
使用SQL实现车流量的计算的示例代码
更新时间:2022年02月28日 11:55:02 作者:每日小新
本文主要介绍了使用SQL实现车流量的计算的示例代码,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
卡口转换率
将数据导入hive,通过SparkSql编写sql,实现不同业务的数据计算实现,主要讲述车辆卡口转换率,卡口转化率:主要计算不同卡口下车辆之间的流向,求出之间的转换率。
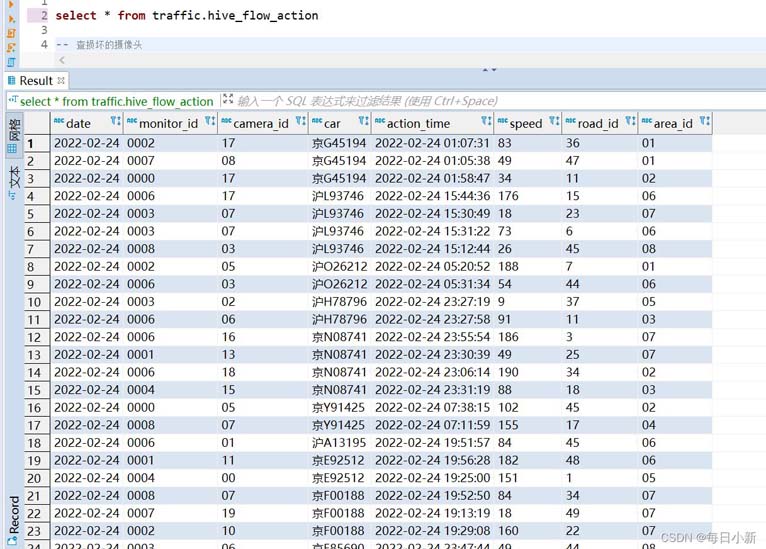
1、查出每个地区下每个路段下的车流量
select car, monitor_id, action_time, ROW_NUMBER () OVER (PARTITION by car ORDER by action_time) as n1 FROM traffic.hive_flow_action
此结果做为表1,方便后面错位连接使用
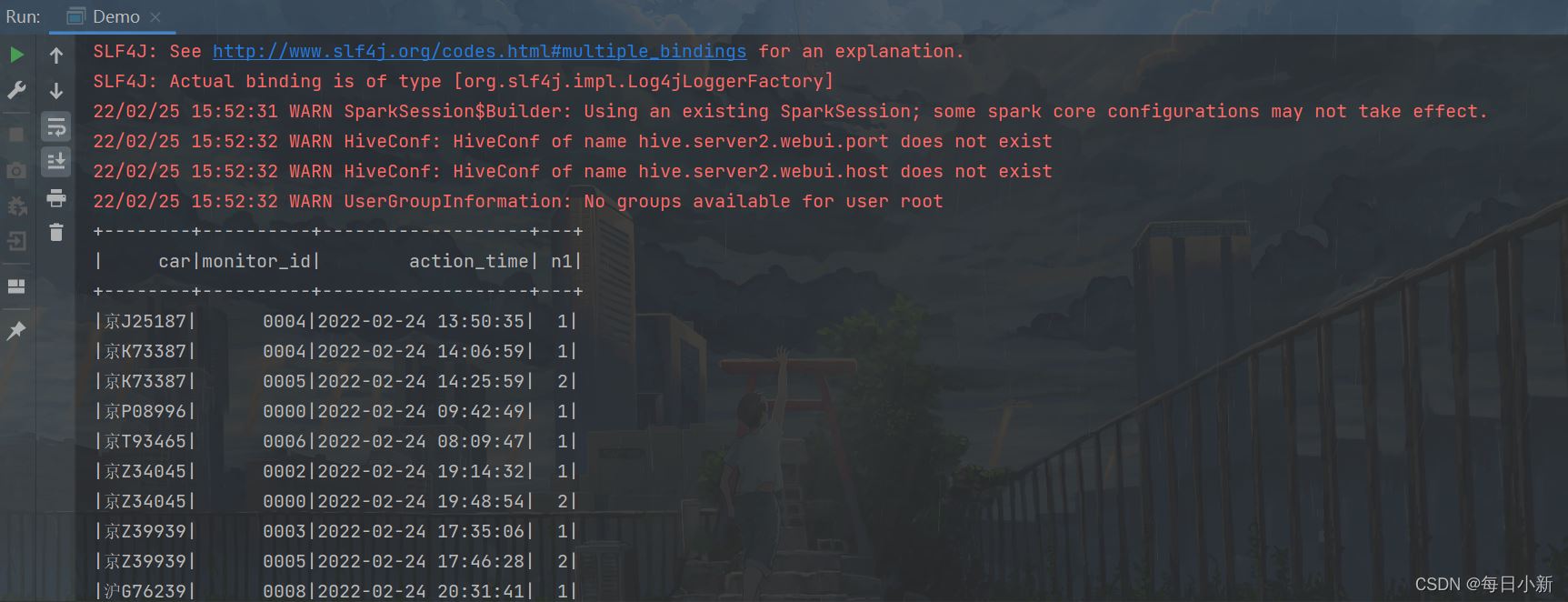
2、通过错位连接获取每辆车的行车记录
通过表1的结果,与自身进行错位链接,并以车牌为分区,拼接经过卡口的过程
(select t1.car, t1.monitor_id, concat(t1.monitor_id, "->", t2.monitor_id) as way from ( select car, monitor_id, action_time, ROW_NUMBER () OVER (PARTITION by car ORDER by action_time) as n1 FROM traffic.hive_flow_action) t1 left