
如何使用python爬取知乎热榜Top50数据
更新时间:2021年09月27日 09:45:30 作者:小狐狸梦想去童话镇
主要是爬取知乎热榜的问题及点赞数比较高的答案,通过requests请求库进行爬取,对大家的学习或工作具有一定的价值,需要的朋友可以参考下
1、导入第三方库
import urllib.request,urllib.error #请求网页 from bs4 import BeautifulSoup # 解析数据 import sqlite3 # 导入数据库 import re # 正则表达式 import time # 获取当前时间
2、程序的主函数
def main():
# 声明爬取网页
baseurl = "https://www.zhihu.com/hot"
# 爬取网页
datalist = getData(baseurl)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime()) #
dbpath = "zhihuTop50 " + dbname
saveData(datalist,dbpath)
3、正则表达式匹配数据
#正则表达式 findlink = re.compile(r'<a class="css-hi1lih" href="(.*?)" rel="external nofollow" rel="external nofollow" ') #问题链接 findid = re.compile(r'<div class="css-blkmyu">(.*?)</div>') #问题排名 findtitle = re.compile(r'<h1 class="css-3yucnr">(.*?)</h1>') #问题标题 findintroduce = re.compile(r'<div class="css-1o6sw4j">(.*?)</div>') #简要介绍 findscore = re.compile(r'<div class="css-1iqwfle">(.*?)</div>') #热门评分 findimg = re.compile(r'<img class="css-uw6cz9" src="(.*?)"/>') #文章配图
4、程序运行结果
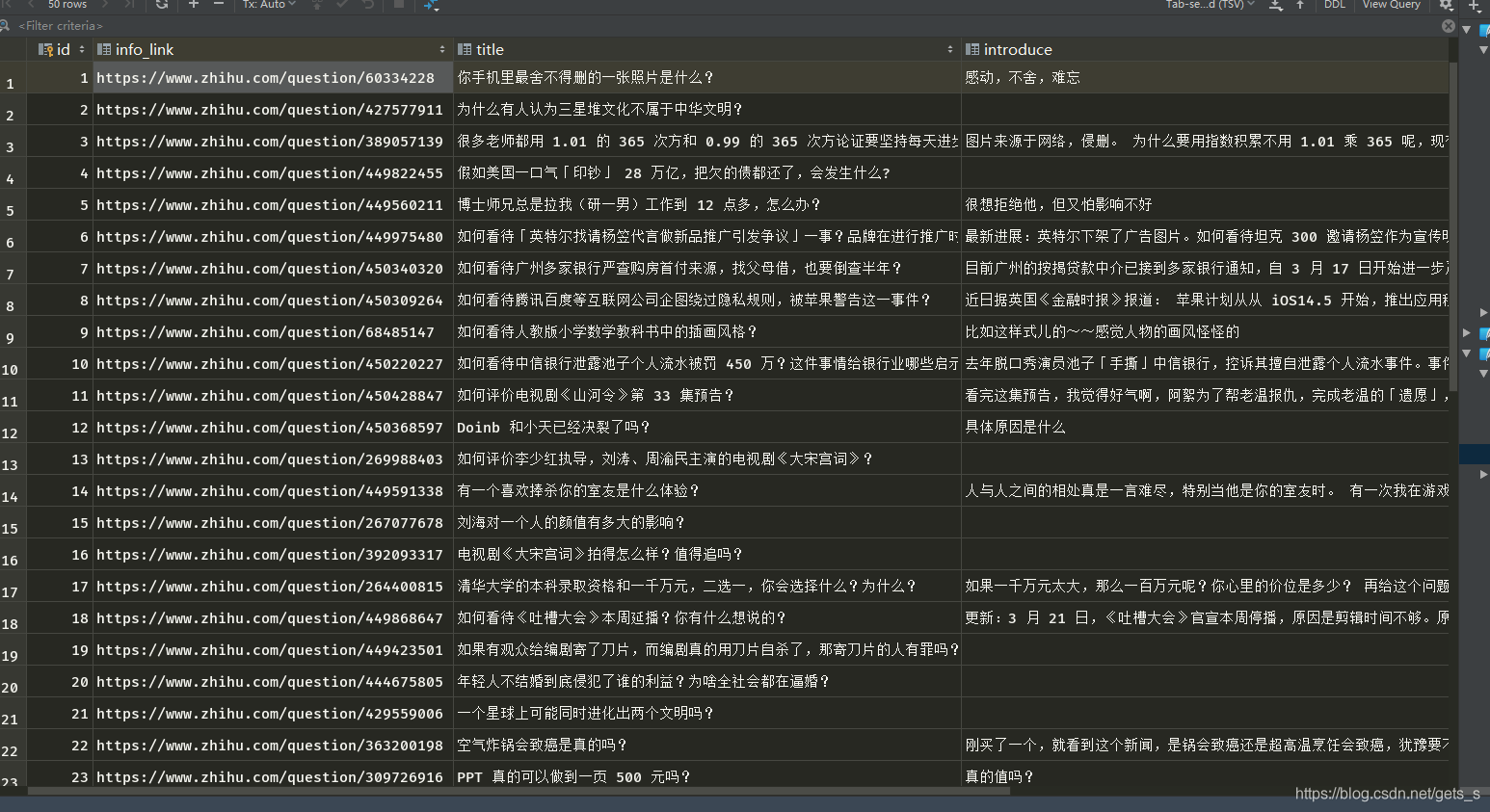
5、程序源代码
import urllib.request,urllib.error
from bs4 import BeautifulSoup
import sqlite3
import re
import time
def main():
# 声明爬取网页
baseurl = "https://www.zhihu.com/hot"
# 爬取网页
datalist = getData(baseurl)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "zhihuTop50 " + dbname
saveData(datalist,dbpath)
print()
#正则表达式
findlink = re.compile(r'<a class="css-hi1lih" href="(.*?)" rel="external nofollow" rel="external nofollow" ') #问题链接
findid = re.compile(r'<div class="css-blkmyu">(.*?)</div>') #问题排名
findtitle = re.compile(r'<h1 class="css-3yucnr">(.*?)</h1>') #问题标题
findintroduce = re.compile(r'<div class="css-1o6sw4j">(.*?)</div>') #简要介绍
findscore = re.compile(r'<div class="css-1iqwfle">(.*?)</div>') #热门评分
findimg = re.compile(r'<img class="css-uw6cz9" src="(.*?)"/>') #文章配图
def getData(baseurl):
datalist = []
html = askURL(baseurl)
# print(html)
soup = BeautifulSoup(html,'html.parser')
for item in soup.find_all('a',class_="css-hi1lih"):
# print(item)
data = []
item = str(item)
Id = re.findall(findid,item)
if(len(Id) == 0):
Id = re.findall(r'<div class="css-mm8qdi">(.*?)</div>',item)[0]
else: Id = Id[0]
data.append(Id)
# print(Id)
Link = re.findall(findlink,item)[0]
data.append(Link)
# print(Link)
Title = re.findall(findtitle,item)[0]
data.append(Title)
# print(Title)
Introduce = re.findall(findintroduce,item)
if(len(Introduce) == 0):
Introduce = " "
else:Introduce = Introduce[0]
data.append(Introduce)
# print(Introduce)
Score = re.findall(findscore,item)[0]
data.append(Score)
# print(Score)
Img = re.findall(findimg,item)
if (len(Img) == 0):
Img = " "
else: Img = Img[0]
data.append(Img)
# print(Img)
datalist.append(data)
return datalist
def askURL(baseurl):
