
Python实战爬虫之女友欲买文胸不知何色更美
情景再现
今日天气尚好,女友忽然欲买文胸,但不知何色更美,遂命吾剖析何色买者益众,为点议,事后而奖励之。
本文关键词
协程并发😊、IP被封😳、IP代理😏、代理被封😭、一种植物🌿
挑个“软柿子”
打开京东,直接搜 【文胸】,挑个评论最多的

进入详情页,往下滑,可以看到商品介绍啥的,同时商品评价也在这里。
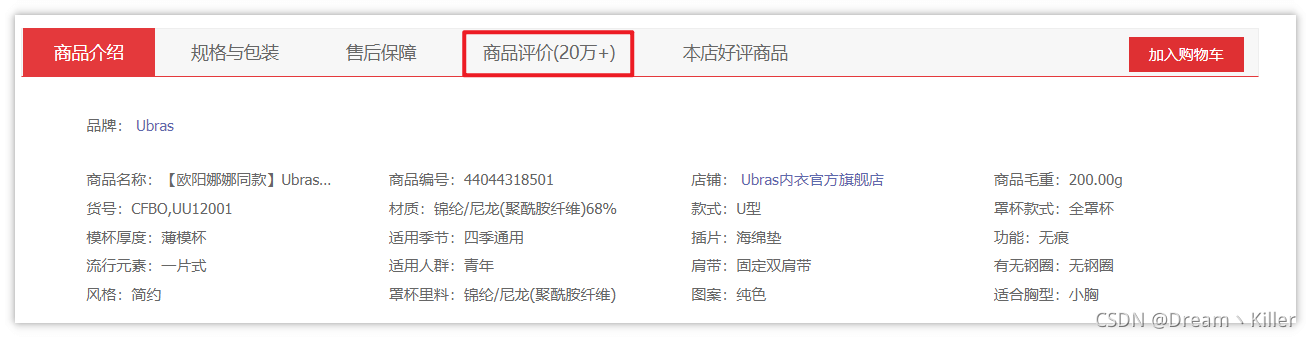
接下来重头戏,F12 打开 开发者工具,选择 Network,然后点击全部评价,抓取数据包。
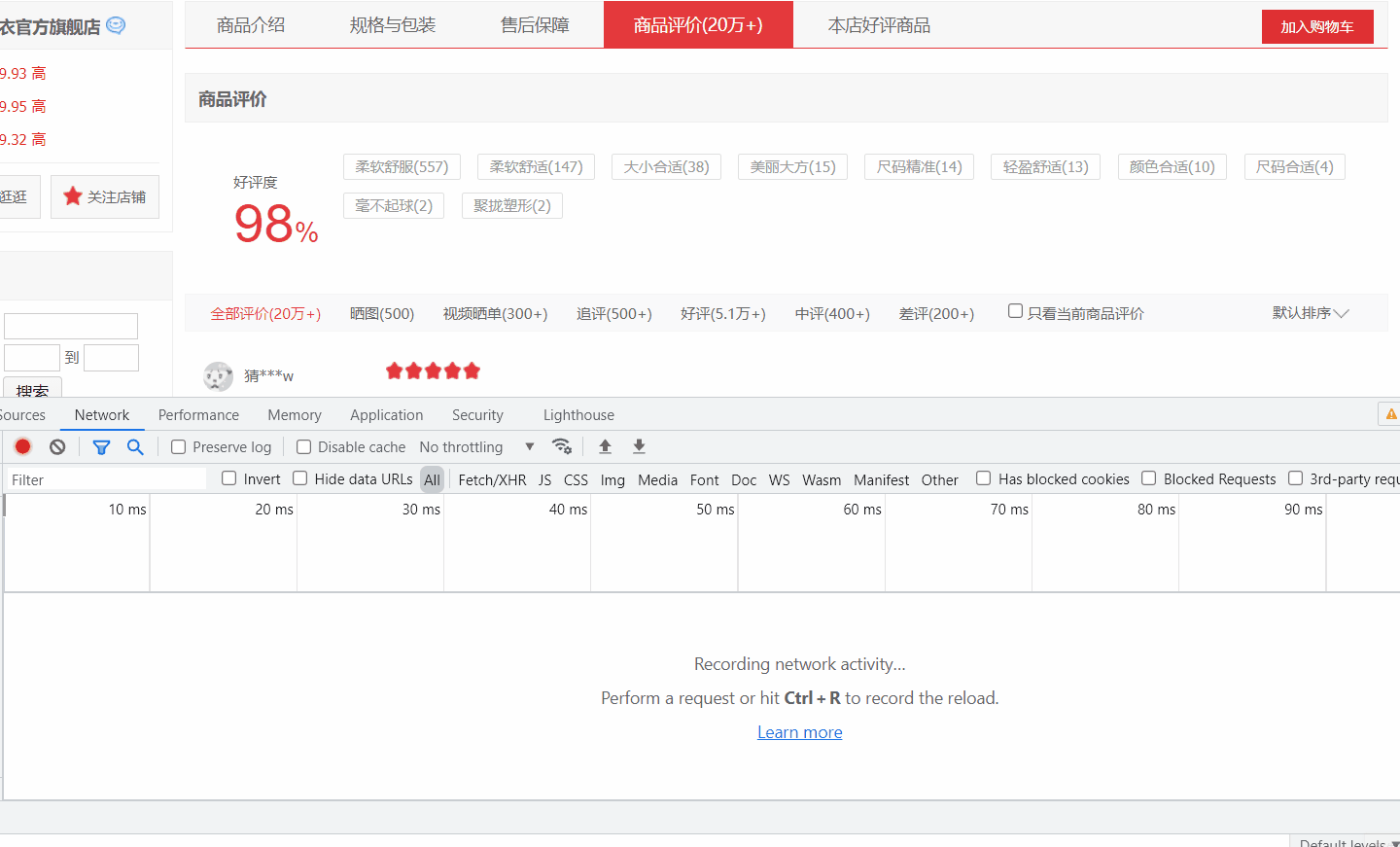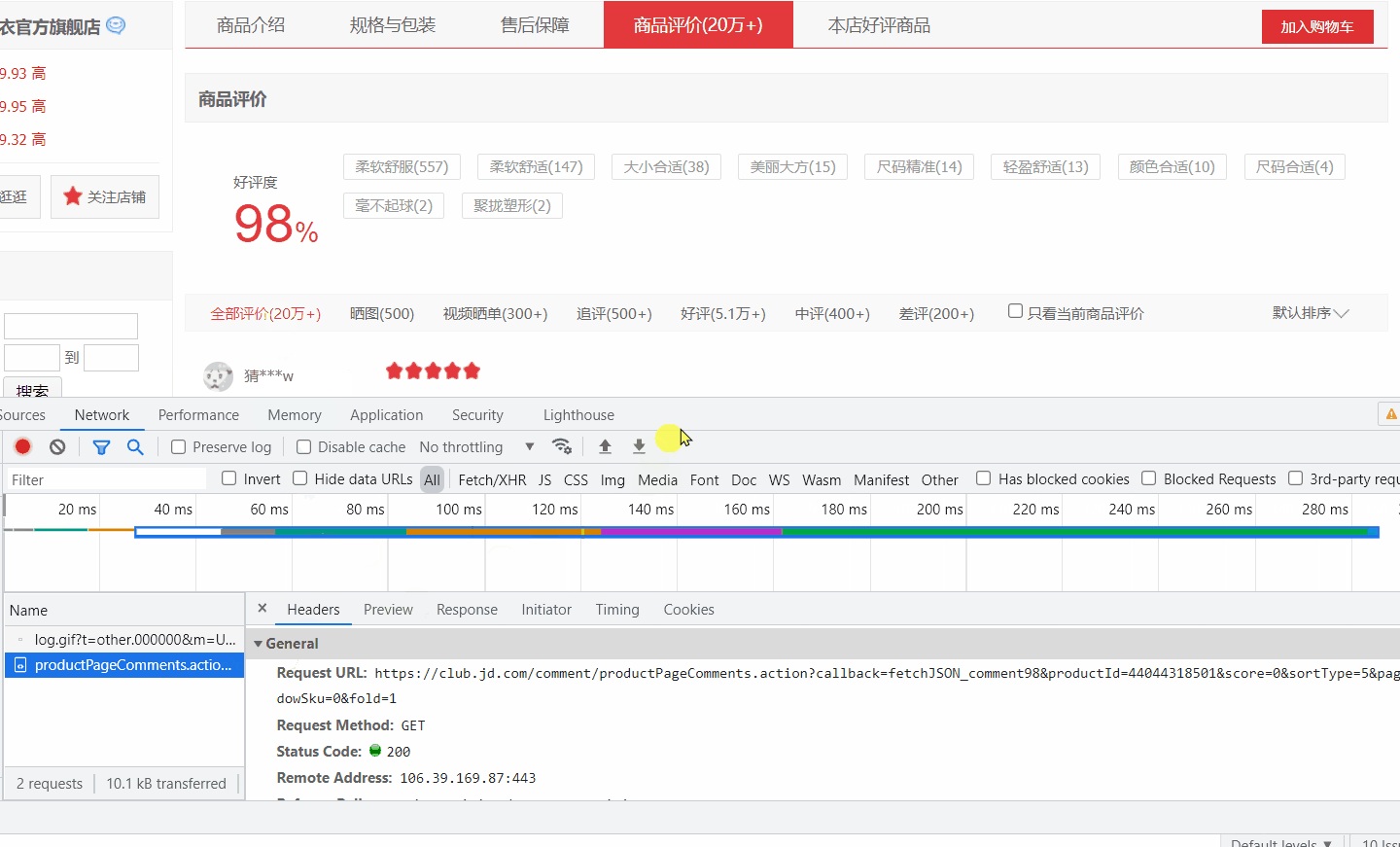