
Map映射LinkedHashSet与LinkedHashMap应用解析
总体介绍
如果你已看过前面关于HashSet和HashMap,以及TreeSet和TreeMap的讲解,一定能够想到本文将要讲解的LinkedHashSet和LinkedHashMap其实也是一回事。LinkedHashSet和LinkedHashMap在Java里也有着相同的实现,前者仅仅是对后者做了一层包装,也就是说LinkedHashSet里面有一个LinkedHashMap(适配器模式)。因此本文将重点分析LinkedHashMap。
LinkedHashMap实现了Map接口,即允许放入key为null的元素,也允许插入value为null的元素。从名字上可以看出该容器是linked list和HashMap的混合体,也就是说它同时满足HashMap和linked list的某些特性。可将LinkedHashMap看作采用linked list增强的HashMap。
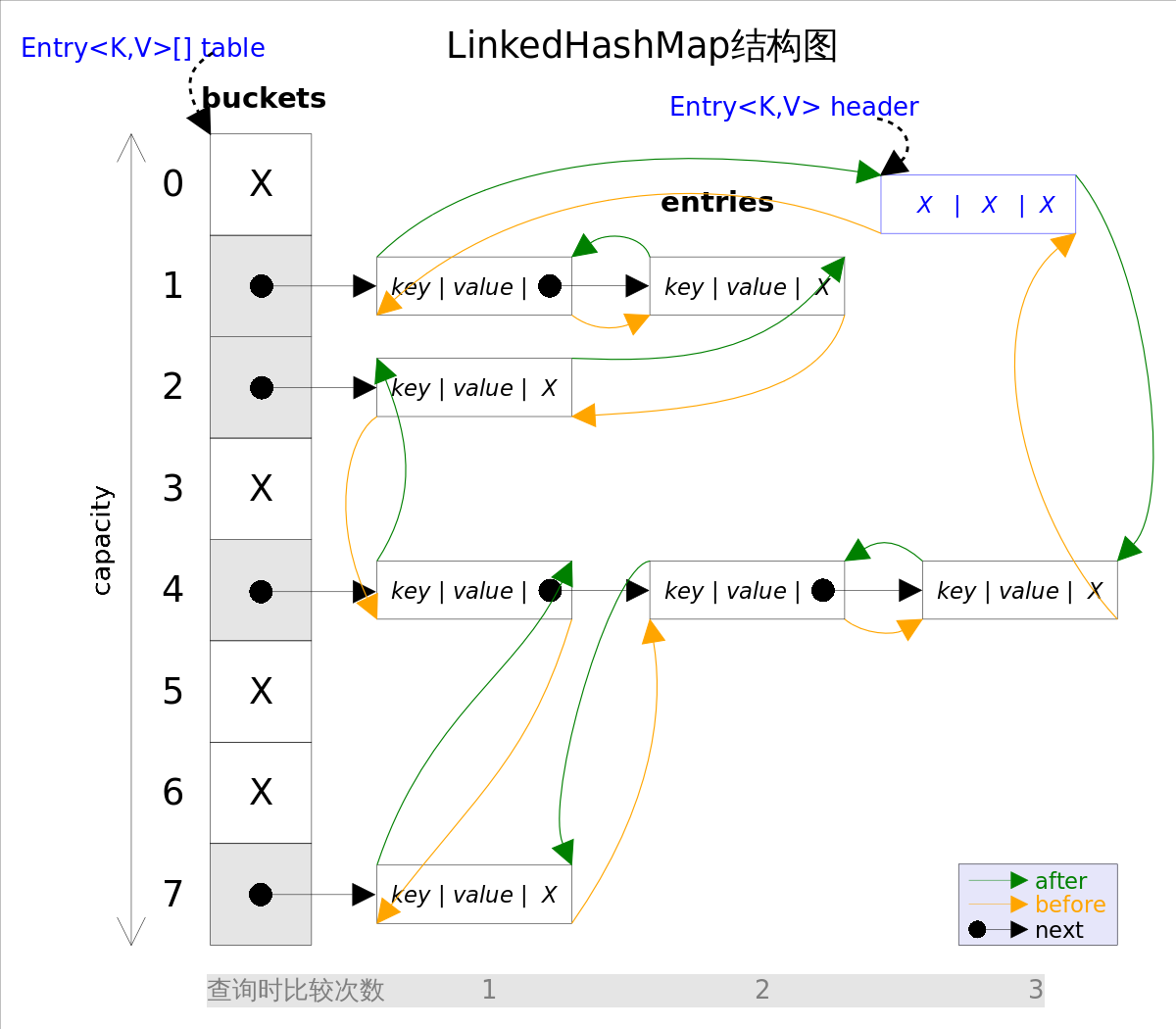
事实上LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同。上图给出了LinkedHashMap的结构图,主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。
除了可以保迭代历顺序,这种结构还有一个好处 : 迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。
有两个参数可以影响LinkedHashMap的性能: 初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
将对象放入到LinkedHashMap或LinkedHashSet中时,有两个方法需要特别关心: hashCode()和equals()。hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到LinkedHashMap或LinkedHashSet中,需要@Override hashCode()和equals()方法。
通过如下方式可以得到一个跟源Map 迭代顺序一样的LinkedHashMap:
void foo(Map m) {
Map copy = new LinkedHashMap(m);
...
