
java编程进阶小白也能手写HashMap代码
什么是HashMap
这一节课,我们来手写一个简单的HashMap,所谓HashMap,就是一个映射表。
比如现在我有一个客户类,就用之前的就好。
现在我有100个客户,名字各不相同,有叫张三的,也有叫李四的,还有的人叫张全蛋。如果现在要你从这100个人中找到一个叫做王尼玛的人,你怎么办?
这好像很简单,我们不是刚刚做了一个TuziLinkedList吗?一个个add进去,数据初始化,然后再用foreach去遍历不就行了?可是,这样的效率是很低的,假如王尼玛正好在链表的最后一个,那就需要遍历100次才能找到。复杂度是o(n)
这个时候,要是有一种办法能让我们一下子就通过name,去找到王尼玛这个人就好了。
其实这个办法是有的,就是查表法,我们需要的就是这样的一个映射表。
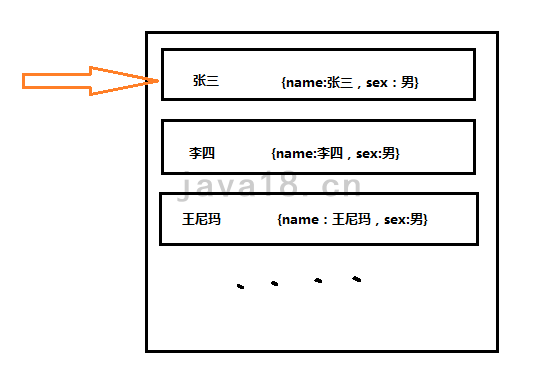
映射表分为key和value,在这个例子中,key就是name字段。这样一来,复杂度就是o(1),只需要遍历一次就可以了。
简单来说,不管有多少个数据,如果你用关系映射表Map,只需要一次,你就直接通过某一个key,拿到了对应的Customer对象。
为什么这么神奇呢?
那是因为,Map的底层是一个数组。
什么是数组?
数组的知识比较基础,网上已经被讲烂了,直接参考菜鸟教程即可:
https://www.runoob.com/java/java-array.html
因为数组是直接用数字下标去获取对应的值的,复杂度是最低的,所以Map的查询才会这么快。
我们要做的一种映射关系表,写法大概是这样的。
public class TestMap {
public static void main(String[] args) {
Map csts = new HashMap<>();
csts.put("王大锤",new Customer("王大锤"));
csts.put("王尼玛",new Customer("王尼玛"));
csts.put("赵铁柱",new Customer("赵铁柱"));
//直接根据name拿到对应的实体对象
Customer customer = (Customer) csts.get("王大锤");
System.out.println(customer.getName());
}
}
这是java自带的HashMap,我们就需要实现类似的功能。
HashCode和数组
先考虑第一个问题,既然HashMap底层是用数组,可是key不一定是数字,那么就得想办法把key转化为一个数字。
HashCode就是一种hash码值,任何一个字符串,对象都有自己的Hash码,计算方式如下:
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
使用 int 算法,这里 s[i] 是字符串的第 i 个字符,n 是字符串的长度,^ 表示求幂。空字符串的哈希值为 0。
比如字符串是“abc”, 套用公式计算如下:
String a = "abc"; // 97 * 31^(3-1) + 98 * 31^(3-2) + 99 ^ (3-3) //= 93217 + 3038 + 99 = 96354 System.out.println(a.hashCode());
答案正是:
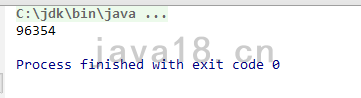
我们99%的情况,HashMap的key就是String,所以都可以用这个公式去计算。HashCode算法的牛逼之处在于,任何字符串都可以对应唯一的一个数字。
相信你肯定有一个疑惑,就是为啥Hash算法用的是31的幂等运算?