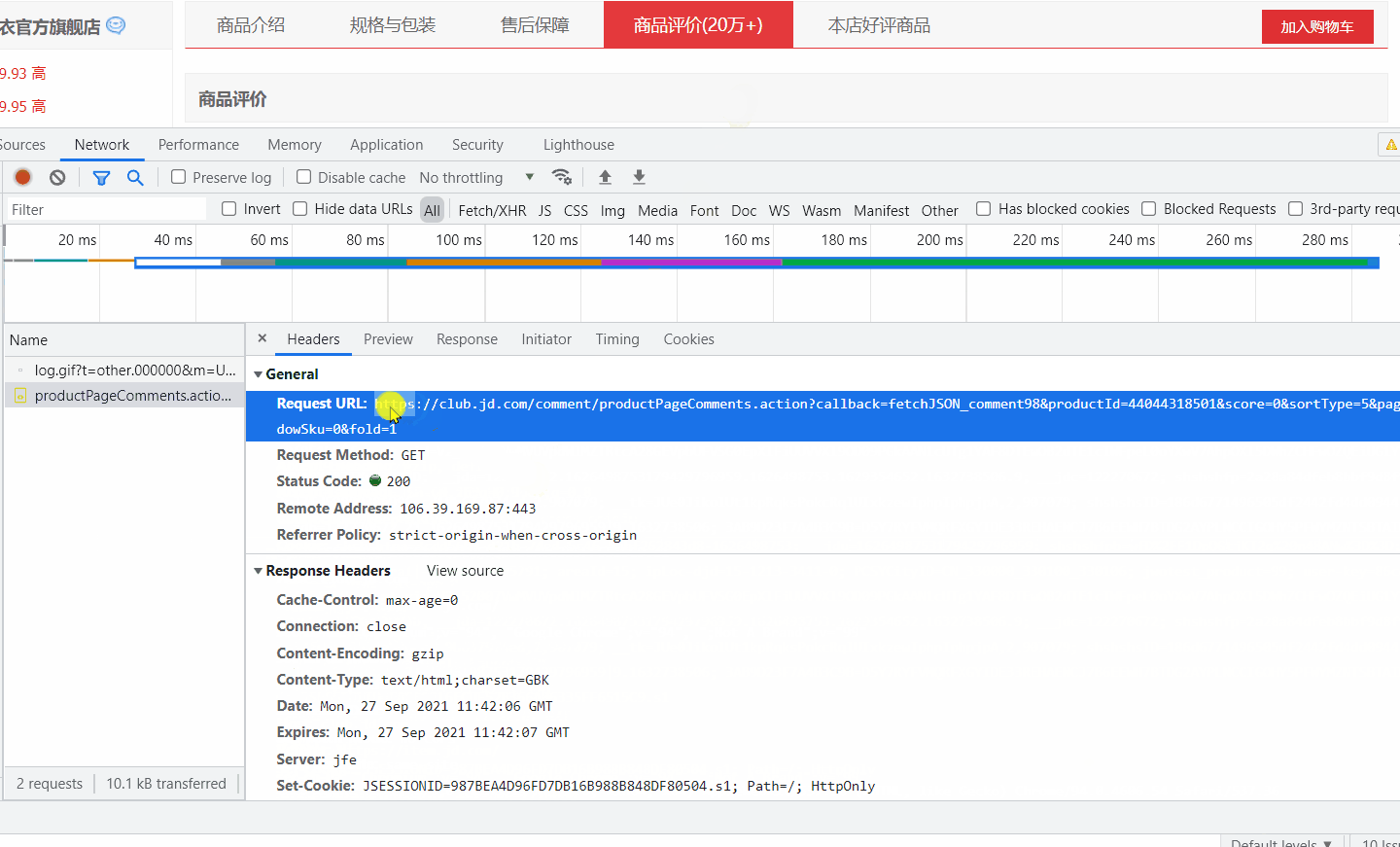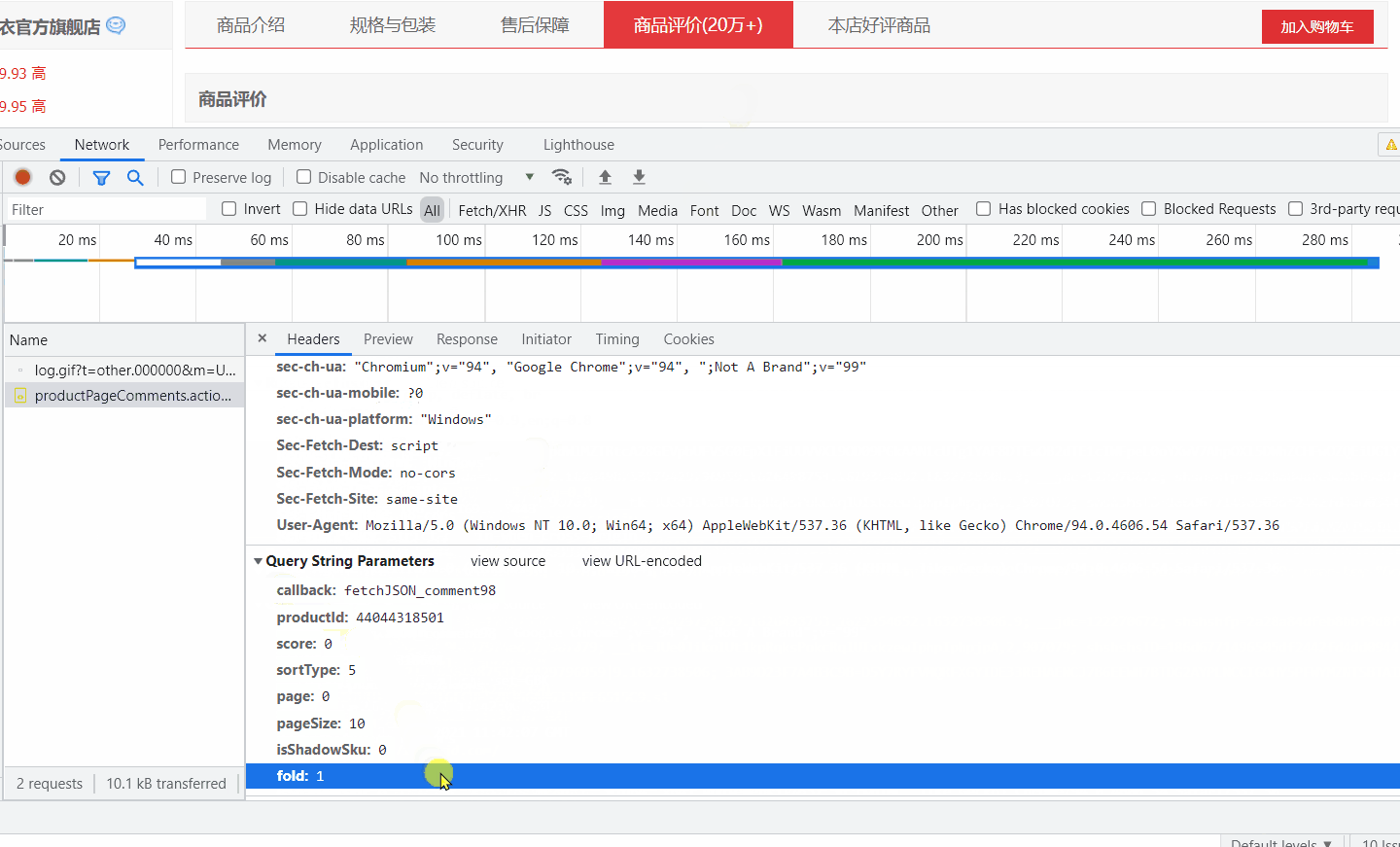
将 url 打开,发现确实是评论数据。
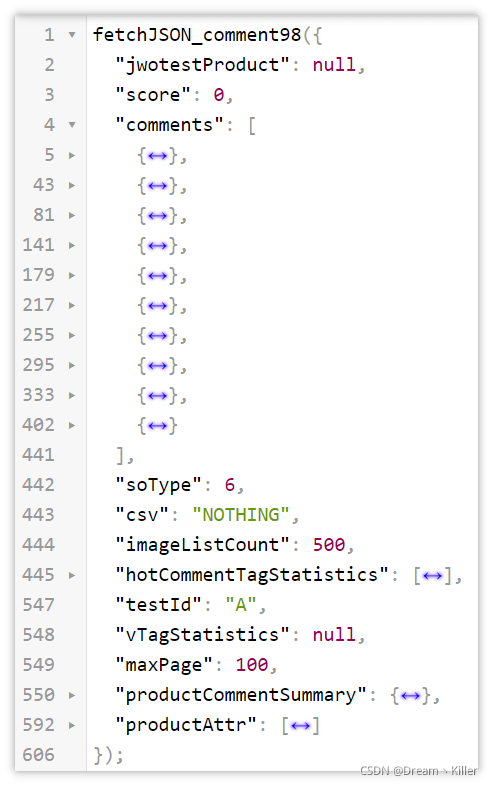
单页爬取
那我们先写个小 demo 来尝试爬取这页的代码,看看有没有什么问题。
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
params = {
'callback':'fetchJSON_comment98',
'productId':'35152509650',
'score':'0',
'sortType':'6',
'page': '5',
'pageSize':'10',
'isShadowSku':'0',
'rid':'0',
'fold':'1'
}
url = 'https://club.jd.com/comment/productPageComments.action?'
