爬取了每个页面的前30条数据(如果大家有兴趣,可以自行下去爬取所有的数据)。
那么,本文究竟爬取了哪些字段呢?我给大家做一个展示,大家有兴趣,可以爬取更多的字段,做更为详细的分析。
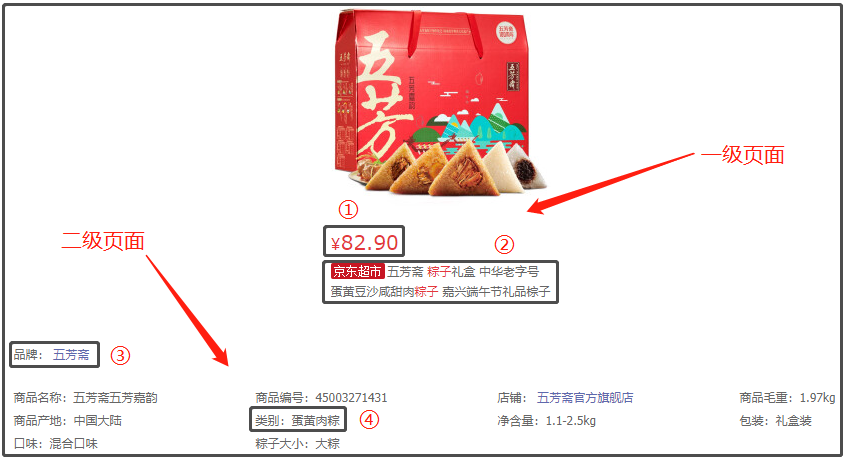
下面为大家展示爬虫代码:
import pandas as pd
import requests
from lxml import etree
import chardet
import time
import re
def get_CI(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; X64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
rqg = requests.get(url,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 价格
p_price = html.xpath('//div/div[@class="p-price"]/strong/i/text()')
# 名称
p_name = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/em')
p_name = [str(p_name[i].xpath('string(.)')) for i in range(len(p_name))]
# 深层url
deep_ur1 = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/@href')
deep_url = ["http:" + i for i in deep_ur1]
# 从这里开始,我们获取“二级页面”的信息
brands_list = []
kinds_list = []
for i in deep_url:
rqg = requests.get(i,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 品牌
brands = html.xpath('//div/div[@class="ETab"]//ul[@id="parameter-brand"]/li/@title')
brands_list.append(brands)
# 类别
kinds = re.findall('>类别:(.*?)</li>',rqg.text)
kinds_list.append(kinds)
data = pd.DataFrame({'名称':p_name,'价格':p_price,'品牌':brands_list,'类别':kinds_list})
return(data)
x = "https://search.jd.com/Search?keyword=%E7%B2%BD%E5%AD%90&qrst=1&wq=%E7%B2%BD%E5%AD%90&stock=1&page="
url_list = [x + str(i) for i in range(1,200,2)]
res = pd.DataFrame(columns=['名称','价格','品牌','类别'])
# 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
最终爬取到的数据:
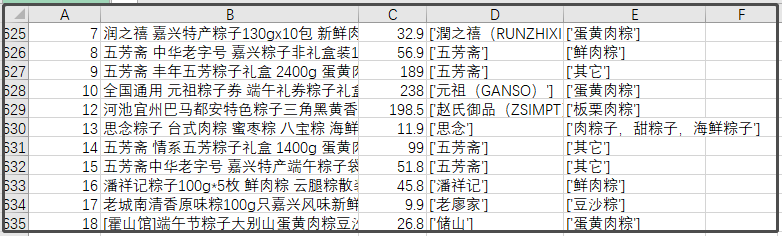
三、数据清洗
从上图可以看到,整个数据算是很整齐的,不是特别乱,我们只做一些简单的操作即可。
先使用pandas库,来读取数据。
import pandas as pd
