
c++调用实现yolov5转onnx介绍
介绍
现在很多开发都是需要用c++做最后一步的移植部署,手写吧,先不说你会不会浪费时间,网上找吧,问题千奇百怪,所以给大家出这篇文章,做雷锋教学,话不多说,开始
训练模型.pt转onnx
训练部分根据呼声再决定要不要写一份博客吧!!
注意事项:
1.训练代码一定要选择yolov5 5.0版本
2. 进入models/exprort.py;
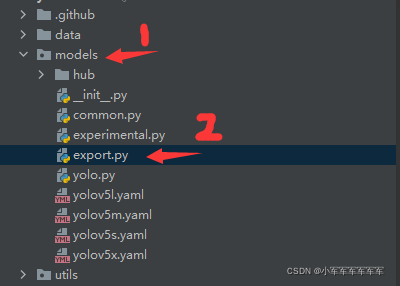
3.将红框区域换成你自己的训练完的模型

4.将版本换成12;

5.直接运行即可,会生成出onnx的模型出来。
c++代码解析
博主使用的是opencv4.5.3版本,已经编译好的,需要直接扫码加我发你
main函数部分
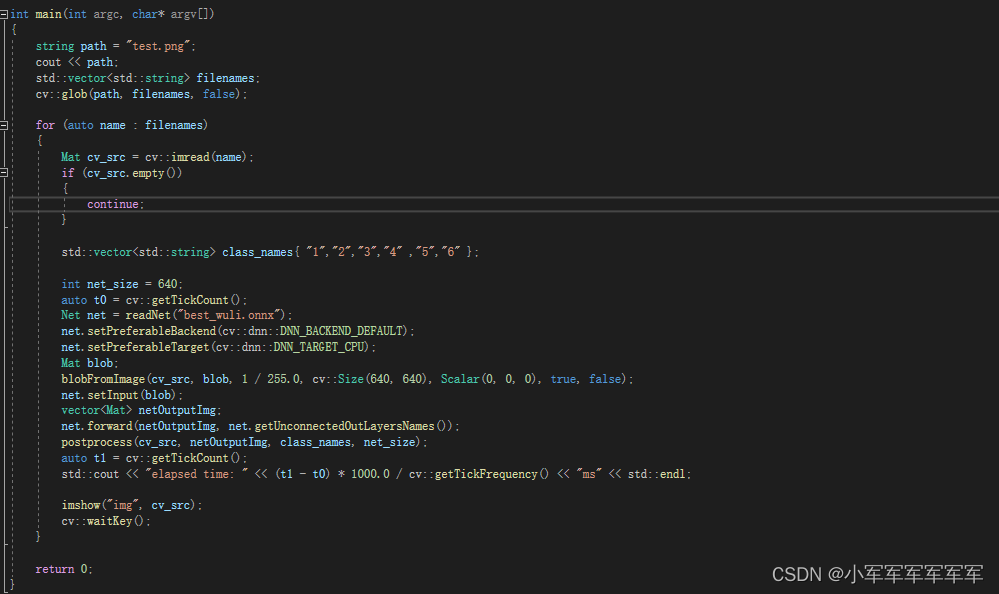
读取模型利用的是dnn::readNet,opencv其实挺强大的博主已经读过tf模型,torch模型后续都会出对应博客,这里总共有三点改,输入图片path,输入类别名class_names,net部分改成自己的模型
net.set这些参数都固定就好,有兴趣的同学可以研究研究DNN_TARGET_CPU这个地方,是可以使用gpu和cuda的,但是博主还没复现过
推理部分讲解
void postprocess(cv::Mat& cv_src, std::vector<cv::Mat>& outs, const std::vector<std::string>& classes, int net_size)
{
float confThreshold = 0.1f;
float nmsThreshold = 0.1f;
std::vector<int> classIds;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
int strides[] = { 8, 16, 32 };
std::vector<std::vector<int> > anchors =
{
{ 10,13, 16,30, 33,23 },
{ 30,61, 62,45, 59,119 },
{ 116,90, 156,198, 373,326 }
};
for (size_t k = 0; k < outs.size(); k++)
{
float* data = outs[k].ptr<float>();
int stride = strides[k];
int num_classes = outs[k].size[4] - 5;
for (int i = 0; i < outs[k].size[2]; i++)
{
for (int j = 0; j < outs[k].size[3]; j++)
{
for (int a = 0; a < outs[k].size[1]; ++a)
{
float* record = data + a * outs[k].size[2] * outs[k].size[3] * outs[k].size[4] +
i * outs[k].size[3] * outs[k].size[4] + j * outs[k].size[4];
float* cls_ptr = record + 5;
for (int cls = 0; cls < num_classes; cls++)
{
float score = sigmoid(cls_ptr[cls]) * sigmoid(record[4]);
if (score > confThreshold)
{
float cx = (sigmoid(record[0]) * 2.f - 0.5f + (float)j) * (float)stride;
float cy = (sigmoid(record[1]) * 2.f - 0.5f + (float)i) * (float)stride;
float w = pow(sigmoid(record[2]) * 2.f, 2) * anchors[k][2 * a];
float h = pow(sigmoid(record[3]) * 2.f, 2) * anchors[k][2 * a + 1];
float x1 = std::max(0, std::min(cv_src.cols, int((cx - w / 2.f) * (float)cv_src.cols / (float)net_size)));
float y1 = std::max(0, std::min(cv_src.rows, int((cy - h / 2.f) * (float)cv_src.rows / (float)net_size)));
float x2 = std::max(0, std::min(cv_src.cols, int((cx + w / 2.f) * (float)cv_src.cols / (float)net_size)));
float y2 = std::max(0, std::min(cv_src.rows, int((cy + h / 2.f) * (float)cv_src.rows / (float)net_size)));
classIds.push_back(cls);
confidences.push_back(score);
boxes.push_back(cv::Rect(cv::Point(x1, y1), cv::Point(x2, y2)));
}
}
}
}
}
}
std::vector<int> indices;
cv::dnn::NMSBoxes(boxes, confidences, confThreshold, nmsThreshold, indices);
for (size_t i = 0; i < indices.size(); i++)
{
int idx = indices[i];
cv::Rect box = boxes[idx];
drawPred(classIds[idx], confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, cv_src, classes);
}
}
抬头部分是两大目标检测的阈值设置,然后anchors这些都不建议动,除非你在训练的时候用了你自己生成的anchors的话,就改成你自己的,然后根据训练推理后,会生成我们所对应的坐标框以及分数,将分数和狂送到容器中,dnn中有nms等底层函数哦
cv::dnn::NMSBoxes(boxes, confidences, confThreshold, nmsThreshold, indices);
对应输入就可以了,然后得到我们的Box,index,和置信度,接下来就到了我们的画图环节。