page_text = requests.get(url=url, headers=headers, params=params).text
page_text
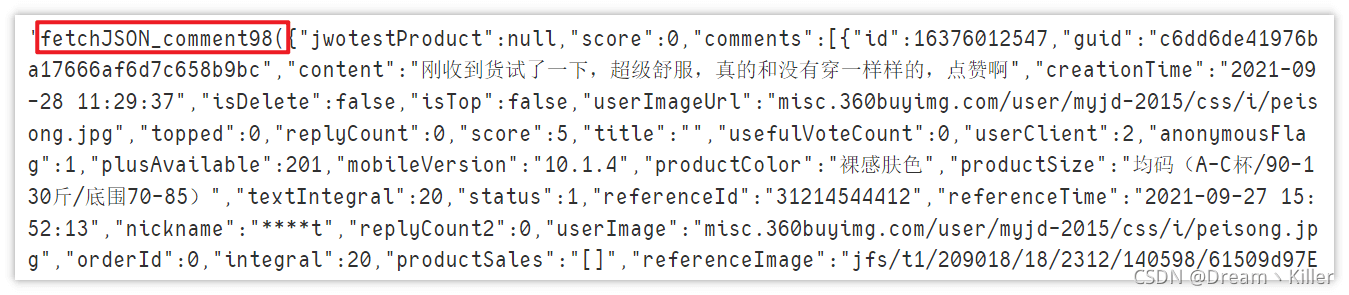
数据处理
数据是获取了,但前面多了一些没用的字符(后面也有),很明显不能直接转成 json 格式,需要处理一下。
page_text = page_text[20: len(page_text) - 2] data = json.loads(page_text) data
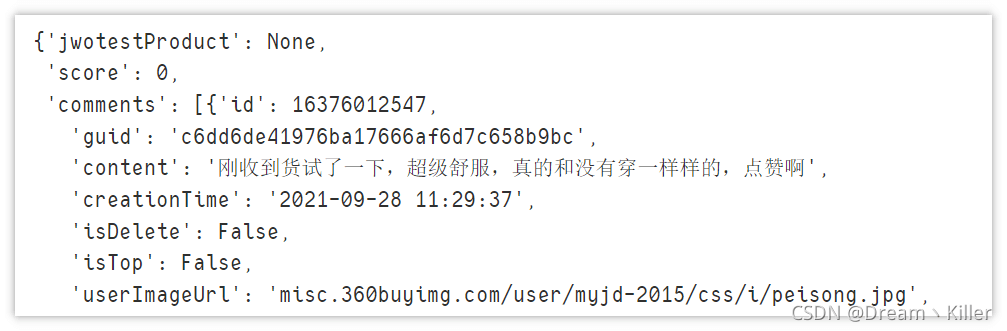
现在数据格式处理好了,可以上手解析数据,提取我们所需要的部分。这里我们只提取 id(评论id)、color(产品颜色)、comment(评价)、time(评价时间)。
import pandas as pd
df = pd.DataFrame({'id': [],
'color': [],
'comment': [],
'time': []})
for info in data['comments']:
df = df.append({'id': info['id'],
'color': info['productColor'],
'comment': info['content'],
'time': info['creationTime']},
ignore_index=True)
df

翻页操作
那么接下来就要寻找翻页的关键了,下面用同样的方法获取第二页、第三页的url,进行对比。
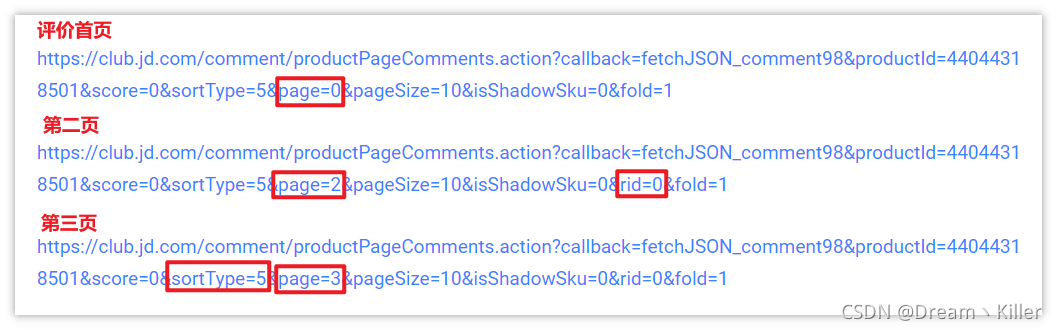
简单分析一下,page 字段是页数,翻页会用到,值得注意的是 sortType,字面意思是排序类型,猜测排序方式可能是:热度、时间等。经过测试发现 sortType=5 肯定不是按时间排序的,应该是热度,我们要获取按时间排序的,这样后期比较好处理,然后试了几个值,最后确定当 sortType=6 时是按评价时间排序。图中最后还有个 rid=0 ,不清楚什么作用,我爬取两个相同的url(一个加 rid 一个不加),测试结果是相同的,所以不用管它。
撸代码
先写爬取结果:开始想爬 10000 条评价,结果请求过多IP凉了,从IP池整了丶代理,也没顶住,拼死拼活整了1000条,时间不够,如果时间和IP充足,随便爬。经过测试发现这个IP封锁时间不会超过一天,第二天我跑了一下也有数据。下面看看主要的代码。
主调度函数
设置爬取的 url 列表,windows 环境下记得限制并发量,不然报错,将爬取的任务添加到 tasks 中,挂起任务。
async def main(loop):
# 获取url列表
page_list = list(range(0, 1000))
# 限制并发量
semaphore = asyncio.Semaphore(500)
# 创建任务对象并添加到任务列表中
tasks = [loop.create_task(get_page_text(page, semaphore)) for page in page_list]
# 挂起任务列表
await asyncio.wait(tasks)
页面抓取函数
抓取方法和上面讲述的基本一致,只不过换成 aiohttp 进行请求,对于SSL证书的验证也已设置。程序执行后直接进行解析保存。
async def get_page_text(page, semaphore):
async with semaphore:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
params = {
'callback': 'fetchJSON_comment98',
'productId': '35152509650',
'score': '0',
'sortType': '6',
'page': f'{page}',
'pageSize': '10',
'isShadowSku': '0',
# 'rid': '0',
'fold': '1'
}
url = 'https://club.jd.com/comment/productPageComments.action?'
