
java常用Lambda表达式使用场景源码示例
引导语
我们日常工作中,Lambda 使用比较多的场景,就是 List 或 Map 下的 Lambda 流操作,往往几行代码可以帮助我们实现多层 for 循环嵌套的复杂代码,接下来我们把 Lambda 流的常用方法用案列讲解一下。
1、数据准备
本文演示的所有代码都在 demo.eight.LambdaExpressionDemo 中,首先我们需要准备一些测试的数据,如下:
@Data
// 学生数据结构
class StudentDTO implements Serializable {
private static final long serialVersionUID = -7716352032236707189L;
public StudentDTO() {
}
public StudentDTO(Long id, String code, String name, String sex, Double scope,
List<Course> learningCources) {
this.id = id;
this.code = code;
this.name = name;
this.sex = sex;
this.scope = scope;
this.learningCources = learningCources;
}
/**
* id
*/
private Long id;
/**
* 学号 唯一标识
*/
private String code;
/**
* 学生名字
*/
private String name;
/**
* 性别
*/
private String sex;
/**
* 分数
*/
private Double scope;
/**
* 要学习的课程
*/
private List<Course> learningCources;
}
@Data
// 课程数据结构
class Course implements Serializable {
private static final long serialVersionUID = 2896201730223729591L;
/**
* 课程 ID
*/
private Long id;
/**
* 课程 name
*/
private String name;
public Course(Long id, String name) {
this.id = id;
this.name = name;
}
}
// 初始化数据
private final List<StudentDTO> students = new ArrayList<StudentDTO>(){
{
// 添加学生数据
