
分析mysql中一条SQL查询语句是如何执行的
一、MySQL 逻辑架构概览
MySQL 最重要、最与众不同的特性就是它的可插拔存储引擎架构(pluggable storage engine architecture),这种架构的设计将查询处理及其他系统任务和数据的存储/提取分离开来。来看官网的解释:
The MySQL pluggable storage engine architecture enables a database professional to select a specialized storage engine for a particular application need while being completely shielded from the need to manage any specific application coding requirements.
大致意思就是,MySQL 可插拔存储引擎架构使开发者能够为特定应用程序需求选择专门的存储引擎,同时完全无需管理任何特定应用程序编码要求。也就是说,尽管不同存储引擎具有不同的功能,但应用程序不受这些差异的影响。
如果应用程序更改带来了需要更改底层存储引擎的需求,或者需要添加一个或多个存储引擎来支持新需求,则无需进行重大的编码或流程更改即可使工作正常进行。 MySQL 服务器架构通过提供适用于跨存储引擎的一致且易于使用的 API,使应用程序免受存储引擎底层复杂性的影响。
MySQL 的逻辑架构图如下,参考《高性能 MySQL - 第 3 版》:
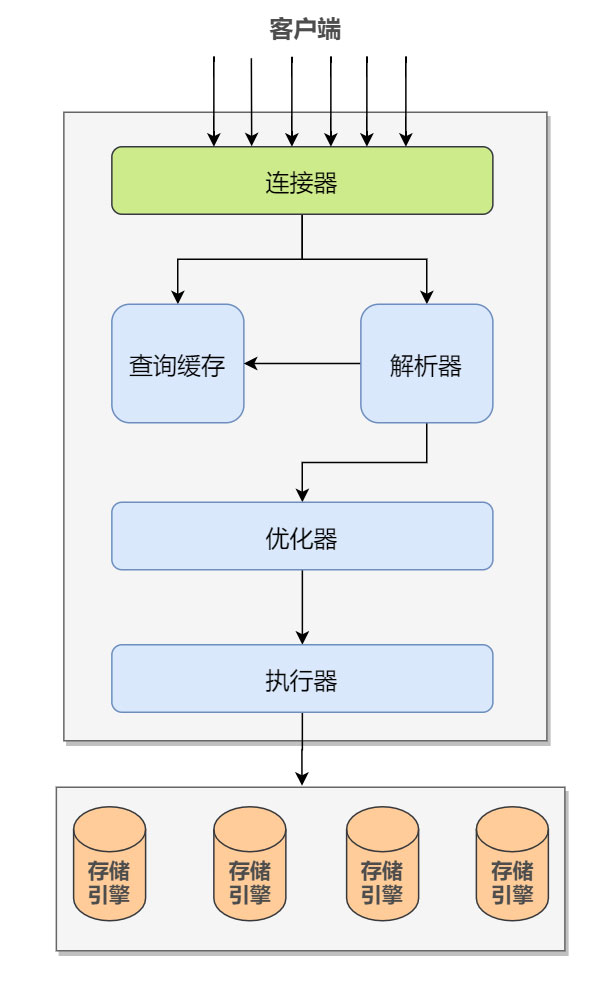
我们可以大致把 MySQL 的逻辑架构分成 Server 层和存储引擎层:
1)大多数 MySQL 的核心服务功能都在 Server 层,包括连接,查询解析、分析、优化、缓存以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
值得一提的是,Server 最上面的服务也就是连接器,拥有管理 MySQL 连接、权限验证的功能。显然这并非 MySQL 所独有,大多数基于网络的客户端/服务器的工具或者服务都有类似的架构。
2)第二层就是存储引擎(支持 InnoDB、MyISAM、Memory 等多个存储引擎)。存储引擎负责 MySQL 中数据的存储和提取,响应上层服务器的请求。每个存储引擎自然是有它的优势和劣势,不同的存储引擎之间无法相互通信,所以我们需要根据不同的场景来选择合适的存储引擎。
服务器通过 API 与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎 API 包含几十个底层函数,用于执行诸如 “开始一个事务” 或者 “根据主键提取一行记录” 等操作。
需要注意的是,在 MySQL 5.1 及之前的版本,MyISAM 是默认的存储引擎,而在 MySQL 5.5.5 后,InnoDB 成为了默认的存储引擎。
二、连接器(Connector)
MySQL 5.7 的官方文档中,是这样描述连接器的:
MySQL Connectors provide connectivity to the MySQL server for client programs.