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
while True:
try:
async with session.get(url=url, proxy='http://' + choice(proxy_list), headers=headers, params=params,
timeout=4) as response:
# 遇到IO请求挂起当前任务,等IO操作完成执行之后的代码,当协程挂起时,事件循环可以去执行其他任务。
page_text = await response.text()
# 未成功获取数据时,更换ip继续请求
if response.status != 200:
continue
print(f"第{page}页爬取完成!")
break
except Exception as e:
print(e)
# 捕获异常,继续请求
continue
return parse_page_text(page_text)
解析保存函数
将 json 数据解析以追加的形式保存到 csv 中。
def parse_page_text(page_text):
page_text = page_text[20: len(page_text) - 2]
data = json.loads(page_text)
df = pd.DataFrame({'id': [],
'color': [],
'comment': [],
'time': []})
for info in data['comments']:
df = df.append({'id': info['id'],
'color': info['productColor'],
'comment': info['content'],
'time': info['creationTime']},
ignore_index=True)
header = False if Path.exists(Path('评价信息.csv')) else True
df.to_csv('评价信息.csv', index=False, mode='a', header=header)
print('已保存')
可视化
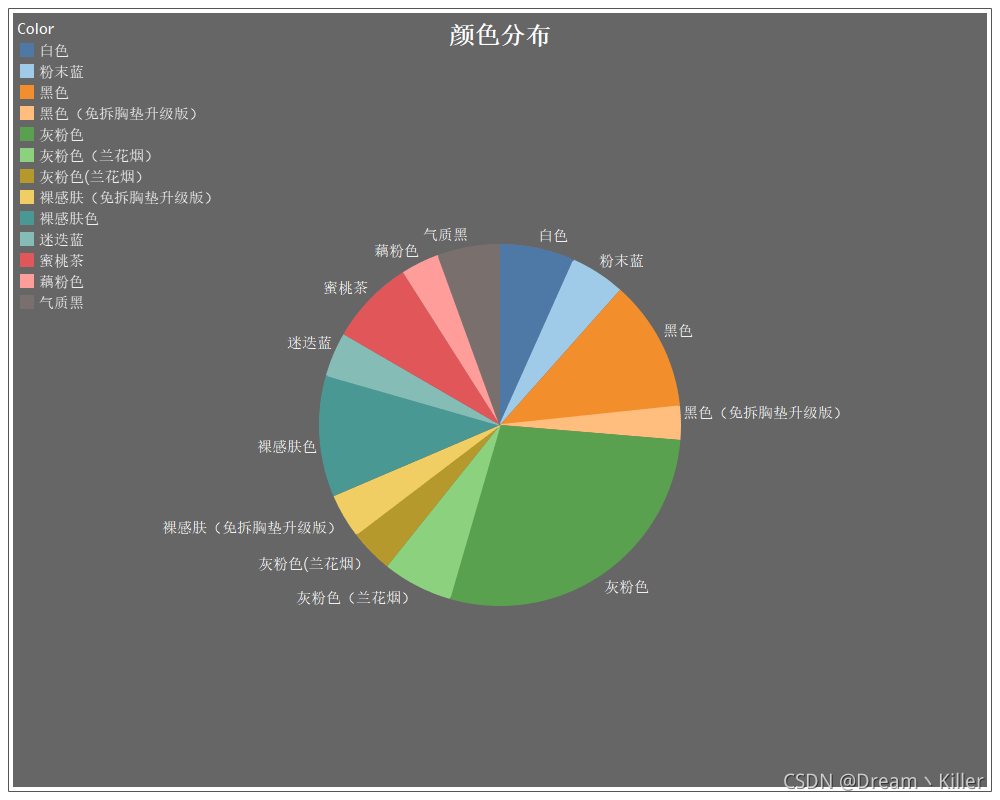
颜色分布
排名前三分别是灰粉色、黑色、裸感肤色,多的不说,自己体会哈。
评价词云图
可以看出评价的关键词大多是对上身感觉的一些描述,穿着舒服当然是第一位的~

完结撒花,该向女朋友汇报工作了~
别忘记收藏哦~

到此这篇关于Python实战爬虫之女友欲买文胸不知何色更美的文章就介绍到这了,更多相关Python 爬虫文胸内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了python中对数据进行各种排序的方法,本文给大家介绍的非常详细,具有一定的参考借鉴价值 ,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了python中对数据进行各种排序的方法,本文给大家介绍的非常详细,具有一定的参考借鉴价值 ,需要的朋友可以参考下2019-07-07
安装python3.7编译器后如何正确安装opnecv的方法详解
这篇文章主要介绍了安装python3.7编译器后如何正确安装opnecv,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-06-06 这篇文章主要介绍了Flask教程之重定向与错误处理,结合实例形式分析了flask框架重定向、状态码判断及错误处理相关操作技巧,需要的朋友可以参考下2019-08-08