# 设置请求头
head = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/80.0.3987.163Safari/537.36"
"User-Agent": "Mozilla / 5.0(iPhone;CPUiPhoneOS13_2_3likeMacOSX) AppleWebKit / 605.1.15(KHTML, likeGecko) Version / 13.0.3Mobile / 15E148Safari / 604.1"
}
request = urllib.request.Request(baseurl, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
print()
def saveData(datalist,dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
sql = '''
insert into Top50(
id,info_link,title,introduce,score,img)
values("%s","%s","%s","%s","%s","%s")'''%(data[0],data[1],data[2],data[3],data[4],data[5])
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
def init_db(dbpath):
sql = '''
create table Top50
(
id integer primary key autoincrement,
info_link text,
title text,
introduce text,
score text,
img text
)
'''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
if __name__ =="__main__":
main()
到此这篇关于如何使用python爬取知乎热榜Top50数据的文章就介绍到这了,更多相关python 爬取知乎内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 本文主要介绍了详解pytest+Allure搭建方法以及生成报告常用操作,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-09-09
本文主要介绍了详解pytest+Allure搭建方法以及生成报告常用操作,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-09-09
Pycharm中pyqt工具配置(Qt Designer、PyUIC、PyRCC)
Pycharm中进行扩展工具设置,从而实现在pycharm中打开Qt Designer、Ui文件生成Py文件、资源文件生成Py文件三个功能,需要的朋友们下面随着小编来一起学习学习吧2023-07-07 这篇文章主要介绍了离线安装Pyecharts的步骤以及依赖包流程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2017-03-03
这篇文章主要介绍了离线安装Pyecharts的步骤以及依赖包流程,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2017-03-03 这篇文章主要介绍了python 命令行传入参数实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了python 命令行传入参数实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-08-08 这篇文章主要介绍了python实现对指定输入的字符串逆序输出的6种方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-04-04
这篇文章主要介绍了python实现对指定输入的字符串逆序输出的6种方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-04-04 下面小编就为大家分享一篇JavaScript实现一维数组转化为二维数组,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04
下面小编就为大家分享一篇JavaScript实现一维数组转化为二维数组,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-04-04 学习Python时新手可能会遇到缩进错误、忘记引入模块、使用未定义的变量、变量作用域理解不当、字符串格式化错误等问题,本文详细介绍了这些常见陷阱及其解决方案,文中通过代码介绍的非常详细,需要的朋友可以参考下2024-10-10
学习Python时新手可能会遇到缩进错误、忘记引入模块、使用未定义的变量、变量作用域理解不当、字符串格式化错误等问题,本文详细介绍了这些常见陷阱及其解决方案,文中通过代码介绍的非常详细,需要的朋友可以参考下2024-10-10 这篇文章主要介绍了python 实现表情识别的示例代码,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-11-11
这篇文章主要介绍了python 实现表情识别的示例代码,帮助大家更好的理解和学习python,感兴趣的朋友可以了解下2020-11-11 pytorch它是一个基于Python的开源深度学习框架,它提供了两个核心功能:张量计算和自动求导,这篇文章主要介绍了使用pytorch进行张量计算、自动求导和神经网络构建,需要的朋友可以参考下2023-04-04
pytorch它是一个基于Python的开源深度学习框架,它提供了两个核心功能:张量计算和自动求导,这篇文章主要介绍了使用pytorch进行张量计算、自动求导和神经网络构建,需要的朋友可以参考下2023-04-04
python中关于requests里的timeout()用法
这篇文章主要介绍了python中关于requests里的timeout()用法,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-08-08










最新评论