df = pd.read_excel("粽子.xlsx",index_col=False)
df.head()
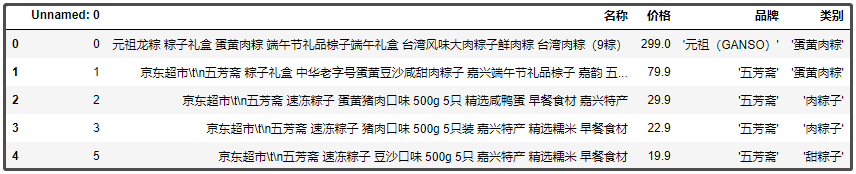
结果如下:

我们分别针对 “品牌”、“类别” 两个字段,去掉中括号。
df["品牌"] = df["品牌"].apply(lambda x: x[1:-1]) df["类别"] = df["类别"].apply(lambda x: x[1:-1]) df.head()
结果如下:
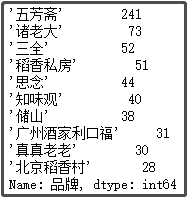
① 粽子品牌排名前10的店铺
df["品牌"].value_counts()[:10]
结果如下:
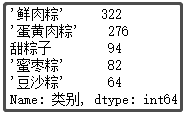
② 粽子口味排名前5的味道
def func1(x):
if x.find("甜") > 0:
return "甜粽子"
else:
return x
df["类别"] = df["类别"].apply(func1)
df["类别"].value_counts()[1:6]
结果如下:
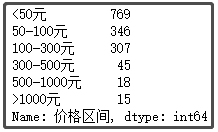
③ 粽子售卖价格区间划分
def price_range(x): # 按照我的购物习惯,划分价格 if x <= 50: return '<50元' elif x <= 100: return '50-100元' elif x <= 300: return '100-300元' elif x <= 500: return '300-500元' elif x <= 1000: return '500-1000元' else: return '>1000元' df["价格区间"] = df["价格"].apply(price_range) df["价格区间"].value_counts()
结果如下:
由于数据不是很多,没有很多字段,也就没有很多乱数据。因此,这里也没有做数据去重、缺失值填充等操作。所以,大家可以下去获取更多字段,更多数据,用于数据分析。
四、数据可视化
俗话说:字不如表,表不如图。通过可视化分析,我们可以将数据背后 “隐藏” 的信息,给展现出来。
拓展: 当然,这里只是 “抛砖引玉”,我并没有获取太多的数据,也没有获取太多的字段。这里给学习的朋友当一个作业题,自己下去用更多的数据、更多的字段,做更透彻的分析。
在这里,我们基于以下几个问题,做一个可视化展示,分别是:
- ① 粽子销售店铺Top10柱形图;
- ② 粽子口味排名Top5柱形图;
- ③ 粽子销售价格区间划分饼图;
- ④ 粽子商品名称词云图;
① 粽子销售店铺Top10柱形图
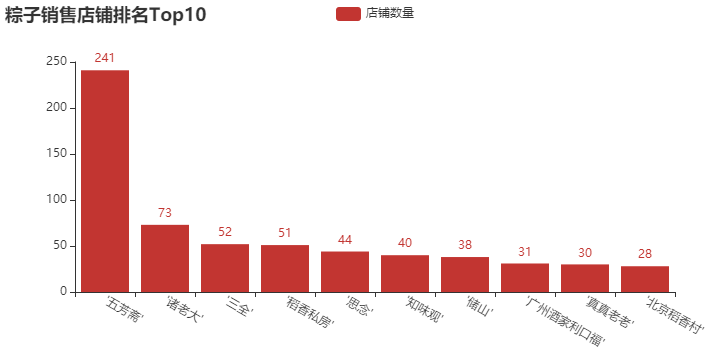
结论分析:去年,我们分析了一些月饼的数据,“五芳斋”、“北京稻香村” 这几个牌子记忆犹新,可谓是做月饼、粽子的老店。像 “三全” 和 “思念”,在我印象中一直以为它们只做水饺和汤圆,粽子是否值得一试呢?当然,这里还有一些新的牌子,像 “诸老大”、“稻香私房” 等一些牌子,大家都可以下去搜索一下。买东西,就是要精挑细选,品牌也重要。
② 粽子口味排名Top5柱形图
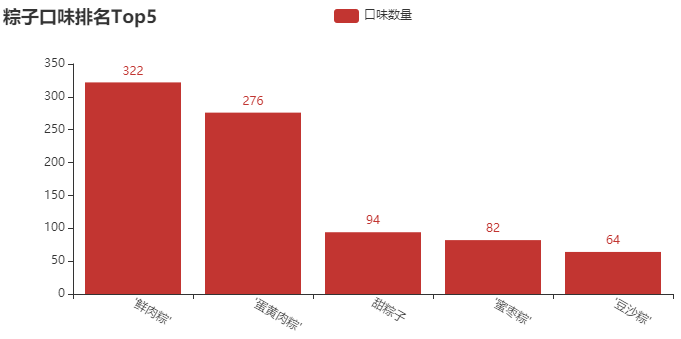
结论分析:在我印象中,小时候一直吃的最多的就是 “甜粽子”,直到我上了初中才知道,粽子还可以有肉?当然,从图中可以看出,卖 “鲜肉粽” 的店铺还是居多,毕竟这个送人,还是显得高端、大气一些。这里还有一些口味,像 “蜜枣粽”、“豆沙粽”,我基本没吃过。如果你送人,你会送什么口味的呢?