在名著 《Effective Java》第 42 页就有对 hashCode 为什么采用 31 做了说明:
之所以使用 31, 是因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)。使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。 31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能: 31 * i == (i << 5) - i, 现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。
反正大概意思就是一些数学家发现,用31计算hash值的话,性能是最好的。毕竟你也不希望算个HashCode花太多时间吧。
一开始,我们不需要做的太完美,刚开始的时候,完成永远优于完美。
public class TuziHashMap {
private Object arr[];
private int capacity = 20; //初始化容量
public TuziHashMap(){
arr = new Object[capacity];
}
}
TuziHashMap内部维护了一个数组,初识容量为20。接下来,实现put方法,put方法就是给这个Map添加新的元素。
public Object put(String key,Object value){
//1\. 算出HashCode
int hashCode = key.hashCode();
//2\. 直接取模,得到余数,这个余数就是数组的下标
int index = hashCode % capacity;
//3\. 将对应的数据放入数组的对应格子
this.arr[index] = value;
return value;
}
然后是get方法,接收对应的key值,返回对应的元素。
public Object get(String key){
//1\. 算出HashCode
int hashCode = key.hashCode();
//2\. 直接取模,得到余数,这个余数就是数组的下标
int index = hashCode % capacity;
//3\. 将对应的数据放入数组的对应格子
return this.arr[index];
}
代码非常相似,先别管优不优化,实现功能再说,这就是踏出的第一步。
TuziHashMap map = new TuziHashMap();
map.put("王大锤",new Customer("王大锤"));
System.out.println(map.get("王大锤"));
效果:

Hash碰撞
Hash碰撞也叫做Hash冲突,就是当两个key算出来HashCode相同的情况下,就会产生冲突。
目前我们的Map类中,底层的数组长度默认值20(真正的HashMap默认值是16),当存入的数据足够多并且不进行扩容的话,Hash碰撞是必然的。所谓Hash碰撞,就是比如说两个key明明是不同的,但是经过hash算法后,hash值竟然是相同的。那么另一个key的value就会覆盖之前的,从而引起错误。
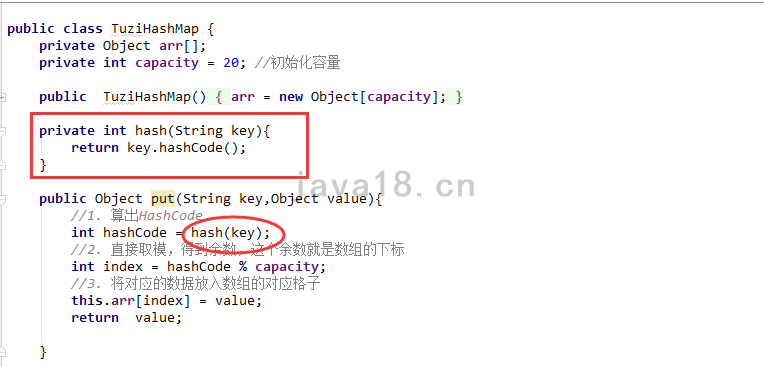
添加专门的hash方法,然后先写死hashcode为10,那就一定会发生hash碰撞!
private int hash(String key){
//return key.hashCode();
return 10;
}
get方法也要改过来,用hash方法:
public Object get(String key){
//1\. 算出HashCode
int hashCode = hash(key);
//2\. 直接取模,得到余数,这个余数就是数组的下标
int index = hashCode % capacity;
//3\. 将对应的数据放入数组的对应格子
return this.arr[index];
}
TuziHashMap map = new TuziHashMap();
map.put("王大锤",new Customer("王大锤"));
map.put("王尼玛",new Customer("王尼玛"));
System.out.println(map.get("王大锤"));
结果:
Customer{name=‘王尼玛', sex=‘null', birthDate=‘null', phoneNumber=‘null', status=0}
原因:产生了Hash碰撞,后面的王尼玛直接把王大锤给覆盖了。
怎么解决Hash碰撞呢?因为Hash碰撞在实际应用中肯定会出现,所以,我们就不能在数组的每一个格子中直接存Object对象,而应该弄一个链表。
假如出现Hash碰撞,就直接在链表中加一个节点。然后,下次取元素的时候,如果遇到Hash碰撞的情况就去循环那个链表,从而解决了Hash冲突的问题。
有了基本的思路,我们就得去修改put方法。
put方法接收一个key,一个value。如果发生Hash冲突,就得把新的key和value加到链表的末尾。
初步代码如下:
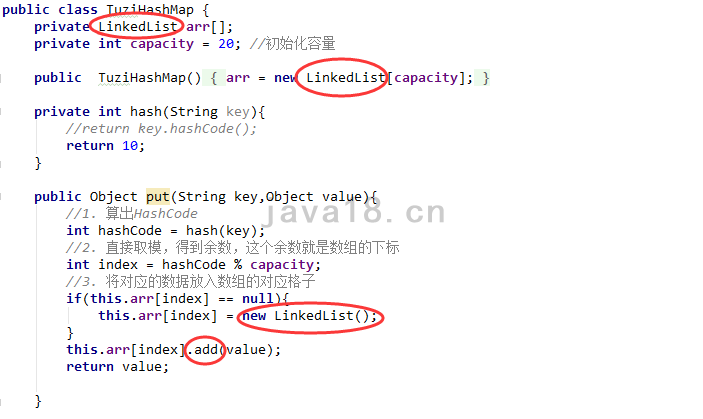
