
Java实现简易的分词器功能
业务需求:
生活中常见的搜索功能大概可分为以下几类:
- 单关键词。如“Notebook”
- 双关键词加空格。如“Super Notebook”
- 多关键词加多空格。如“Intel Super Notebook”
当然,还有四甚至五关键词,这些搜索场景在生活中可以用罕见来形容,不在我们的讨论范围。我们今天就以上三种生活中最常见的搜索形式进行探讨分析。业务需求也很简单,假设我们要完成一个搜索功能,业务层、持久层、控制层不在我们讨论的范围,仅讨论分词功能如何实现。
分析:
假设用户键入的搜索内容为以下内容:
Intel Super Notebook
我们可以利用Java中String强大而丰富的方法来慢慢拼凑一个小算法来达到目的。String中大多数方法的参数和返回值都与下标相关,那么,分析上述语句的下标,我们可发现如下内容:
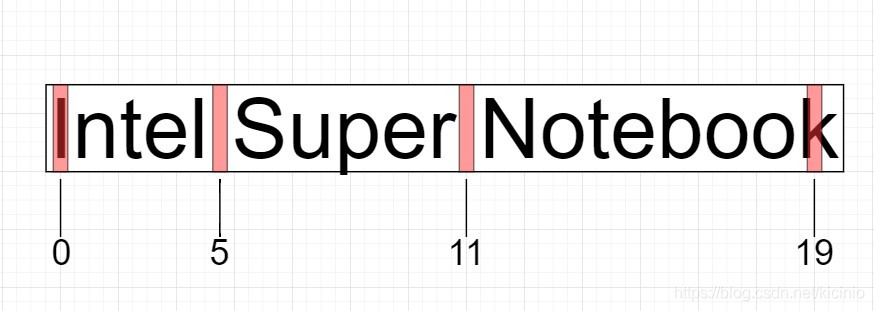
上述内容红色是我们分词的关键内容。对于一个语句而言(不是语言学上通俗的语句,因为该句没有主谓宾),重要的就是各单词或词组的首字母下标与该单词或词组后面最近一个空格。我们发现,Intel这个单词首字母下标为0,距离该单词后面最近的一个空格下标为5;Super首字母下标为距离该单词前面最近的一个空格的下标加1,也就是6;Notebook首字母下标为距离该单词前面最近的一个空格的下标加1,也就是12;最后就是该语句的尾下标,也就是19。
当然,实际情况会有用户多输入了两个甚至三个空格在某两个单词之间,例如如下形式:
Intel Super Notebook
(注意这里的空格为每个单词之间为2个)
这个问题很容易解决,我们把两个或三个空格替换为一个空格即可(为什么不是四个或者更多?因为现实情况是用户不太可能在各个单词之间连按多个空格),如下:
sentence = sentence.replace(" ", " ");
sentence = sentence.replace(" ", " ");
这样以来语句中就只存在单个空格了。
经过分析我们得知,若想对一个语句进行分词,就必须知道各个单词的起始下标才行。起始下标可以由空格的下标得知,那我们该如何得知空格的下标?
很简单,我们写个方法,通过迭代语句的每个单词,判断其是否存在空格即可。方法如下:
private int firstPosition(){
int first = 0;
for(int i = 0; i < sentence.length(); i++){
if(String.valueOf(sentence.charAt(i)).equals(" ")){
first = i;
return first;
}
}
return first;
}
这个方法的作用是判断一个语句中第一个空格的位置。既然有第一个了,肯定要有第二个了。要注意第一个内容是从0开始进行迭代,而第二个空格的判断方法要从第一个空格的位置加1开始,否则迭代的刚好还是第一个空格的位置。内容如下:
private int secondPosition(){
int second = 0;
for(int i = (firstPosition() + 1); i < sentence.length(); i++){
if(String.valueOf(sentence.charAt(i)).equals(" ")){
second = i;
return second;
}
}
return second;
}
第三个为什么不迭代?因为第三个单词之后就没有空格了,就到结尾了。
找出每个空格的下标索引后,我们还需知道语句中含有多少个空格,是没有,还是1个或2个(连续的重复空格在上文已经被替换为单个空格了)。方法如下:
private int countBlank(String s){
// Store single blank signal.