join ( select car, monitor_id, action_time, ROW_NUMBER () OVER (PARTITION by car ORDER by action_time) as n1 FROM traffic.hive_flow_action) t2 on t1.car = t2.car and t1.n1 = t2.n1-1 where t2.action_time is not null)
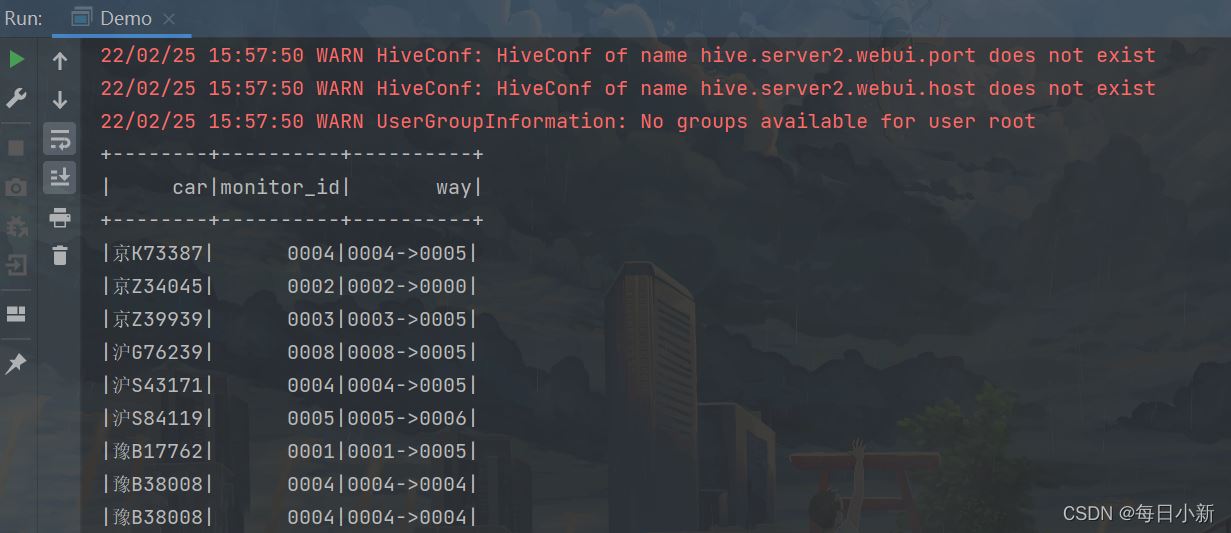
获取到每辆车的一个行车记录,经过的卡口
3、获取行车过程中的车辆数
获取卡口1~卡口2,…等的车辆数有哪些,即拿上面的行车记录字段进行分区在进行统计
(select s1.way, COUNT(1) sumCar from --行车过程 (select t1.car, t1.monitor_id, concat(t1.monitor_id, "->", t2.monitor_id) as way from ( select car, monitor_id, action_time, ROW_NUMBER () OVER (PARTITION by car ORDER by action_time) as n1 FROM traffic.hive_flow_action) t1 left join ( select car, monitor_id, action_time, ROW_NUMBER () OVER (PARTITION by car ORDER by action_time) as n1 FROM traffic.hive_flow_action) t2 on t1.car = t2.car and t1.n1 = t2.n1-1 where t2.action_time is not null)s1 group by way)