但是,这样有个问题,你没法取。为什么没法取呢?因为,链表上的每一个节点,我们只保存了value,没有key。那么相同的key的情况,怎么去获取对应的元素呢?比如两个key,分别是“王大锤”和“王尼玛”,假如他们的HashCode是相同的,因为链表上没有保存“王大锤”和“王尼玛”两个key,我们就没法区分了。
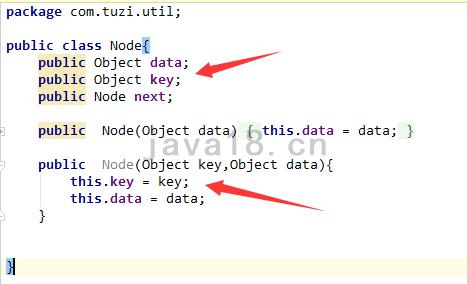
没有办法,只好修改一下之前的Node。为什么之前没有加key呢?因为之前的Node类是为LinkedList服务的,LinkedList不需要key这个东西。
在linkedList中,原来的add方法是不需要key的,所以也需要做一个修改:
/**
* 原来的add方法保留,调用重载的add方法
* @param object
* @return
*/
public boolean add(Object object){
return add(null,object);
}
/**
* 新增的add方法,增加参数key
*/
public boolean add(Object key,Object object){
//将数据用节点类包装好,这样才能实现下一个数据的指向
Node data = new Node(object);
if(key != null){
data.key = key;
}
//先判断是否是第一个节点
if(this.firstNode == null){
this.firstNode = data;
this.currentNode = data;
}else{
//不是第一个节点,就指向当前节点的下一个节点,即currentNode.next
this.currentNode.next = data;
//因为已经指向下一个了,所以当前节点也要移动过来
this.currentNode = data;
}
size++;
return true;
}
如果你读过jdk里面的源码,就一定会知道,在很多Java基础类中,都有一大堆的构造方法,一大堆方法重载。而且,很多方法里面都会调用同名的方法,只不过参数传的不一样罢了。
我之前也一直不理解,为什么要整的这么麻烦,后来当自己尝试写一些数据结构的时候,才明白,不这样搞真的不行。方法重载的意义不是去秀肌肉的,而是减少代码的工作量。
比如,因为LinkedList需要增加key的保存,原来的add方法是没有的。我们不太好直接修改原来的add方法,因为万一这个类被很多调用了,那么很多地方都会受到不同程度的影响。所以,类的设计思路有一条很重要,那就是:
做增量好过做修改。
还是原来的测试代码:
TuziHashMap map = new TuziHashMap();
map.put("王大锤",new Customer("王大锤"));
map.put("王尼玛",new Customer("王尼玛"));
System.out.println(map.get("王大锤"));
因为我们修改了hash方法,强行导致Hash碰撞,所以目前是肯定冲突的。
运行:
Customer{name=‘王大锤', sex=‘null', birthDate=‘null', phoneNumber=‘null', status=0}
成功了,王尼玛没有覆盖掉王大锤。
toString方法
为了更好的调试,我们给TuziHashMap添加toString方法
public String toString(){
StringBuffer sb = new StringBuffer("[\n");
for (int i = 0; i < arr.length; i++) {
LinkedList list = arr[i];
if(list != null){
while(list.hasNext()){
Node node = list.nextNode();
sb.append(String.format("\t{%s=%s}",node.key,node.data));
if(list.hasNext())
sb.append(",\n");
else
sb.append("\n");
}
}
}
sb.append("]");
return sb.toString();
}
运行之前的测试代码,就是这样的:

百万级数据压测
做一点性能测试,又有新的问题了。。。
步骤 1 来100w条数据,看看要花多久?
long startTime = System.currentTimeMillis(); //获取开始时间
TuziHashMap map = new TuziHashMap();
for (int i = 0; i < 100000; i++) {
map.put("key" + i, "value--" + i);
}
System.out.println(map);
long overTime = System.currentTimeMillis(); //获取结束时间
System.out.println("程序运行时间为:"+(overTime-startTime)+"毫秒");
上面的代码就是循环10w次,然后用一个toString全部打印出来,看看需要多久吧?