int amount = 0;
// If s contains single blank signal, and it will increse amount's value of 1 every loop times.
for(int i = 0; i < s.length(); i++){
if(String.valueOf(sentence.charAt(i)).equals(" ")){
amount++;
}
}
return amount;
}
拿到了空格的总个数及每个空格的下标,我们就可以写个方法进行分割了。由于我是采用了泛型集合作为数据源,这里的方法返回类型就为void。
我们先假设输入的仅有以下内容:
Intel
输入的仅有一个词组。我们先判断其空格的个数,发现为0,那么也不用进行什么操作了,直接添加其作为集合的数据。
public void divide(){
// Record every single blank signal's position.
int position1 = firstPosition();
int position2 = secondPosition();
if(sentence.contains(" ")){
} else{
words.add(sentence);
}
}
现在情况变为输入的内容如下:
Intel Super
我们知道了这个语句共有一个空格,下标为5,长度为11,那可以这样判断:是否包含空格,如果是,那就判断其空格数是否大于等于0,如果为真,就添加到数据源。接着判断其空格数是否大于等于1,如果真,进入下一层判断其空格数是否大于等于1其小于2,如果真,就添加到数据源。内容如下:
public void divide(){
// Record every single blank signal's position.
int position1 = firstPosition();
int position2 = secondPosition();
if(sentence.contains(" ")){
int blankAmount = countBlank(sentence);
if (blankAmount >= 0) {
words.add(sentence.substring(0, position1));
if (blankAmount >= 1) {
if(blankAmount >= 1 && blankAmount < 2)));
words.add(sentence.substring(position1, sentence.length()));
} else {
}
}
}
} else{
words.add(sentence);
}
}
下面就是较为全面的情况了:
Intel Super Notebook
我们判断完两个情况就看第三个情况。第三个单词其获取是通过第二个空格下标与语句长度得来。但第二个单词就要改为第一个空格下标加1与第二个空格下标加1了。那么至此分割方法也就完成了:
public String divide(){
// Record every single blank signal's position.
int position1 = firstPosition();
int position2 = secondPosition();
if(sentence.contains(" ")){
int blankAmount = countBlank(sentence);
if (blankAmount >= 0) {
words.add(sentence.substring(0, position1));
if (blankAmount >= 1) {
if(blankAmount >= 1 && blankAmount < 2){
words.add(sentence.substring(position1, sentence.length()));
} else {
words.add(sentence.substring(position1, position2));
if (blankAmount >= 2) {
words.add(sentence.substring(position2, sentence.length()));
}
}
}
}
} else{
words.add(sentence);
}
}
测试:
Intel Super Notebook
SIZE:3
POSITION(0): Intel
POSITION(1): Super
POSITION(2): Notebook
Intel Super Notebook
(注这里有重复且连续的空格)
SIZE:3
POSITION(0): Intel
POSITION(1): Super
POSITION(2): Notebook
英特尔 超级 笔记本
SIZE:3
POSITION(0): 英特尔
POSITION(1): 超级
POSITION(2): 笔记本
华为
SIZE:1
POSITION(0): 华为
完整代码:
class DivideWord{
private String sentence;
private List<String> words = new ArrayList<String>();
public DivideWord(String sentence) {
// Replace two or three blank signal that connected into single blank signal.
sentence = sentence.replace(" ", " ");
sentence = sentence.replace(" ", " ");
this.sentence = sentence;
}
private int countBlank(String s){
// Store single blank signal.
int amount = 0;
// If s contains single blank signal, and it will increse amount's value of 1 every loop times.
for(int i = 0; i < s.length(); i++){
if(String.valueOf(sentence.charAt(i)).equals(" ")){
amount++;
}
}
return amount;
}
private int firstPosition(){
int first = 0;
for(int i = 0; i < sentence.length(); i++){
if(String.valueOf(sentence.charAt(i)).equals(" ")){
first = i;
return first;
}
}
return first;
}
private int secondPosition(){
int second = 0;
for(int i = (firstPosition() + 1); i < sentence.length(); i++){
if(String.valueOf(sentence.charAt(i)).equals(" ")){
second = i;
return second;
}
}
return second;
}
public String divide(){
// Record every single blank signal's position.