darpred部分
void drawPred(int classId, float conf, int left, int top, int right, int bottom, cv::Mat& frame,
const std::vector<std::string>& classes)
{
cv::rectangle(frame, cv::Point(left, top), cv::Point(right, bottom), cv::Scalar(0, 255, 0), 3);
std::string label = cv::format("%.2f", conf);
if (!classes.empty()) {
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ": " + label;
}
int baseLine;
cv::Size labelSize = cv::getTextSize(label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = std::max(top, labelSize.height);
cv::rectangle(frame, cv::Point(left, top - round(1.5 * labelSize.height)), cv::Point(left + round(1.5 * labelSize.width), top + baseLine), cv::Scalar(0, 255, 0), cv::FILLED);
cv::putText(frame, label, cv::Point(left, top), cv::FONT_HERSHEY_SIMPLEX, 0.75, cv::Scalar(), 2);
}
sigmod部分
inline float sigmoid(float x)
{
return 1.f / (1.f + exp(-x));
}
结尾
到此这篇关于c++调用实现yolov5转onnx介绍的文章就介绍到这了,更多相关c++ yolov5转onnx内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章介绍了C++通过boost.date_time进行时间运算的方法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-06-06
这篇文章介绍了C++通过boost.date_time进行时间运算的方法,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-06-06 这篇文章主要给大家介绍了C/C++中提高数组中查找某个元素或者字符串中查找某个字符效率的小技巧,提高速度对我们日常开发来说还是很有用的,文中给出了详细的示例代码,需要的朋友可以参考借鉴,下面来一起看看吧。2017-01-01
这篇文章主要给大家介绍了C/C++中提高数组中查找某个元素或者字符串中查找某个字符效率的小技巧,提高速度对我们日常开发来说还是很有用的,文中给出了详细的示例代码,需要的朋友可以参考借鉴,下面来一起看看吧。2017-01-01 命名空间域就是一个独立的空间外面不能直接调用该空间域只能用访问限定符指定访问该空间域,本文主要介绍了C++命名空间域的实现示例,具有一定的参考价值,感兴趣的可以了解一下2024-01-01
命名空间域就是一个独立的空间外面不能直接调用该空间域只能用访问限定符指定访问该空间域,本文主要介绍了C++命名空间域的实现示例,具有一定的参考价值,感兴趣的可以了解一下2024-01-01 本文主要介绍了C语言宏定义#define的使用,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-01-01
本文主要介绍了C语言宏定义#define的使用,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2022-01-01 这篇文章主要介绍了C++中缀表达式转后缀表达式的方法,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-04-04
这篇文章主要介绍了C++中缀表达式转后缀表达式的方法,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-04-04 这篇文章主要为大家详细介绍了C++扑克牌的洗牌发牌游戏设计,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-08-08
这篇文章主要为大家详细介绍了C++扑克牌的洗牌发牌游戏设计,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-08-08 这篇文章主要为大家详细介绍了C++判断主机是否处于联网状态,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06
这篇文章主要为大家详细介绍了C++判断主机是否处于联网状态,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-06-06 这篇文章主要介绍了C++11标准库互斥锁 <mutex> 的相关知识,使用call_once()的时候,需要一个once_flag作为call_once()的传入参数,本文给大家介绍的非常详细,感兴趣的朋友一起看看吧2024-07-07
这篇文章主要介绍了C++11标准库互斥锁 <mutex> 的相关知识,使用call_once()的时候,需要一个once_flag作为call_once()的传入参数,本文给大家介绍的非常详细,感兴趣的朋友一起看看吧2024-07-07 std::count函数是一个非常实用的算法,它可以帮助我们快速统计给定值在指定范围内的出现次数,本文主要介绍了C++中std::count函数介绍和使用场景,感兴趣的可以了解一下2024-02-02
std::count函数是一个非常实用的算法,它可以帮助我们快速统计给定值在指定范围内的出现次数,本文主要介绍了C++中std::count函数介绍和使用场景,感兴趣的可以了解一下2024-02-02 这篇文章主要介绍了OpenSSL动态链接库的使用,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-11-11
这篇文章主要介绍了OpenSSL动态链接库的使用,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-11-11










最新评论