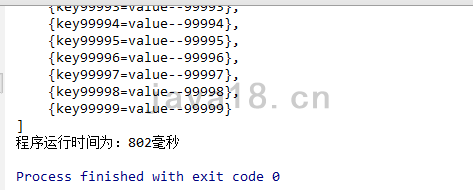
大概是800毫秒左右。
可如果是100w呢?
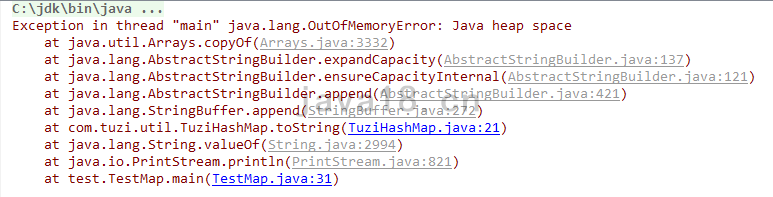
直接报错了,原因是JVM内存溢出。这是为什么呢?
那是因为,我们的Map初识容量是20,100w条数据插进去,想也知道链表是扛不住了。
步骤 2 设计思路
1.初始化数组
2.每次put的时候,就计算是不是快溢出来了,如果是,数组翻倍。
3.由于数组容量翻倍了,原来的数据需要重新计算hash值,散列到新的数组中去。(不这样做的话,数组利用率会不够,很多数据全部挤在前半段)
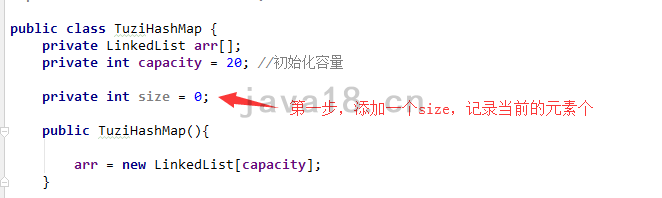
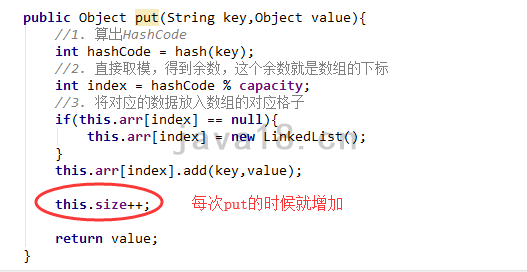
步骤 3 添加一个size
现在的数组长度是20,最理想的情况,添加20个元素,一次Hash碰撞都没有,均匀分布在20个格子里面。当添加第21个的时候,一定会发生Hash碰撞,这个时候我们就需要去扩容数组了。
步骤 4 先设计,后实现
因为代码写到这里,已经开始慢慢变得复杂了。我们可以参考之前接口的章节,先设计,再谈如何实现。只要设计是合理了,就别担心能不能实现的问题。如果你一开始就陷入到各种细节里面,那你就很难更进一步。
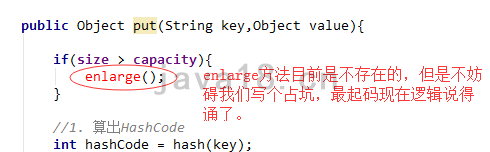
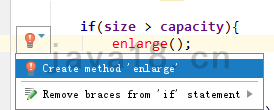
利用DIEA的自动提示功能,生成扩容方法。
步骤 5 扩容方法
private void enlarge() {
capacity *= 2; // 等同于 capacity = capacity * 2 ,这么写只是因为我想装个逼。
LinkedList[] newArr = new LinkedList[capacity];
System.out.println("数组扩容到" + capacity);
int len = arr.length; //把arr的长度写在外面,这样能减少一丢丢的计算
for (int i = 0; i < len; i++) {
LinkedList linkedList = arr[i];
if(arr[i] != null){
while(linkedList.hasNext()){
Node node = linkedList.nextNode();
Object key = node.key;
Object value = node.data;
//将原有的数据一个个塞到新的数组
reHash(newArr,key,value);
}
}
}
//新数组正式上位
this.arr = newArr;
}
每个数组元素都是一个链表,这个链表里面每一个数据都应该要遍历到,需要再写一个reHash方法,重新计算Hash值。
步骤 6 reHash方法
private void reHash(LinkedList[] newArr, Object key, Object value) {
//1\. 算出HashCode