}出于性能原因,LinkedHashMap是非同步的(not synchronized),如果需要在多线程环境使用,需要程序员手动同步;或者通过如下方式将LinkedHashMap包装成(wrapped)同步的:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
LinkedHashMap
get()
get(Object key)方法根据指定的key值返回对应的value。该方法跟HashMap.get()方法的流程几乎完全一样
put()
put(K key, V value)方法是将指定的key, value对添加到map里。
该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于get()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry。
注意,这里的插入有两重含义:
从table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。
从header的角度看,新的entry需要插入到双向链表的尾部。
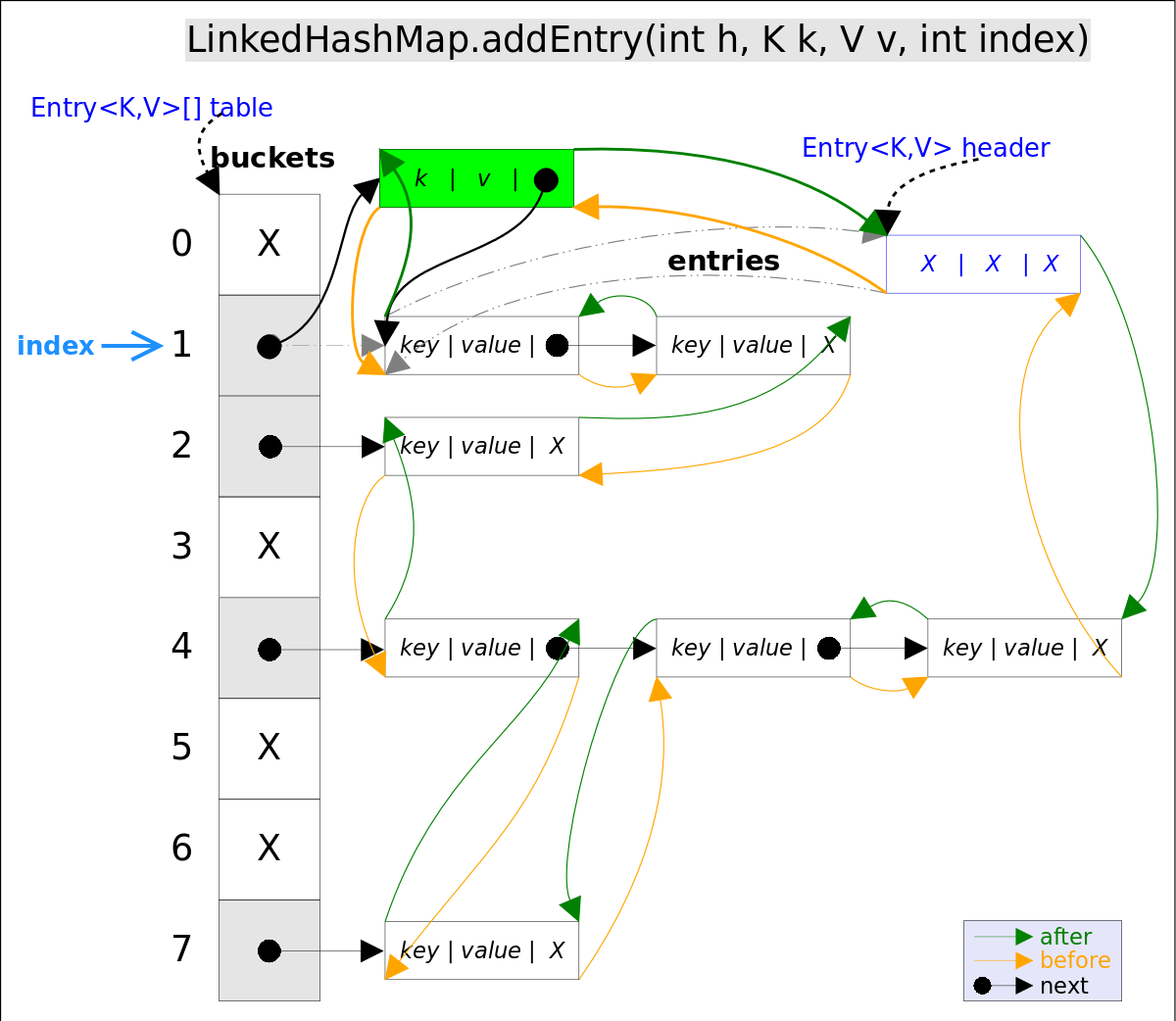