MySQL 连接器为客户端程序提供到 MySQL 服务器的连接。 说得更细节一点的话,连接器其实会做两个事情,一个是管理 MySQL 连接,一个是权限验证。我们依次来解释下。
首先,要连接到 MySQL 服务器,我们通常需要提供 MySQL 用户名和密码,并且如果服务器运行在我们登录的机器以外的机器上,还需要指定一个主机名比如 host。 所以连接命令一般是这样的:
shell> mysql -h host -u user -p
Enter password: ********
当然了,如果在运行 MySQL 的同一台机器上登录,就可以省略主机名,只需使用以下内容:
shell> mysql -u user -p
上面这个命令各位应该都很熟悉。
OK,通过上述命令完成经典的 TCP 三次握手建立连接后,连接器就会根据你输入的用户名和密码来认证你的身份:
1)如果用户名或密码不对,你就会收到一个 "Access denied for user" 的错误,然后客户端程序结束执行。
2)如果用户名密码认证通过,你会看到下面这一串内容:

mysql> 就是在提示你 MySQL 已准备好了,你可以开始输入 SQL 语句了!
当然,连接器做的事情不仅仅是比对一下用户名和密码,它还会验证该用户是否具有执行某个特定查询的权限(例如,是否允许该用户对 world 数据库的 Country 表执行 SELECT 语句)。之后,这个连接里面的所有权限判断逻辑,都将依赖于此时读到的权限。
这意味着,当一个用户成功建立连接后,即使你在另一个终端用管理员账号对这个用户的权限做了修改,对当前已经存在连接的权限不会造成任何影响。
也就是说,当修改了用户权限后,只有再新建的连接才会使用新的权限设置。
当一个连接建立起来后,如果你没有后续的动作,那么这个连接就处于空闲状态(Sleep)。
事实上,对于一个 MySQL 连接来说(或者说一个线程),任何时刻都有一个状态,该状态表示了 MySQL 当前正在做什么。有很多种方式能查看当前的状态,最简单的是使用 SHOW FULL PROCESSLIST 命令(该命令返回结果中的 Command 列就表示当前的状态)。

在一个查询的生命周期中,状态会变化很多次。这里就不详细列出来了,上图中的 Sleep 状态就是说当前连接正在等待客户端发送新的请求,Query 状态表示当前连接正在执行查询或者正在将结果发送给客户端。
在 MyQL 的默认设置中,如果一个连接处在 Sleep 状态 8 小时(就是超过 8 小时没有使用),服务器将断开这条连接,后续在该连接上进行的所有操作都将失败。这个时间是由参数 wait_timeout 控制的:

三、查询缓存(Query Cache)
OK,连接建立完成后,我们就可以输入 select 语句进行查询了。执行逻辑就来到了第二步:查询缓存。
官方文档是这样解释 Query Cache 的:
The query cache stores the text of a SELECT statement together with the corresponding result that was sent to the client. If an identical statement is received later, the server retrieves the results from the query cache rather than parsing and executing the statement again. The query cache is shared among sessions, so a result set generated by one client can be sent in response to the same query issued by another client.
就是说查询缓存存储了 SELECT 语句的文本以及响应给客户端的相应结果。这样,如果服务器稍后接收到相同的 SELECT 语句,服务器会先从查询缓存中检索结果,而不是再次解析和执行该语句。查询缓存在 session 之间共享,因此可以发送一个客户端生成的结果集以响应另一个客户端发出的相同查询。
如果当前的查询恰好命中了查询缓存,那么在返回查询结果之前 MySQL 会检查一次用户权限。这仍然是无须解析查询SQL语句的,因为在查询缓存中已经存放了当前查询需要访问的表信息。
那么既然涉及到缓存,就必然绕不开缓存一致性问题了。值得庆幸的是,不需要我们进行额外操作,查询缓存并不会返回陈旧数据!