int hashCode = hash(key.toString());
//2\. 直接取模,得到余数,这个余数就是数组的下标
int index = hashCode % capacity ;
//3\. 将对应的数据放入数组的对应格子
if(newArr[index] == null){
newArr[index] = new LinkedList();
}
newArr[index].add(key,value);
}
和put方法差不多,只是多了一个参数,如果是JDK的套路,肯定又得做函数重载了吧。不过现在赶进度,就不做优化了。
步骤 7 新的问题出现
做个测试,我们来个26条数据,肯定会触发扩容的。
long startTime = System.currentTimeMillis(); //获取开始时间
TuziHashMap map = new TuziHashMap();
for (int i = 0; i < 260; i++) {
map.put("key" + i, "value--" + i);
}
System.out.println(map);
long overTime = System.currentTimeMillis(); //获取结束时间
System.out.println("程序运行时间为:"+(overTime-startTime)+"毫秒");
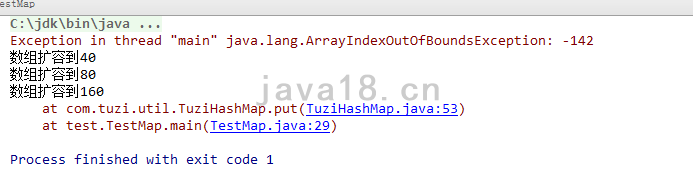
天啊,竟然报错了!
从错误信息看,index是-142,也就是说hashCode是负数。
hashCode怎么会是负数呢?
答案是:hashCode肯定有可能是负数。因为HashCode是int类型
int型的值取值范围为
Integer.MIN_VALUE(-2147483648)~Integer.MAX_VALUE(2147483647)
那怎么修改呢?可以想到取绝对值,其实还有一个更酷的方法,就是用与逻辑。
为了防止漏改,我们把取模的运算抽出来做成方法。
老规矩,先把方法写出来,做设计。待会再去写实现。
步骤 8 indexForTable方法
private int indexForTable(int hashCode) {
return hashCode & Integer.MAX_VALUE % capacity;
}
这样的做法就是确保不会出现负数,效率还高。如果你问为什么,那就是计算机里面存的int,其实是有符号的。如果是负数,第一位也就是符号位就是1,而Integer.MAX_VALUE是正数。

0x是表示16进制的前缀。
第一个7是16进制的7,换算成2进制,就是好多个1,如果算出来的hashCode是负数,那么第一个就是1,和0进行&操作,就会变成0,于是就变成正数了。
假如我们的hashCode是10,换算成二进制就是1010。你可以用1248法快速口算。
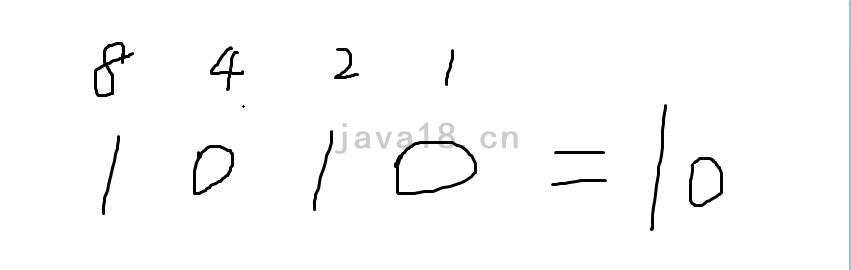
那么,进行&运算:
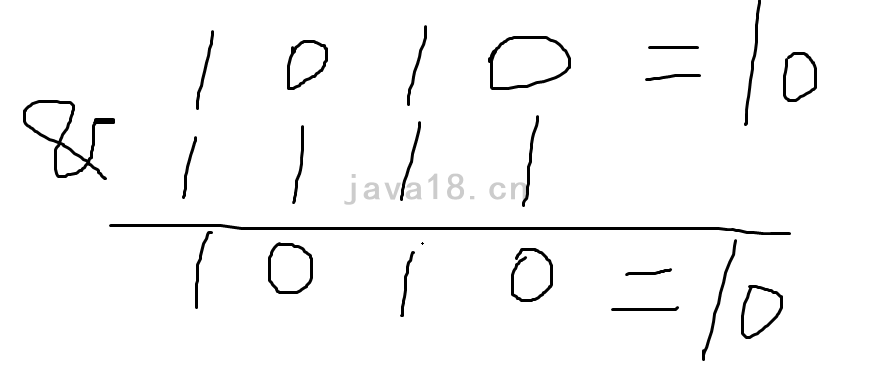
可见,这个操作其实就是取绝对值,但是效率更高。
步骤 9 重新转测
