
利用Numba与Cython结合提升python运行效率详解
Numba
Numba是一个即时(JIT)编译器,它将Python代码转换为用于CPU和GPU的本地机器指令。代码可以在导入时、运行时或提前编译。
通过使用jit装饰器,使用Numba非常容易:
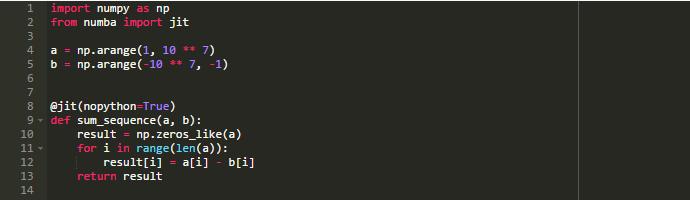

正如你所知道的,在Python中,所有代码块都被编译成字节码:
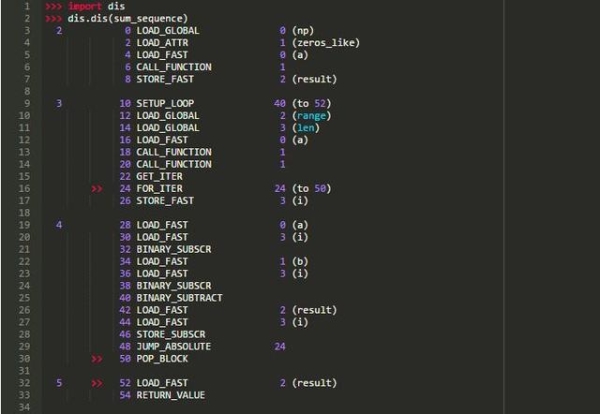
代码优化
为了优化Python代码,Numba从提供的函数中提取一个字节码,并在其上运行一组分析器。Python字节码包含一系列小而简单的指令,因此不必从Python实现中使用源代码就可以从字节码中重构函数的逻辑。转换的过程涉及多个阶段,但Numba将Python字节码转换为LLVM中间表示 (IR)。
请注意,LLVM IR是一种低级编程语言,它类似于汇编语法,与Python无关。
Numba 模式
Numba中有两种模式:nopython 和 object。前者不使用Python运行时并且在没有Python依赖项的情况下生成本机代码。 本机代码是静态类型的,运行非常快。而对象模式使用Python对象和Python C API,这通常不会带来显著的速度改进。在这两种情况下,Python代码都是使用LLVM编译的。
什么是LLVM?
LLVM是一种编译器,它采用代码的特殊中间表示(IR),并将其编译成本机代码。编译过程涉及许多额外的传递,其中编译器优化IR。LLVM工具链很好地优化了IR,不仅为Numba编译代码,而且优化Numba。整个系统大致如下:
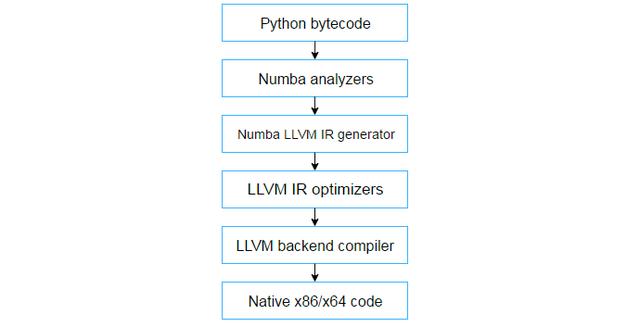
Python numba 体系结构
Numba的优势:
- 易用性
- 自动并行化
- 支持numpy操作和对象
- GPU支持
Numba的劣势:
多层的抽象使得调试和优化变得非常困难
在nopython模式下无法与Python及其模块进行交互
有限的类支持
Cython
取代分析字节码和生成IR,Cython使用Python语法的超集,它后来转换成C代码。在使用Cython时,基本上是用高级Python语法编写C代码。
在Cython中,通常不必担心Python包装器和低级API调用,因为所有交互都会自动扩展到合适的C代码。
与Numba不同,所有的Cython代码应该在专门文件中与常规Python代码分开。Cython将这些文件解析并转换成C代码,然后使用提供的C编译器 (例如, gcc)编译它。
Python代码已经是有效的Cython代码。