addEntry()源码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的源码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}上述代码只是简单修改相关entry的引用而已。
remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。
removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意,这里的删除也有两重含义:
从table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。
从header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。
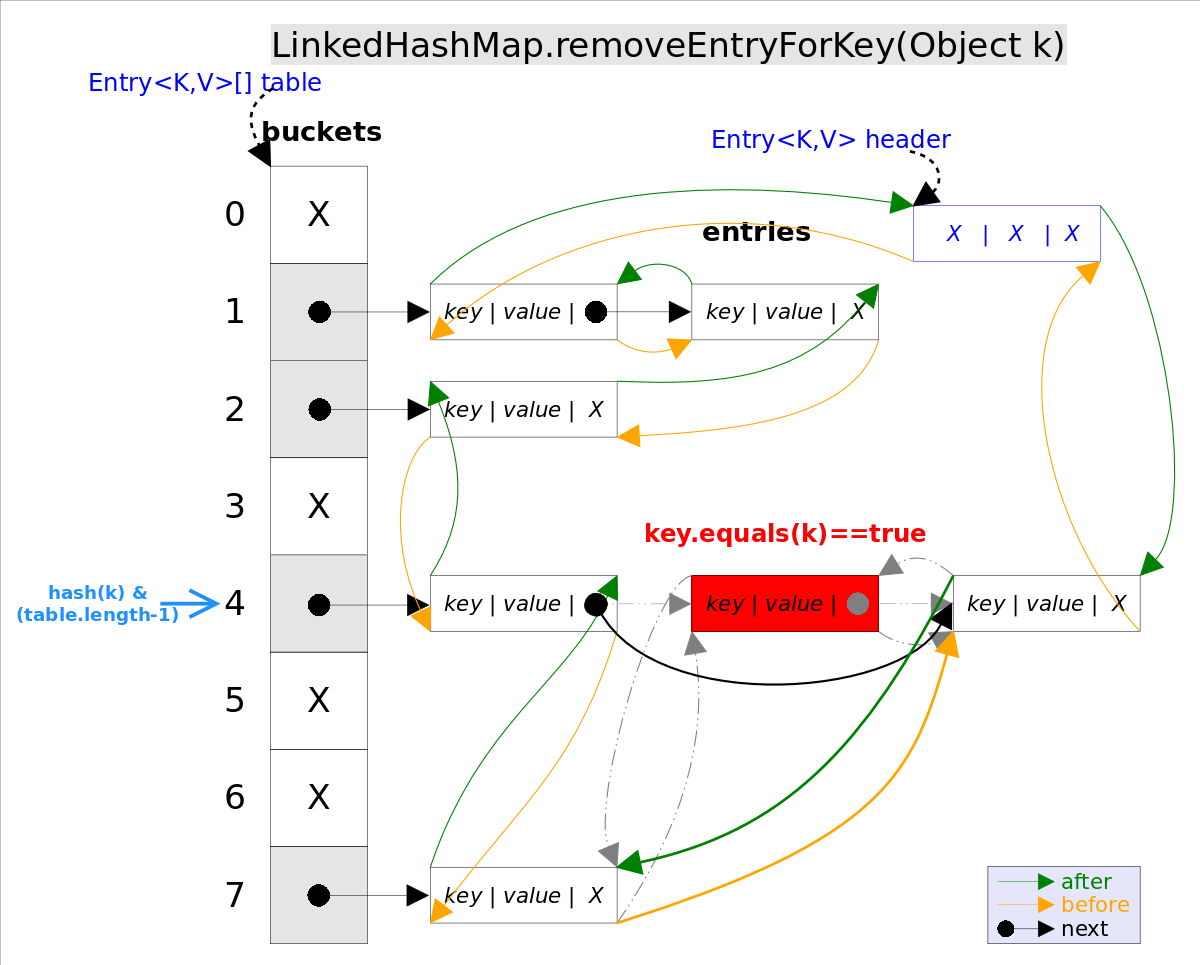
removeEntryForKey()对应的源码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}LinkedHashSet
前面已经说过LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单,这里不再赘述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
......