所有用到取模运算的地方,都改成indexForTable方法,代码我就不贴了。
重新测试,就发现不报错了。
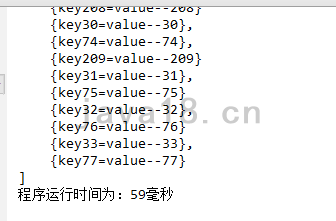
步骤 10 再次测试100w数据
其实站长刚才测试的时候又报内存溢出了,想着估计是System.out.print语句太多了。(可能之前也是这个原因,哈哈)
于是,我修改了一下测试代码:
long startTime = System.currentTimeMillis(); //获取开始时间
TuziHashMap map = new TuziHashMap();
for (int i = 0; i < 100 * 10000; i++) {
map.put("key" + i, "value--" + i);
}
System.out.println(map.get("key" + 99999));
long overTime = System.currentTimeMillis(); //获取结束时间
System.out.println("程序运行时间为:"+(overTime-startTime)+"毫秒");
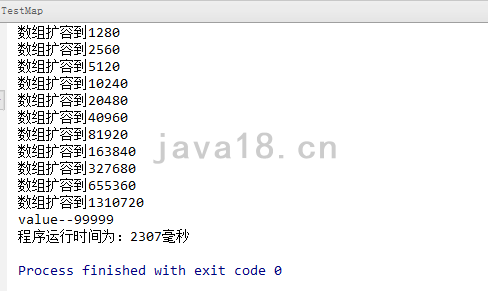
只花了2秒多,这可是100w条数据啊,可见HashMap的性能还是很客观的。
步骤 11 PK 原生JDK8的HashMap
long startTime = System.currentTimeMillis(); //获取开始时间
HashMap map = new HashMap();
for (int i = 0; i < 100 * 10000; i++) {
map.put("key" + i, "value--" + i);
}
System.out.println(map.get("key" + 99999));
long overTime = System.currentTimeMillis(); //获取结束时间
System.out.println("程序运行时间为:"+(overTime-startTime)+"毫秒");
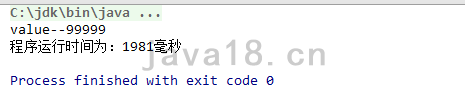
100w数据的情况下,时间测下来是差不多的。不过即便如此,我们也不要太较真,因为jdk8的HashMap肯定写的比我们的好,完善。就比如我们在数组的每个节点放的是链表,而jdk8开始,则是链表+红黑树的结构,当Hash冲突很多的情况下,会自动转换为红黑树,效率会更加高一点。
补丁
目前的HashMap还只是实现了最最基本的功能,好多方法都还未实现,比如remove方法。
步骤 1 put元素的bug
其实put方法是有一个bug的,不知道你发现了没有?
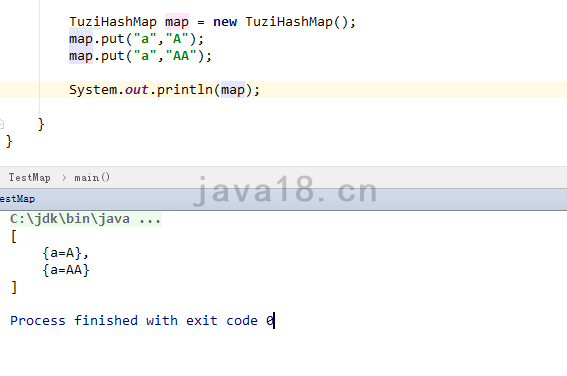
原生的HashMap,当put相同key的时候,是直接覆盖的,而目前的情况是直接追加到链表了。这就会导致我们执行
map.get("a")
得到的就是A,而不是AA,AA是永远拿不到了。
这个作为课后作业,欢迎进群一起学习交流哦。
步骤 2 HashMap为什么是无序的?