但是,类型版本工作得更快。
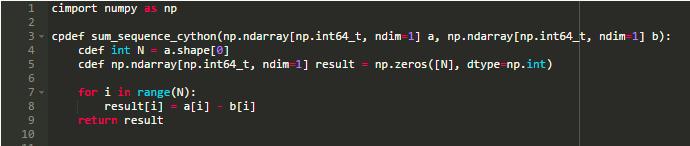

编写快速Cython代码需要理解C和Python内部结构。如果你熟悉C,你的Cython代码可以运行得和C代码一样快。
Cython的优势:
- 通过Python API的使用控制
- 与C/C++库和C/C++代码的简单接口
- 并行执行支持
- 支持Python类,在C中提供面向对象的特性
Cython的劣势:
- 学习曲线
- 需要C和Python内部专业技术
- 模块的组织不方便
Numba 对 Cython
就个人而言,我更喜欢小项目和ETL实验用Numba。你可以将其插入现有项目中。如果我需要启动一个大项目或为C库编写包装器,我将使用Cython,因为它提供更多的控制和更容易调试。
此外,Cython是许多库的标准,如pandas、scikit-learn、scipy、Spacy、gensim和lxml。
以上就是利用Numba与Cython结合提升python运行效率详解的详细内容,更多关于提升python运行效率的资料请关注脚本之家其它相关文章!
相关文章

python 将数据保存为excel的xls格式(实例讲解)
下面小编就为大家分享一篇python 将数据保存为excel的xls格式(实例讲解),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-05-05 这篇文章主要介绍了python时间与Unix时间戳相互转换方法详解,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了python时间与Unix时间戳相互转换方法详解,需要的朋友可以参考下2020-02-02 在Python中else最常见的用法就是用在判断语句中,其实还可以用在循环语句和异常处理中。 下面来总结一下else的用法:2021-06-06
在Python中else最常见的用法就是用在判断语句中,其实还可以用在循环语句和异常处理中。 下面来总结一下else的用法:2021-06-06 这篇文章主要介绍了使用pth文件添加Python环境变量方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05
这篇文章主要介绍了使用pth文件添加Python环境变量方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05 这篇文章主要介绍了详解pandas数据合并与重塑(pd.concat篇),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07
这篇文章主要介绍了详解pandas数据合并与重塑(pd.concat篇),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-07-07 这篇文章主要介绍了Python找出9个连续的空闲端口的方法,感兴趣的小伙伴们可以参考一下2016-02-02
这篇文章主要介绍了Python找出9个连续的空闲端口的方法,感兴趣的小伙伴们可以参考一下2016-02-02 这篇文章主要介绍了Python编程实现双链表,栈,队列及二叉树的方法,结合具体实例形式分析了Python简单实现数据结构中双链表,栈,队列及二叉树相关操作技巧,需要的朋友可以参考下2017-11-11
这篇文章主要介绍了Python编程实现双链表,栈,队列及二叉树的方法,结合具体实例形式分析了Python简单实现数据结构中双链表,栈,队列及二叉树相关操作技巧,需要的朋友可以参考下2017-11-11 这篇文章主要介绍了用Cython加速Python到“起飞”,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-08-08
这篇文章主要介绍了用Cython加速Python到“起飞”,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-08-08 在本篇文章里小编给大家整理的是关于2020年8个效率最高的爬虫框架知识点,需要的朋友们可以学习下。2020-07-07
在本篇文章里小编给大家整理的是关于2020年8个效率最高的爬虫框架知识点,需要的朋友们可以学习下。2020-07-07 @符号在Python中最常见的使用情况是在装饰器中,本文主要介绍了Python中@符号的用法小结,具有一定的参考价值,感兴趣的可以了解一下2023-09-09
@符号在Python中最常见的使用情况是在装饰器中,本文主要介绍了Python中@符号的用法小结,具有一定的参考价值,感兴趣的可以了解一下2023-09-09










最新评论