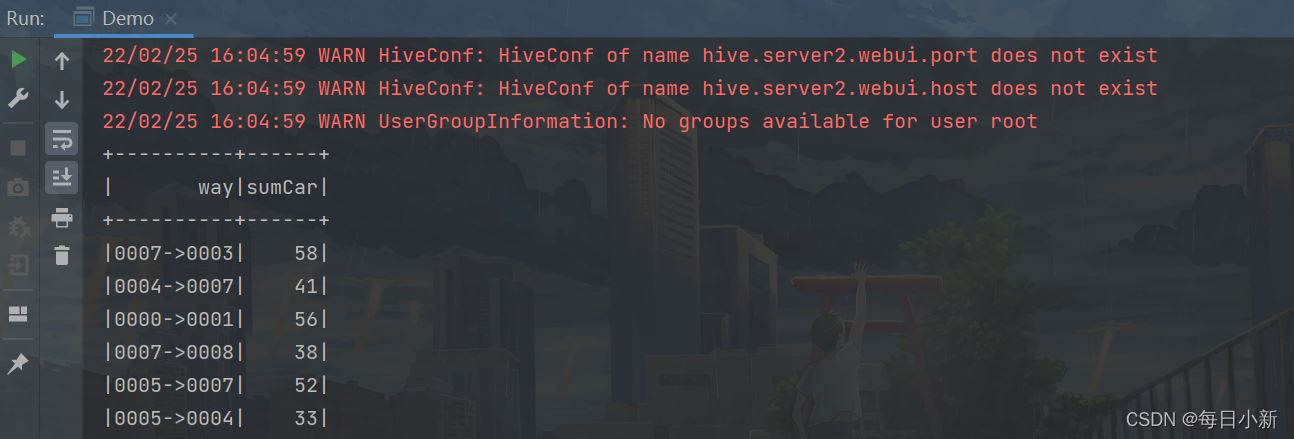
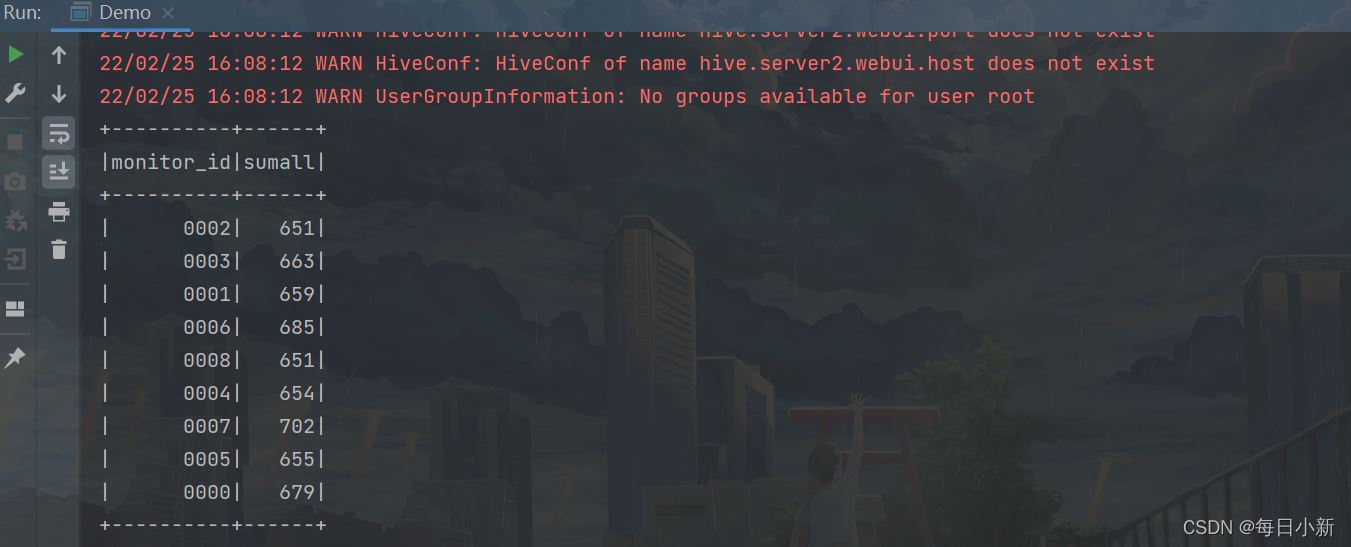
4、获取每个卡口的总车辆数
获取每个卡口最初的车辆数,方便后面拿行车轨迹车辆数/总车辆数,得出卡口之间的转换率
select monitor_id , COUNT(1) sumall from traffic.hive_flow_action group by monitor_id
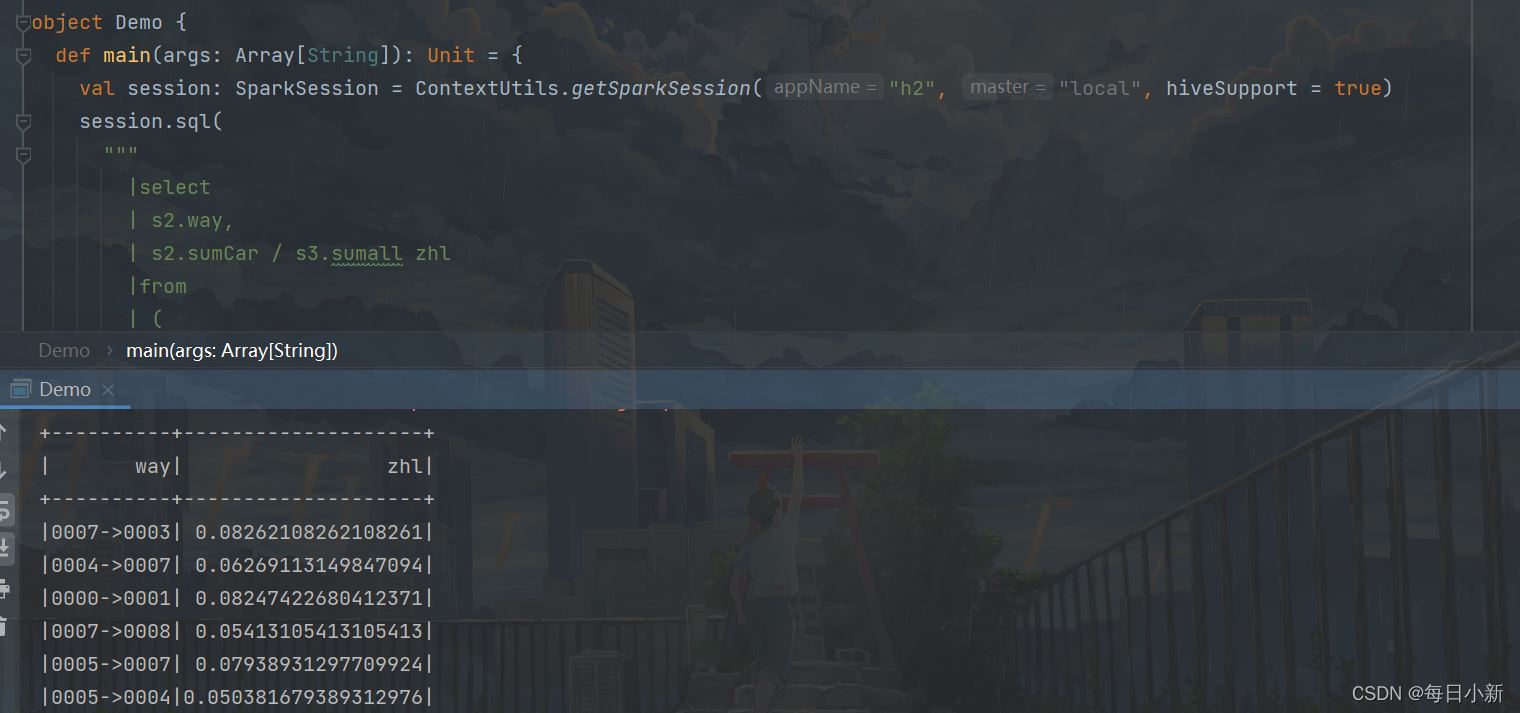
5、求出卡口之间的转换率
select s2.way, s2.sumCar / s3.sumall zhl from ( select s1.way, COUNT(1) sumCar from --行车过程 ( select t1.car, t1.monitor_id, concat(t1.monitor_id, "->", t2.monitor_id) as way from ( select car, monitor_id, action_time, ROW_NUMBER () OVER (PARTITION by car ORDER by action_time) as n1 FROM traffic.hive_flow_action) t1 left join ( select car, monitor_id, action_time, ROW_NUMBER () OVER (PARTITION by car ORDER