The query cache does not return stale data. When tables are modified, any relevant entries in the query cache are flushed.
当表被修改时,查询缓存中的任何相关条目都会被 flushed,注意,这里的 flushed 翻译为清空而不是刷新。
看起来好像还不错?不用我们手动操作,失效缓存就能够被自动清空。
然而,很不幸的是,正是由于这个特性,从 MySQL 5.7.20 开始,官方不再推荐使用查询缓存,并在 MySQL 8.0 中直接删除了查询缓存!
The query cache is deprecated as of MySQL 5.7.20, and is removed in MySQL 8.0.
其实不难理解,举个例子,对于一个流量很大的论坛项目来说,查询帖子表的需求每时每刻都存在,帖子也几乎每时每刻都在增加,那只要这个表一更新,这个表上所有的查询缓存都会被清空,这对于 MySQL 数据库的压力之大,可想而知了吧。费个劲把查询结果存起来,还没来得及使用呢,就被一个更新全清空了。
对于 MySQL 8.0 之前的版本来说,你可以将参数 query_cache_type 设置成 DEMAND,这样所有的 SQL 语句都不会再使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定,像下面这个语句一样:
mysql> select SQL_CACHE * from t1 where id = 1;
四、解析器(Parser)
如果没有命中或者没有开启查询缓存,MySQL 服务器接下来要做的就是将一条 SQL 语句转换成一个执行计划,再依照这个执行计划和存储引擎进行交互。这包括多个子阶段:解析 SQL、预处理、优化 SQL 执行计划。这个过程中任何错误(例如语法错误)都可能终止查询。
其中解析 SQL 和预处理就是解析器做的事情,优化 SQL 执行计划就是优化器做的事情。这里我们先说解析器。
这里《高性能 MySQL - 第 3 版》书中分得更细致点,解析器用来解析 SQL,预处理器则用来预处理,我暂且把它们都归为解析器吧
所谓解析 SQL 就是说,MySQL 通过关键字对 SQL 语句进行解析,并生成一棵对应的 “解析树”,用于根据语法规则来验证语句是否正确。例如,它将验证是否使用错误的关键字,或者使用关键字的顺序是否正确等,再或者它还会验证引号是否能前后正确匹配。
而预处理则会进一步检查解析树是否合法,例如,检查数据表和数据列是否存在,检查表名和字段名是否正确等。
五、优化器(Optimizer)
现在,解析树是合法的了,MySQL 已经知道你要做什么了。不过,一条查询可以有很多种执行计划,最后都返回相同的结果,那到底该选择哪种执行计划呢?
举个简单的例子:
mysql> select * from t1 where id = 10 and name = "good";
对于上面这个语句,可以先查找 name = good 再查找 id = 10,也可以先查找 id = 10 再查找 name = good,这两种不同的执行计划可能耗费的时间成本是不一样的。
那么优化器的作用就是找到这其中最好的执行计划。需要注意的是,这里的执行计划是一个数据结构,而不是和很多其他的关系型数据库那样会生成对应的字节码。
另外,优化器并不关心表使用的是什么存储引擎,但存储引擎对于优化查询是有影响的。优化器会请求存储引擎提供容量或某个具体操作的开销信息,以及表数据的统计信息等。
当优化器阶段完成后,这个语句的执行计划就确定下来了,就可以进入执行器阶段了。
六、执行器
和命中查询缓存一样,在开始执行 SQL 语句之前,执行器会先判断一下当前用户对这个表有没有执行查询的权限,如果没有,就会返回没有权限的错误。
权限认证完成后,MySQL 就会根据执行计划给出的指令逐步执行。在根据执行计划逐步执行的过程中,有大量的操作需要通过调用存储引擎实现的接口来完成,这些接口也就是我们称为 “handler API” 的接口。
查询中的每一个表由一个 handler 的实例表示。实际上,MySQL 在优化阶段就为每个表创建了一个 handler 实例,优化器根据这些实例的接口可以获取表的相关信息,包括表的所有列名、索引统计信息,等等。
举个例子:
mysql> select * from t1 where id = 10;
假设我们使用默认的 InnoDB 引擎,则执行器的执行流程大概是这样的(注意,如果 id 不是索引则会进行全表扫描,一行一行的查找,如果是索引则会在索引组织表中查询,比较负责。这里以非索引举例):
1)调用 InnoDB 引擎接口获取这个表的第一行记录,判断 id 值是不是 10,如果是则将这行记录存在一个集合中;如果不是则进入下一行的判断,直到取到这个表的最后一行
2)执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果返回给客户端
七、小结
总结下一条查询语句的执行过程:

1.MySQL 客户端与服务器间建立连接,客户端发送一条查询给服务器;
2.服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果;否则进入下一阶段;
3.服务器端进行 SQL 解析、预处理,生成合法的解析树;
4.再由优化器生成对应的执行计划;
5.MySQL 根据优化器生成的执行计划,调用相应的存储引擎的 API 来执行,并将执行结果返回给客户端。
以上就是分析mysql中一条SQL查询语句是如何执行的的详细内容,更多关于mysql查询语句是如何执行的的资料请关注脚本之家其它相关文章!
