
Python Requests爬虫之求取关键词页面详解
更新时间:2022年02月16日 10:10:18 作者:那人独钓寒江雪.
这篇文章主要为大家详细介绍了Python Requests爬虫之求取关键词页面,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助
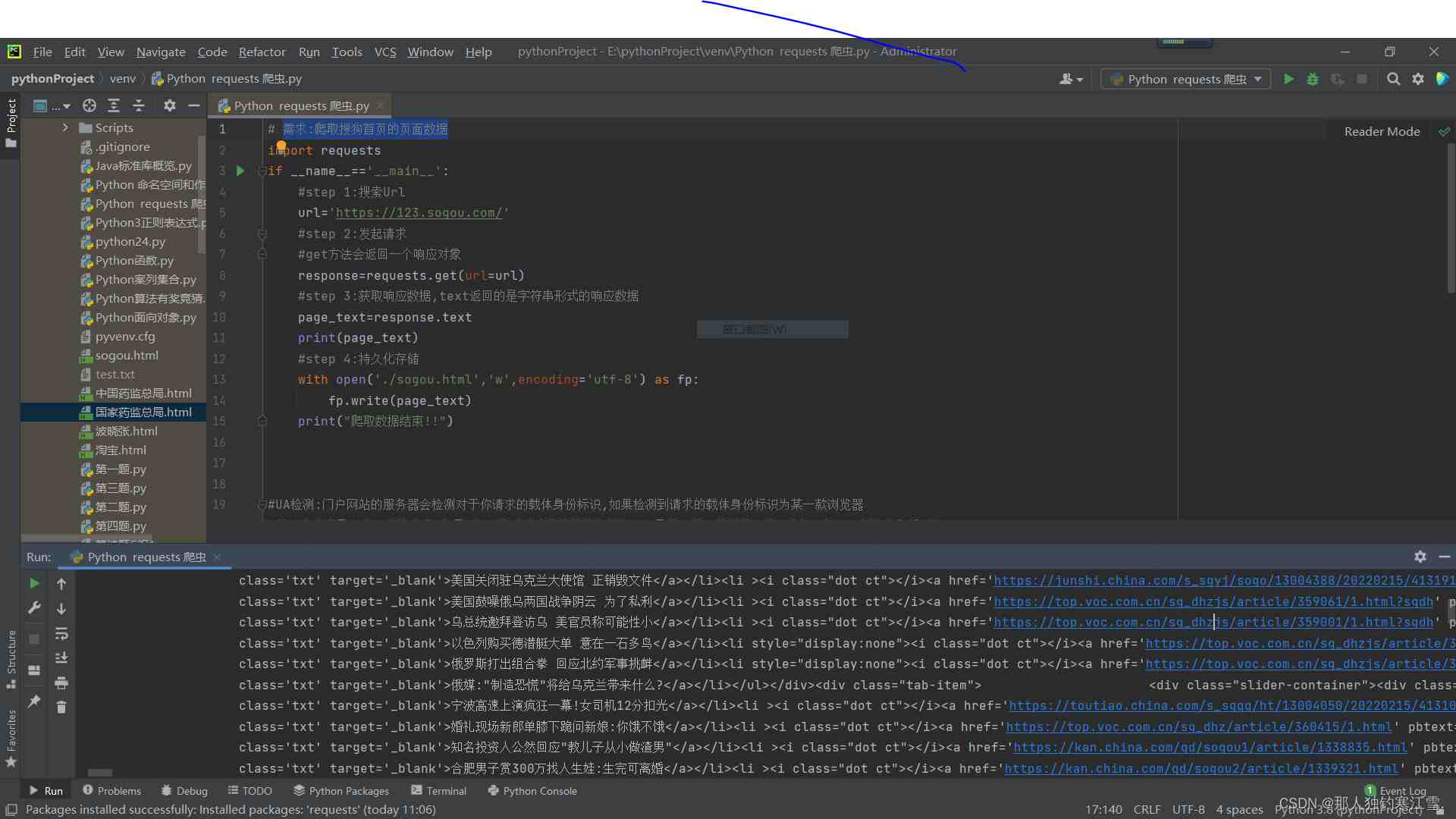
需求:爬取搜狗首页的页面数据
import requestsif __name__=='__main__': #step 1:搜索Url url='https://123.sogou.com/' #step 2:发起请求 #get方法会返回一个响应对象 response=requests.get(url=url) #step 3:获取响应数据,text返回的是字符串形式的响应数据 page_text=response.text print(page_text) #step 4:持久化存储 with open('./sogou.html','w',encoding='utf-8') as fp: fp.write(page_text) print("爬取数据结束")import requests
if __name__=='__main__':
#step 1:搜索Url
url='https://123.sogou.com/'
#step 2:发起请求
#get方法会返回一个响应对象
response=requests.get(url=url)
#step 3:获取响应数据,text返回的是字符串形式的响应数据
page_text=response.text
print(page_text)
#step 4:持久化存储
with open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print("爬取数据结束")
使用UA伪装 求取关键词页面
import requests
if __name__=='__main__':
#UA伪装:将对应的User-Agent封装到一个字典中
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.9 Safari/537.36'
}
url='https://www.sogou.com/sie?'
#处理url携带的参数:封装到字典中
kw=input('enter a word:')
param={
'query':kw
}
#对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response=requests.get(url=url,params=param,headers=headers)#headers是伪装 params输入关键词
page_text=response.text#以文本的形式输出
fileName=kw+'.html'#存储为网页形式
with open(fileName,'w+',encoding='utf-8') as fp:
fp.write(page_text)#写入fp
print(fileName,"保存成功!!")