by action_time) as n1 FROM traffic.hive_flow_action) t2 on t1.car = t2.car and t1.n1 = t2.n1-1 where t2.action_time is not null)s1 group by way)s2 left join --每个卡口总车数 ( select monitor_id , COUNT(1) sumall from traffic.hive_flow_action group by monitor_id) s3 on split(s2.way, "->")[0]= s3.monitor_id
到此这篇关于使用SQL实现车流量的计算的示例代码的文章就介绍到这了,更多相关SQL 车流量内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了MSSQL中进行SQL除法运算结果为小数却显示0的解决方法,需要的朋友可以参考下2015-10-10
这篇文章主要介绍了MSSQL中进行SQL除法运算结果为小数却显示0的解决方法,需要的朋友可以参考下2015-10-10
sqlserver中将varchar类型转换为int型再进行排序的方法
sql中把varchar类型转换为int型然后进行排序,如果我们数据库的ID设置为varchar型的 在查询的时候order by id的话2012-06-06 这篇文章主要介绍了SQL Server中的SQL语句优化与效率问题的相关资料,需要的朋友可以参考下2014-07-07
这篇文章主要介绍了SQL Server中的SQL语句优化与效率问题的相关资料,需要的朋友可以参考下2014-07-07
强制SQL Server执行计划使用并行提升在复杂查询语句下的性能
最近在给一个客户做调优的时候发现一个很有意思的现象,对于一个复杂查询(涉及12个表)建立必要的索引后,语句使用的IO急剧下降,但执行时间不降反升,由原来的8秒升到20秒。2014-07-07 SQL统计大全收藏,主要是一些实现统计功能常用的代码,希望对需要的朋友有所帮助.2010-05-05
SQL统计大全收藏,主要是一些实现统计功能常用的代码,希望对需要的朋友有所帮助.2010-05-05
远程连接局域网内的sql server 无法连接 错误与解决方法
下面我们依次介绍如何来解决这三个最常见的连接错误。2009-09-09 SQLServer XML数据的五种基本操作语句2009-07-07
SQLServer XML数据的五种基本操作语句2009-07-07 这篇文章主要介绍了SQLServer查询某个时间段购买过商品的所有用户,需要的朋友可以参考下2017-07-07
这篇文章主要介绍了SQLServer查询某个时间段购买过商品的所有用户,需要的朋友可以参考下2017-07-07 SQL语句以前在学校的时候都学过,时间久了就有点记不清了。2009-04-04
SQL语句以前在学校的时候都学过,时间久了就有点记不清了。2009-04-04 这篇文章主要介绍了sql server实现图片的存入和读取的详细流程,文中通过代码示例和图文结合的方式给大家讲解的非常详细,对大家的学习或工作有一定的帮助,需要的朋友可以参考下2024-05-05
这篇文章主要介绍了sql server实现图片的存入和读取的详细流程,文中通过代码示例和图文结合的方式给大家讲解的非常详细,对大家的学习或工作有一定的帮助,需要的朋友可以参考下2024-05-05










最新评论