这篇文章主要介绍了Flask教程之重定向与错误处理,结合实例形式分析了flask框架重定向、状态码判断及错误处理相关操作技巧,需要的朋友可以参考下2019-08-08 这篇文章主要给大家介绍了关于Python中zip()函数的简单用法,文中通过示例代码介绍的非常详细,对大家学习或者使用Python具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-09-09
这篇文章主要给大家介绍了关于Python中zip()函数的简单用法,文中通过示例代码介绍的非常详细,对大家学习或者使用Python具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-09-09 文件是无处不在的,,无论我们使用哪种编程语言,处理文件对于每个程序员都是必不可少的,下面这篇文章主要给大家介绍了关于python文件的读取、写入与删除的相关资料,文中通过实例代码和图文介绍的非常详细,需要的朋友可以参考下2023-06-06
文件是无处不在的,,无论我们使用哪种编程语言,处理文件对于每个程序员都是必不可少的,下面这篇文章主要给大家介绍了关于python文件的读取、写入与删除的相关资料,文中通过实例代码和图文介绍的非常详细,需要的朋友可以参考下2023-06-06 今天小编就为大家分享一篇python 处理数字,把大于上限的数字置零实现方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01
今天小编就为大家分享一篇python 处理数字,把大于上限的数字置零实现方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-01-01 本文主要介绍了Python中Generators教程的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02
本文主要介绍了Python中Generators教程的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2023-02-02 排列组合是数学中的基本概念,也是编程中常见的问题之一,本文主要介绍了Python蒙特卡洛算法实现排列组合,具有一定的参考价值,感兴趣的可以了解一下2024-03-03
排列组合是数学中的基本概念,也是编程中常见的问题之一,本文主要介绍了Python蒙特卡洛算法实现排列组合,具有一定的参考价值,感兴趣的可以了解一下2024-03-03 今天小编就为大家分享一篇OpenCV+python手势识别框架和实例讲解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-08-08
今天小编就为大家分享一篇OpenCV+python手势识别框架和实例讲解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-08-08 在本篇文章里小编给大家整理的是关于app后端开发学PHP还是Python的先关问题内容,需要的朋友们可以参考下。2020-06-06
在本篇文章里小编给大家整理的是关于app后端开发学PHP还是Python的先关问题内容,需要的朋友们可以参考下。2020-06-06










最新评论