Java面试题中经常会遇到这个问题,HashMap为什么是无序的?
现在我们自己写了一个HashMap,相信你肯定知道原因了吧?key在进行hash算法的时候,谁知道会匹配到哪一个数组下标呢?所以,肯定是无序的。
步骤 3 作业1答案
public Object put(String key,Object value){
if(size > capacity){
enlarge();
}
//1\. 算出HashCode
int hashCode = hash(key);
//2\. 直接取模,得到余数,这个余数就是数组的下标
int index = indexForTable(hashCode);
//3\. 将对应的数据放入数组的对应格子
if(this.arr[index] == null){
this.arr[index] = new LinkedList();
}
LinkedList linkedList = this.arr[index];
if(linkedList.size() == 0){
linkedList.add(key,value);
}
//遍历这个node的链表,如果发现重复key,直接覆盖
Node firstNode = linkedList.firstNode;
Node node = firstNode;
while(node != null){
if(node.key.equals(key)){
node.data = value;
}
node = node.next;
}
this.size++;
return value;
}
以上就是java编程进阶小白也能手写HashMap的详细内容,更多关于手写HashMap的资料请关注脚本之家其它相关文章!
相关文章

Spring Boot 实现Restful webservice服务端示例代码
这篇文章主要介绍了Spring Boot 实现Restful webservice服务端示例代码,非常不错,具有参考借鉴价值,需要的朋友可以参考下2017-11-11 这篇文章主要介绍了Java Optional实践(小结),小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-09-09
这篇文章主要介绍了Java Optional实践(小结),小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧2018-09-09 本文主要介绍了java的IO流中的缓冲流的使用,缓冲流分为字节和字符缓冲流。分享了有关它们的实例代码,具有一定的参考价值,下面跟着小编一起来看下吧2017-01-01
本文主要介绍了java的IO流中的缓冲流的使用,缓冲流分为字节和字符缓冲流。分享了有关它们的实例代码,具有一定的参考价值,下面跟着小编一起来看下吧2017-01-01 使用IDEA开始就一直在搭建java环境,许久没有使用过java,刚开始有些生疏,先建了一个最简单的类可是运行的时候出现错误:找不到或无法加载主类,下面这篇文章主要给大家介绍了关于IDEA错误:找不到或无法加载主类的完美解决方法,需要的朋友可以参考下2022-07-07
使用IDEA开始就一直在搭建java环境,许久没有使用过java,刚开始有些生疏,先建了一个最简单的类可是运行的时候出现错误:找不到或无法加载主类,下面这篇文章主要给大家介绍了关于IDEA错误:找不到或无法加载主类的完美解决方法,需要的朋友可以参考下2022-07-07 这篇文章主要介绍了Java中try catch的使用和如何抛出异常问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-12-12
这篇文章主要介绍了Java中try catch的使用和如何抛出异常问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2023-12-12
tio-boot jfinal-plugins框架整合redis示例详解
这篇文章主要为大家介绍了tio-boot jfinal-plugins框架整合redis示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-12-12 这篇文章主要给大家介绍了关于Java面试基础之TCP连接以及其优化的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用Java具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-09-09
这篇文章主要给大家介绍了关于Java面试基础之TCP连接以及其优化的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用Java具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-09-09 这篇文章主要介绍了SpringBoot消息国际化配置实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07
这篇文章主要介绍了SpringBoot消息国际化配置实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-07-07
聊聊maven的pom.xml中的exclusions标签的作用
这篇文章主要介绍了maven的pom.xml中的exclusions标签的作用,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2021-12-12
spring-boot通过@Scheduled配置定时任务及定时任务@Scheduled注解的方法
这篇文章主要介绍了spring-boot通过@Scheduled配置定时任务,文中还给大家介绍了springboot 定时任务@Scheduled注解的方法,需要的朋友可以参考下2017-11-11










最新评论