总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注脚本之家的更多内容!
相关文章

pycharm中下载的包但是import还是无法使用/报红的解决方法
用pycharm开发时,在导入自己写的python文件时出现模块名爆红的情况,下面这篇文章主要给大家介绍了关于pycharm中下载包但是import还是无法使用/报红的解决方法,需要的朋友可以参考下2023-02-02 在本篇文章里小编给大家整理的是一篇关于python unichr函数的知识点总结内容,有兴趣的朋友们可以学习下。2020-12-12
在本篇文章里小编给大家整理的是一篇关于python unichr函数的知识点总结内容,有兴趣的朋友们可以学习下。2020-12-12
深入浅析pycharm中 Make available to all projects的含义
这篇文章主要介绍了pycharm中 Make available to all projects的含义,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2020-09-09 这篇文章主要介绍了Pandas如何获取数据的尺寸信息问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-02-02
这篇文章主要介绍了Pandas如何获取数据的尺寸信息问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-02-02 大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题2016-01-01
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题2016-01-01 这篇文章主要为大家详细介绍了如何通过Python中的progress库实现进度条的绘制,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-03-03
这篇文章主要为大家详细介绍了如何通过Python中的progress库实现进度条的绘制,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下2023-03-03 这篇文章主要介绍了Django使用Profile扩展User模块方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05
这篇文章主要介绍了Django使用Profile扩展User模块方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2020-05-05
Python解决IndexError: list index out of&nb
IndexError是一种常见的异常类型,它通常发生在尝试访问列表(list)中不存在的索引时,错误信息“IndexError: list index out of range”意味着你试图访问的列表索引超出了列表的实际范围,所以本文给大家介绍了Python成功解决IndexError: list index out of range2024-05-05 MongoDB是一个非常流行的NoSQL数据库,常用于大规模数据存储应用,下面这篇文章主要给大家介绍了关于NoSql数据库及使用Python连接MongoDB的相关资料,需要的朋友可以参考下2023-06-06
MongoDB是一个非常流行的NoSQL数据库,常用于大规模数据存储应用,下面这篇文章主要给大家介绍了关于NoSql数据库及使用Python连接MongoDB的相关资料,需要的朋友可以参考下2023-06-06 这篇文章主要为大家介绍了CodeWhisperer基于python使用经验分享,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-11-11
这篇文章主要为大家介绍了CodeWhisperer基于python使用经验分享,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-11-11










最新评论