
实操Python爬取觅知网素材图片示例
【一、项目背景】
在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片。
【二、项目目标】
1、根据给定的网址获取网页源代码。
2、利用正则表达式把源代码中的图片地址过滤出来。
3、过滤出来的图片地址下载素材图片。
【三、涉及的库和网站】
1、网址如下:
2、涉及的库:requests、lxml
【四、项目分析】
首先需要解决如何对下一页的网址进行请求的问题。可以点击下一页的按钮,观察到网站的变化分别如下所示:
https://www.51miz.com/so-sucai/1789243.html https://www.51miz.com/so-sucai/1789243/p_2/ https://www.51miz.com/so-sucai/1789243/p_3/
我们可以发现图片页数是1789243/p{},p{}花括号数字表示图片哪一页。
【五、项目实施】
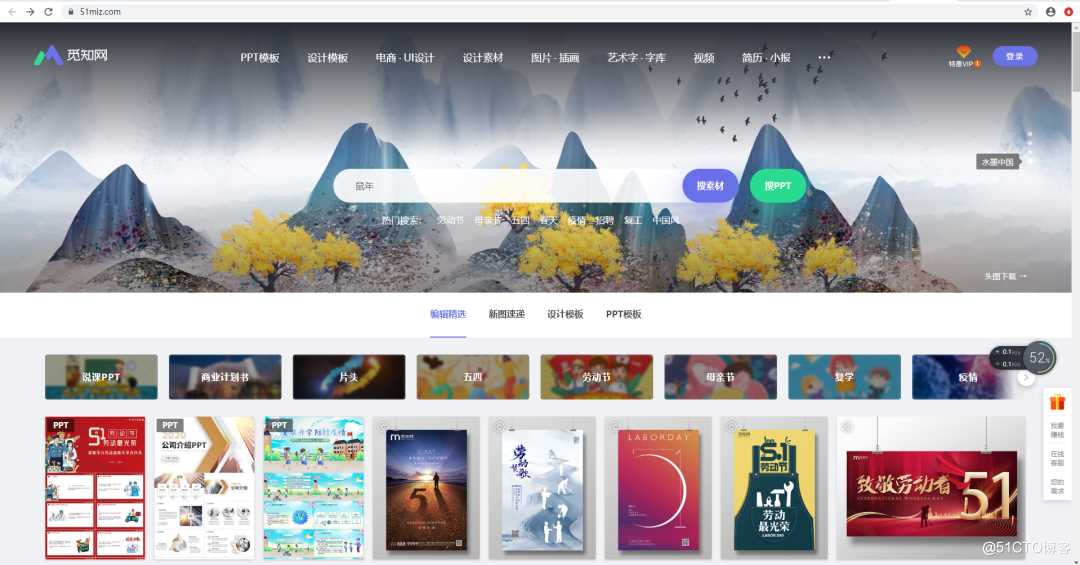
1、打开觅知网,在搜索中输入你想要的图片素材(以鼠年素材图片为例)。
2、根据上一步对网址的分析,首先我们定义一个类叫做ImageSpider,类里面定义初始化函数、发送请求获取响应数据函数、解析函数、主函数。首先初始化函数,准备url地址和headers,代码如下图所示。

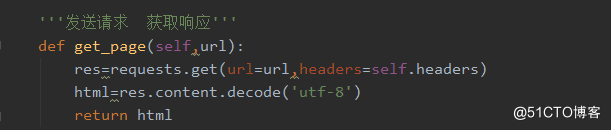
3、发送请求获取响应数据函数。
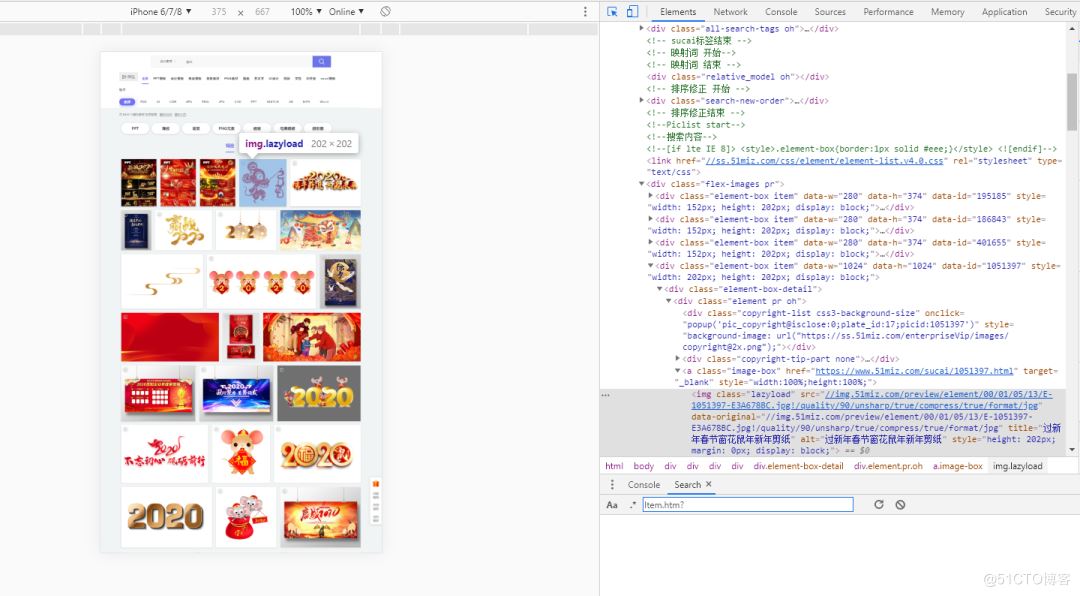
4、解析数据,使用xpath获取二级页面链接,最后把图片存储在文件夹中。使用谷歌浏览器选择开发者工具或直接按F12,发现我们需要的图片src是在img标签下的,于是用Python的requests提取该组件。