③ 粽子销售价格区间划分饼图
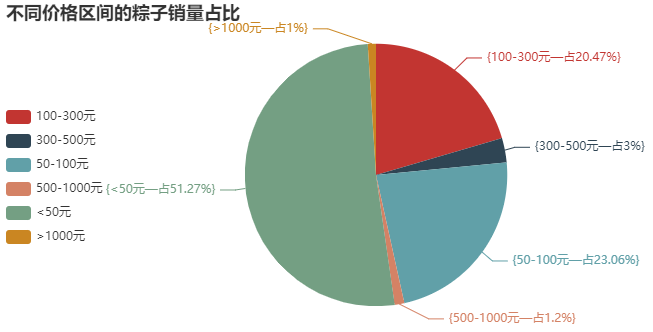
结论分析:这里,我故意把价格区间细分。这个饼图也很符合实际,毕竟每年就过一次端午节,还是以薄利多销为主,接近80%的粽子,售价都在100元以下。当然,还有一些中档的粽子,价格在100-300元。大于300元,我觉得也没有吃的必要,反正我是不会花这么多钱去买粽子。
④ 粽子商品名称词云图

结论分析:从图中,可以大致看出商家的卖点了。毕竟是节日,“送礼”、“礼品” 体现了节日氛围。“猪肉”、“豆沙” 体现了粽子口味。当然,它是否是 “早餐” 好选择呢?购买的话,还支持 “团购” 哦。这些字眼,多多少少都会各自吸引一部分人的眼球。
⑤ 图形组合为大屏
到此这篇关于端午节将至,用Python将粽子数据可视化,看看网友喜欢哪种吧!的文章就介绍到这了,更多相关Python数据可视化内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要为大家详细介绍了Python计算多幅图像栅格值的平均值,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-06-06
这篇文章主要为大家详细介绍了Python计算多幅图像栅格值的平均值,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-06-06 这篇文章主要介绍了python 实现弹球小游戏,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-11-11
这篇文章主要介绍了python 实现弹球小游戏,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-11-11 身份证号码包含了丰富的信息,包括生日和性别,Python提供了处理和解析身份证号的功能,让我们能够从中提取出相关的信息,本文将介绍如何利用Python解析身份证号,获取持有者的年龄和性别信息,感兴趣的朋友可以参考下2023-12-12
身份证号码包含了丰富的信息,包括生日和性别,Python提供了处理和解析身份证号的功能,让我们能够从中提取出相关的信息,本文将介绍如何利用Python解析身份证号,获取持有者的年龄和性别信息,感兴趣的朋友可以参考下2023-12-12 在Python里一切都是对象(object),基本数据类型,如数字,字符串,函数都是对象。对象可以由类(class)进行创建。那么既然一切都是对象,那么类是对象吗?是的,类也是对象,那么又是谁创造了类呢?答案也很简单,也是类,一个能创作类的类,称之为(type)元类2022-06-06
在Python里一切都是对象(object),基本数据类型,如数字,字符串,函数都是对象。对象可以由类(class)进行创建。那么既然一切都是对象,那么类是对象吗?是的,类也是对象,那么又是谁创造了类呢?答案也很简单,也是类,一个能创作类的类,称之为(type)元类2022-06-06 这篇文章主要介绍了python爬虫请求头的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-12-12
这篇文章主要介绍了python爬虫请求头的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-12-12 xpath是最常用且最便捷高效的一种解析方式,通用型强,其不仅可以用于python语言中,还可以用于其他语言中,数据解析建议首先xpath2021-09-09
xpath是最常用且最便捷高效的一种解析方式,通用型强,其不仅可以用于python语言中,还可以用于其他语言中,数据解析建议首先xpath2021-09-09 这篇文章主要介绍了python正则表达式 匹配反斜杠的操作方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-08-08
这篇文章主要介绍了python正则表达式 匹配反斜杠的操作方法,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-08-08
Nginx搭建HTTPS服务器和强制使用HTTPS访问的方法
这篇文章主要介绍了Nginx搭建HTTPS服务器和强制使用HTTPS访问的方法,即从HTTP跳转到HTTPS,需要的朋友可以参考下2015-08-08 这篇文章主要介绍了Python 中单例模式的实现方法,文章围绕主题展开详细的内容介绍,具有一定的参考价值,感兴趣的小伙伴可以学习一下下面文章详细内容2022-08-08
这篇文章主要介绍了Python 中单例模式的实现方法,文章围绕主题展开详细的内容介绍,具有一定的参考价值,感兴趣的小伙伴可以学习一下下面文章详细内容2022-08-08 LyScript是一款x64dbg主动化操控插件,经过Python操控X64dbg,完成了远程动态调试,解决了逆向工作者剖析漏洞,寻觅指令片段,原生脚本不行强壮的问题。本文将利用LyScript插件实现批量打开关闭进程,感兴趣的可以了解一下2022-07-07
LyScript是一款x64dbg主动化操控插件,经过Python操控X64dbg,完成了远程动态调试,解决了逆向工作者剖析漏洞,寻觅指令片段,原生脚本不行强壮的问题。本文将利用LyScript插件实现批量打开关闭进程,感兴趣的可以了解一下2022-07-07










最新评论