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
......
public boolean add(E e) {
//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}LinkedHashMap经典用法
LinkedHashMap除了可以保证迭代顺序外c;还有一个非常有用的用法: 可以轻松实现一个采用了FIFO替换策略的缓存。具体说来,LinkedHashMap有一个子类方法
protected boolean removeEldestEntry(Map.Entry<K,V> eldest)
该方法的作用是告诉Map是否要删除“最老”的Entry,所谓最老就是当前Map中最早插入的Entry,如果该方法返回true,最老的那个元素就会被删除。在每次插入新元素的之后LinkedHashMap会自动询问removeEldestEntry()是否要删除最老的元素。这样只需要在子类中重载该方法,当元素个数超过一定数量时让removeEldestEntry()返回true,就能够实现一个固定大小的FIFO策略的缓存。示例代码如下:
/** 一个固定大小的FIFO替换策略的缓存 */
class FIFOCache<K, V> extends LinkedHashMap<K, V>{
private final int cacheSize;
public FIFOCache(int cacheSize){
this.cacheSize = cacheSize;
}
// 当Entry个数超过cacheSize时,删除最老的Entry
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > cacheSize;
}
}以上就是Map映射LinkedHashSet与LinkedHashMap示例解析的详细内容,更多关于Map映射LinkedHashSet与LinkedHashMap的资料请关注脚本之家其它相关文章!
相关文章
 下面小编就为大家带来一篇基于mybatis高级映射多对多查询的实现。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10
下面小编就为大家带来一篇基于mybatis高级映射多对多查询的实现。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10 这篇文章主要介绍了Java 获取本机IP地址,本文通过实例代码给大家介绍的非常详细,需要的朋友可以参考下2022-05-05
这篇文章主要介绍了Java 获取本机IP地址,本文通过实例代码给大家介绍的非常详细,需要的朋友可以参考下2022-05-05 这篇文章主要介绍了Idea中SpringBoot多模块项目的建立实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-06-06
这篇文章主要介绍了Idea中SpringBoot多模块项目的建立实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-06-06 本文主要介绍了Java前后端分离项目跨域问题解决方案,其中后端基于SpringBoot,前端使用了jQuery、axios等框架,具有一定的参考价值,感兴趣的可以了解一下2024-03-03
本文主要介绍了Java前后端分离项目跨域问题解决方案,其中后端基于SpringBoot,前端使用了jQuery、axios等框架,具有一定的参考价值,感兴趣的可以了解一下2024-03-03 下面小编就为大家带来一篇java集合类源码分析之Set详解。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10
下面小编就为大家带来一篇java集合类源码分析之Set详解。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-10-10
SpringBoot security安全认证登录的实现方法
这篇文章主要介绍了SpringBoot security安全认证登录的实现方法,也就是使用默认用户和密码登录的操作方法,本文结合实例代码给大家介绍的非常详细,需要的朋友可以参考下2023-02-02 这篇文章主要介绍了SpringCloud中的Ribbon负载均衡器详细解析,Ribbon 是一个基于 HTTP 和 TCP 的客户端负载均衡工具,它基于 Netflix Ribbon 实现,通过封装可以让我们轻松地将面向服务的 REST 模版请求自动转换成客户端负载均衡的服务调用,需要的朋友可以参考下2024-01-01
这篇文章主要介绍了SpringCloud中的Ribbon负载均衡器详细解析,Ribbon 是一个基于 HTTP 和 TCP 的客户端负载均衡工具,它基于 Netflix Ribbon 实现,通过封装可以让我们轻松地将面向服务的 REST 模版请求自动转换成客户端负载均衡的服务调用,需要的朋友可以参考下2024-01-01
SpringBoot的@GetMapping路径匹配规则、国际化详细教程
这篇文章主要介绍了SpringBoot的@GetMapping路径匹配规则、国际化,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友参考下吧2023-11-11 这篇文章主要介绍了spring web.xml指定配置文件过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02
这篇文章主要介绍了spring web.xml指定配置文件过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-02-02 这篇文章主要介绍了Java8中使用一行代码读取文件,要注意,本文介绍的方法不适合读取很大的文件,因为可能存在内存空间不足的问题,需要的朋友可以参考下2015-03-03
这篇文章主要介绍了Java8中使用一行代码读取文件,要注意,本文介绍的方法不适合读取很大的文件,因为可能存在内存空间不足的问题,需要的朋友可以参考下2015-03-03










最新评论