5、主函数,代码如下图所示。

【六、效果展示】
1、运行程序,在控制台输入你要爬取的页数,如下图所示。

2、在本地可以看到效果图,如下图所示。

【七、总结】
1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
2、希望通过这个项目,能够帮助大家下载到素材图片。
3、本文基于Python网络爬虫,利用爬虫库,实现素材图片的获取。实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。
到此这篇关于实操Python爬取觅知网素材图片示例的文章就介绍到这了,更多相关Python爬取觅知网素材图片内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

Python列表常见操作详解(获取,增加,删除,修改,排序等)
这篇文章主要介绍了Python列表常见操作,结合实例形式总结分析了Python列表常见的获取、增加、删除、修改、排序、计算等相关操作技巧,需要的朋友可以参考下2019-02-02 这篇文章主要为大家介绍了人工智能学习Pytorch张量数据类型的示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步2021-11-11
这篇文章主要为大家介绍了人工智能学习Pytorch张量数据类型的示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步2021-11-11
Python中的JSON Pickle Shelve模块特性与区别实例探究
在Python中,处理数据序列化和持久化是极其重要的,JSON、Pickle和Shelve是三种常用的模块,它们提供了不同的方法来处理数据的序列化和持久化,本文将深入研究这三个模块,探讨它们的特性、用法以及各自的优缺点2024-01-01 自动微分技术(称为“automatic differentiation, autodiff”)是介于符号微分和数值微分的一种技术,它是在计算效率和计算精度之间的一种折衷。本文主要介绍了Python如何实现前向和反向自动微分,需要的可以参考一下2022-12-12
自动微分技术(称为“automatic differentiation, autodiff”)是介于符号微分和数值微分的一种技术,它是在计算效率和计算精度之间的一种折衷。本文主要介绍了Python如何实现前向和反向自动微分,需要的可以参考一下2022-12-12 本文主要介绍了matplotlib绘制雷达图的基本配置(万能模板案例),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-04-04
本文主要介绍了matplotlib绘制雷达图的基本配置(万能模板案例),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2022-04-04 这篇文章主要为大家详细介绍如何了在Python中创建一条水平线以及Python 中的 Matplotlib 库的使用,文中的示例代码讲解详细,感兴趣的小伙伴可以了解下2023-10-10
这篇文章主要为大家详细介绍如何了在Python中创建一条水平线以及Python 中的 Matplotlib 库的使用,文中的示例代码讲解详细,感兴趣的小伙伴可以了解下2023-10-10 这篇文章主要给大家介绍了关于如何使用Python从字符串中提取数字的相关资料,我们在进行数据处理时候,可能想要提取字符串中的数字进行分析,需要的朋友可以参考下2023-11-11
这篇文章主要给大家介绍了关于如何使用Python从字符串中提取数字的相关资料,我们在进行数据处理时候,可能想要提取字符串中的数字进行分析,需要的朋友可以参考下2023-11-11
Tensorflow 1.0之后模型文件、权重数值的读取方式
今天小编就为大家分享一篇Tensorflow 1.0之后模型文件、权重数值的读取方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-02-02 这篇文章主要给大家介绍了关于Python中几种属性访问的区别和用法的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2018-10-10
这篇文章主要给大家介绍了关于Python中几种属性访问的区别和用法的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2018-10-10
Python函数参数匹配模型通用规则keyword-only参数详解
Python3对函数参数的排序规则更加通用化了,即Python3 keyword-only参数,该参数即为必须只按照关键字传递而不会有一个位置参数来填充的参数。这篇文章主要介绍了Python函数参数匹配模型通用规则keyword-only参数,需要的朋友可以参考下2019-06-06










最新评论