相关文章
 这篇文章给大家介绍了Mysql安装与配置调优,然后在文中给大家提到了mysql修改root密码的多种方法,需要的的朋友参考下吧2017-07-07
这篇文章给大家介绍了Mysql安装与配置调优,然后在文中给大家提到了mysql修改root密码的多种方法,需要的的朋友参考下吧2017-07-07 这篇文章主要介绍了mysql 生成连续日期及变量赋值的相关资料,分享内容及代码详细,具有一的参考价值,需要的小伙伴可以参考一下2022-03-03
这篇文章主要介绍了mysql 生成连续日期及变量赋值的相关资料,分享内容及代码详细,具有一的参考价值,需要的小伙伴可以参考一下2022-03-03 这篇文章主要介绍了mysql非主键自增长用法,结合实例形式分析了MySQL非主键自增长的基本设置、使用方法与操作注意事项,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了mysql非主键自增长用法,结合实例形式分析了MySQL非主键自增长的基本设置、使用方法与操作注意事项,需要的朋友可以参考下2020-02-02 下面小编就为大家带来一篇MySQL修改表一次添加多个列(字段)和索引的方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-01-01
下面小编就为大家带来一篇MySQL修改表一次添加多个列(字段)和索引的方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-01-01 在使用Navicat导入SQL文件时,有时会遇到报错问题,这通常与MySQL版本差异或严格模式设置有关,若报错提示rowsize长度过长,可能是因为MySQL的严格模式开启导致,解决方法是检查严格模式是否开启,若开启则需关闭2024-10-10
在使用Navicat导入SQL文件时,有时会遇到报错问题,这通常与MySQL版本差异或严格模式设置有关,若报错提示rowsize长度过长,可能是因为MySQL的严格模式开启导致,解决方法是检查严格模式是否开启,若开启则需关闭2024-10-10 这篇文章主要为大家详细介绍了mysql的内连接,左连接和右链接查询,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2022-03-03
这篇文章主要为大家详细介绍了mysql的内连接,左连接和右链接查询,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助2022-03-03 以下sql语句可以实现查找出一个表中的所有重复的记录2009-07-07
以下sql语句可以实现查找出一个表中的所有重复的记录2009-07-07 这篇文章主要介绍了MySQL图形化管理工具的使用及说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02
这篇文章主要介绍了MySQL图形化管理工具的使用及说明,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-02-02 这篇文章主要介绍了Mysql 实现多张无关联表查询数据并分页的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06
这篇文章主要介绍了Mysql 实现多张无关联表查询数据并分页的操作,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-06-06 这篇文章主要给大家介绍了关于MySQL alter命令修改表语法实例详解的相关资料,在MySQL中ALTER指令的作用是修改已存在的数据库表的结构,文中通过代码介绍的非常详细,需要的朋友可以参考下2024-01-01
这篇文章主要给大家介绍了关于MySQL alter命令修改表语法实例详解的相关资料,在MySQL中ALTER指令的作用是修改已存在的数据库表的结构,文中通过代码介绍的非常详细,需要的朋友可以参考下2024-01-01










最新评论