add(new StudentDTO(1L,"W199","小美","WM",100D,new ArrayList<Course>(){
{
// 添加学生学习的课程
add(new Course(300L,"语文"));
add(new Course(301L,"数学"));
add(new Course(302L,"英语"));
}
}));
add(new StudentDTO(2L,"W25","小美","WM",100D,Lists.newArrayList()));
add(new StudentDTO(3L,"W3","小名","M",90D,new ArrayList<Course>(){
{
add(new Course(300L,"语文"));
add(new Course(304L,"体育"));
}
}));
add(new StudentDTO(4L,"W1","小蓝","M",10D,new ArrayList<Course>(){
{
add(new Course(301L,"数学"));
add(new Course(305L,"美术"));
}
}));
}
};请大家稍微看下数据结构,不然看下面案例跑出来的结果会有些吃力。
2、常用方法
2.1、Filter
Filter 为过滤的意思,只要满足 Filter 表达式的数据就可以留下来,不满足的数据被过滤掉,源码如下图:
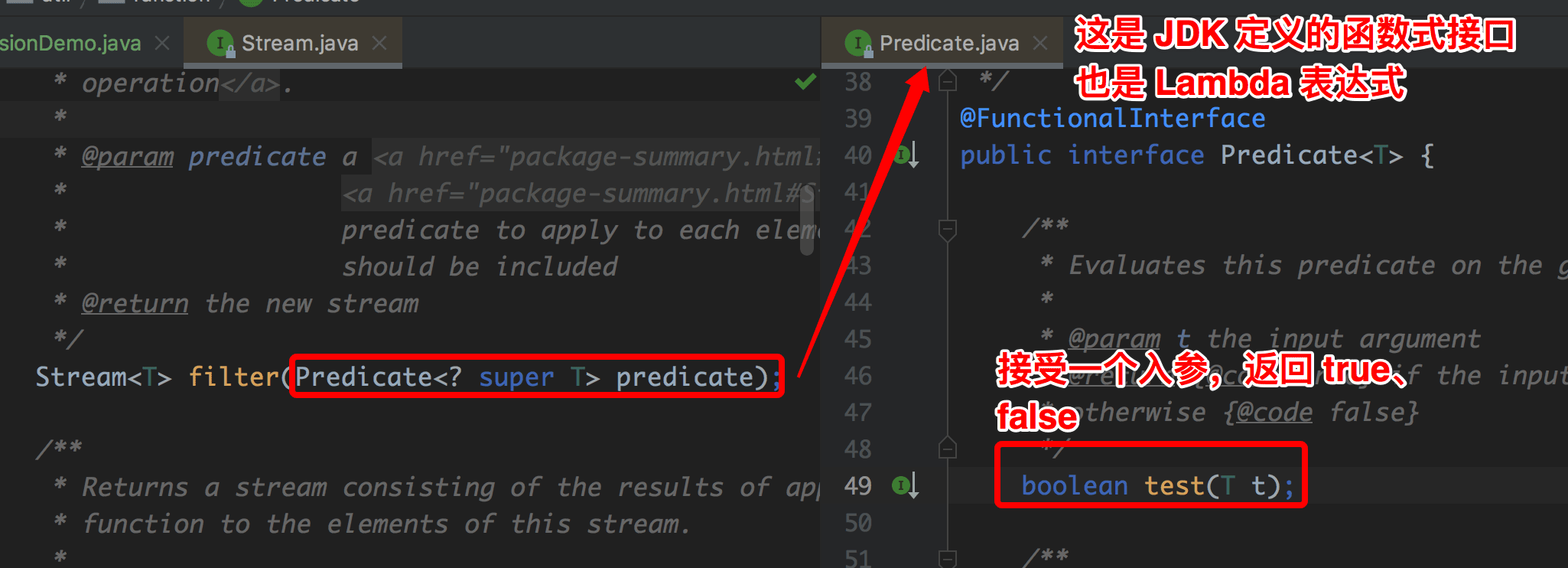
我们写了一个 demo,如下:
public void testFilter() {
// list 在下图中进行了初始化
List<String> newList = list.stream()
// 过滤掉我们希望留下来的值
// StringUtils.equals(str,"hello") 表示我们希望字符串是 hello 能留下来
// 其他的过滤掉
.filter(str -> StringUtils.equals(str, "hello"))
// Collectors.toList() 帮助我们构造最后的返回结果
.collect(Collectors.toList());
log.info("TestFilter result is {}", JSON.toJSONString(newList));
}运行结果如下:
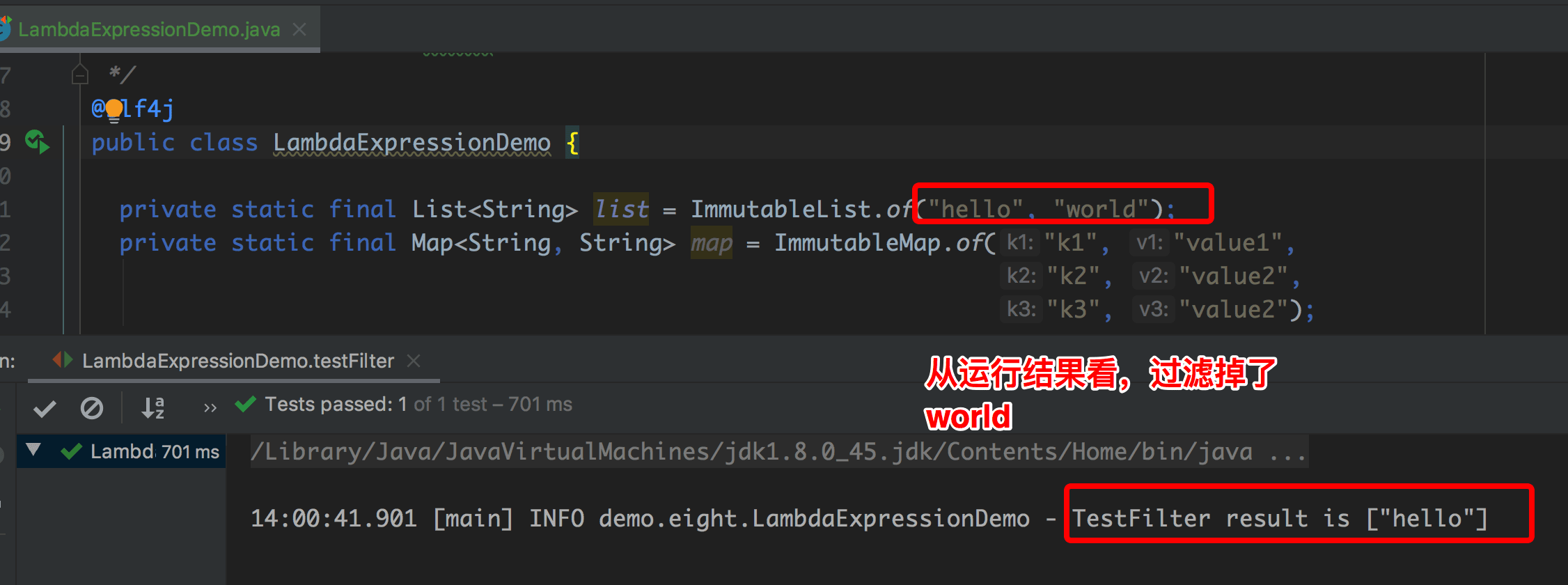
2.2、map
map 方法可以让我们进行一些流的转化,比如原来流中的元素是 A,通过 map 操作,可以使返回的流中的元素是 B,源码如下图:

我们写了一个 demo,如下:
public void testMap() {