int position1 = firstPosition();
int position2 = secondPosition();
if(sentence.contains(" ")){
int blankAmount = countBlank(sentence);
if (blankAmount >= 0) {
words.add(sentence.substring(0, position1));
if (blankAmount >= 1) {
if(blankAmount >= 1 && blankAmount < 2){
words.add(sentence.substring(position1, sentence.length()));
} else {
words.add(sentence.substring(position1, position2));
if (blankAmount >= 2) {
words.add(sentence.substring(position2, sentence.length()));
}
}
}
}
} else{
words.add(sentence);
}
}
public int getSize(){
return words.size();
}
public String getWord(int position){
return words.get(position);
}
}
public class DateGet {
public static void main(String[] args){
DivideWord divideWord = new DivideWord("英特尔");
divideWord.divide();
System.out.println("SIZE:" + divideWord.getSize());
System.out.println("POSITION :" + divideWord.getWord(0));
}
}
到此这篇关于Java实现简易的分词器功能的文章就介绍到这了,更多相关Java分词器功能内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

AsyncHttpClient的ConnectionSemaphore方法源码流程解读
这篇文章主要为大家介绍了AsyncHttpClient的ConnectionSemaphore方法源码流程解读,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-12-12 这篇文章主要介绍了java实现一个简单的Web服务器实例解析,分享了相关代码示例,小编觉得还是挺不错的,具有一定借鉴价值,需要的朋友可以参考下2018-02-02
这篇文章主要介绍了java实现一个简单的Web服务器实例解析,分享了相关代码示例,小编觉得还是挺不错的,具有一定借鉴价值,需要的朋友可以参考下2018-02-02 String是Java中的类,它提供一些预定义的方法,这些方法使基于字符串的问题解决方案更加容易,下面这篇文章主要给大家介绍了关于Java字符串操作的相关资料,需要的朋友可以参考下2021-11-11
String是Java中的类,它提供一些预定义的方法,这些方法使基于字符串的问题解决方案更加容易,下面这篇文章主要给大家介绍了关于Java字符串操作的相关资料,需要的朋友可以参考下2021-11-11 这篇文章主要介绍了解决FeignClient重试机制造成的接口幂等性问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-07-07
这篇文章主要介绍了解决FeignClient重试机制造成的接口幂等性问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-07-07 这篇文章主要为大家介绍了Spring事务aftercommit原理及实践,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-09-09
这篇文章主要为大家介绍了Spring事务aftercommit原理及实践,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-09-09 这篇文章主要为大家详细介绍了六个Java集合使用时需要注意的事项,文中的示例代码讲解详细,对我们学习java有一定的帮助,需要的可以参考一下2023-01-01
这篇文章主要为大家详细介绍了六个Java集合使用时需要注意的事项,文中的示例代码讲解详细,对我们学习java有一定的帮助,需要的可以参考一下2023-01-01 下面小编就为大家带来一篇全排列算法-递归与字典序的实现方法(Java) 。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-04-04
下面小编就为大家带来一篇全排列算法-递归与字典序的实现方法(Java) 。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-04-04 这篇文章主要介绍了Java中自动生成构造方法详解的相关资料,需要的朋友可以参考下2017-04-04
这篇文章主要介绍了Java中自动生成构造方法详解的相关资料,需要的朋友可以参考下2017-04-04 定义Spring Bcan的3种方式分别是:基于XML 的方式配置、基于注解扫播方式配置、基于元数据类的配置,本文就通过代码示例给大家详细讲讲这三种配置方式,需要的朋友可以参考下2023-12-12
定义Spring Bcan的3种方式分别是:基于XML 的方式配置、基于注解扫播方式配置、基于元数据类的配置,本文就通过代码示例给大家详细讲讲这三种配置方式,需要的朋友可以参考下2023-12-12 这篇文章主要介绍了Java简单冒泡排序示例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08
这篇文章主要介绍了Java简单冒泡排序示例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-08-08










最新评论