// 得到所有学生的学号
// 这里 students.stream() 中的元素是 StudentDTO,通过 map 方法转化成 String 的流
List<String> codes = students.stream()
//StudentDTO::getCode 是 s->s.getCode() 的简写
.map(StudentDTO::getCode)
.collect(Collectors.toList());
log.info("TestMap 所有学生的学号为 {}", JSON.toJSONString(codes));
}
// 运行结果为:TestMap 所有学生的学号为 ["W199","W25","W3","W1"]2.3、mapToInt
mapToInt 方法的功能和 map 方法一样,只不过 mapToInt 返回的结果已经没有泛型,已经明确是 int 类型的流了,源码如下:
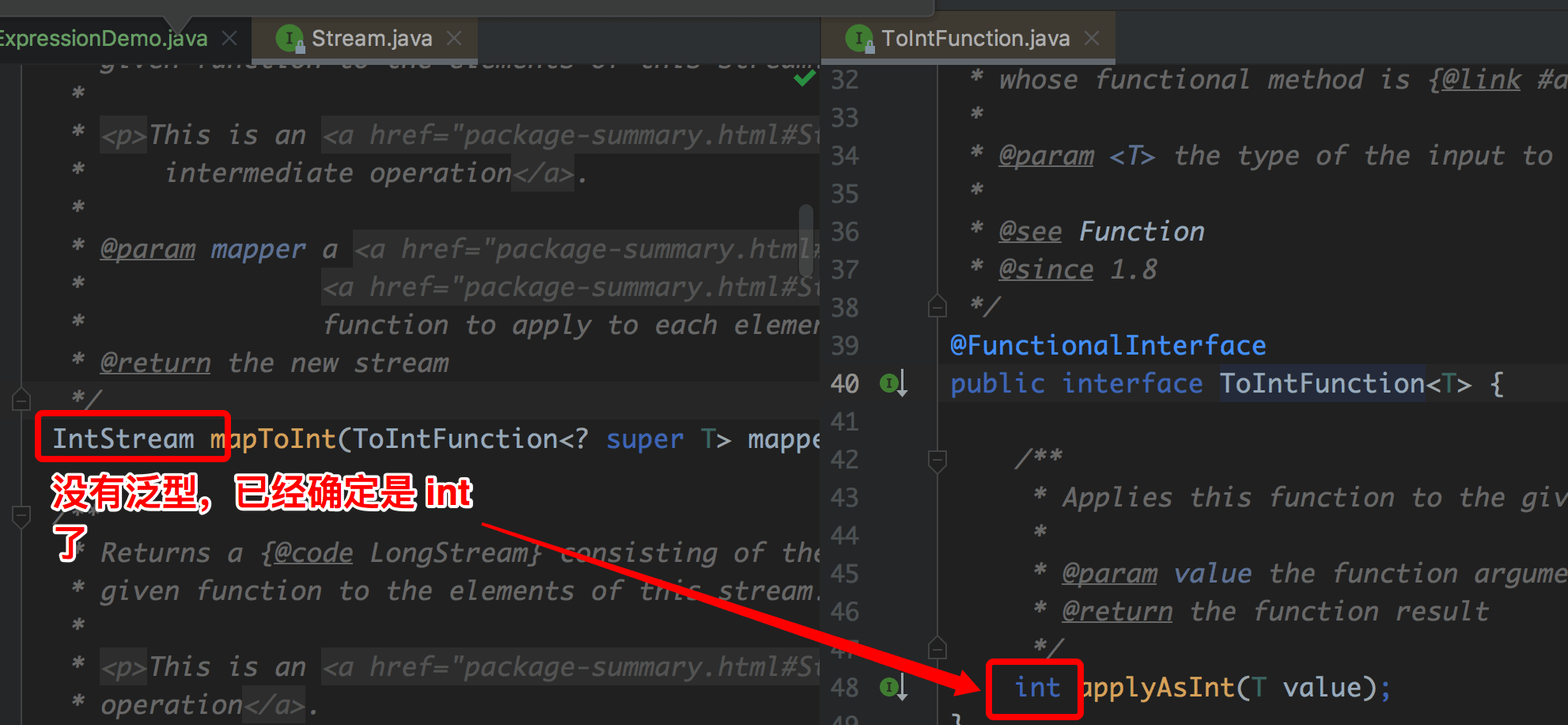
我们写了一个 demo,如下:
public void testMapToInt() {
List<Integer> ids = students.stream()
.mapToInt(s->Integer.valueOf(s.getId()+""))
// 一定要有 mapToObj,因为 mapToInt 返回的是 IntStream,因为已经确定是 int 类型了
// 所有没有泛型的,而 Collectors.toList() 强制要求有泛型的流,所以需要使用 mapToObj
// 方法返回有泛型的流
.mapToObj(s->s)
.collect(Collectors.toList());
log.info("TestMapToInt result is {}", JSON.toJSONString(ids));
// 计算学生总分
Double sumScope = students.stream()
.mapToDouble(s->s.getScope())
// DoubleStream/IntStream 有许多 sum(求和)、min(求最小值)、max(求最大值)、average(求平均值)等方法
.sum();
log.info("TestMapToInt 学生总分为: is {}", sumScope);
}运行结果如下:
TestMapToInt result is [1,2,3,4]
TestMapToInt 学生总分为: is 300.0
2.4、flatMap
flatMap 方法也是可以做一些流的转化,和 map 方法不同的是,其明确了 Function 函数的返回值的泛型是流,源码如下:
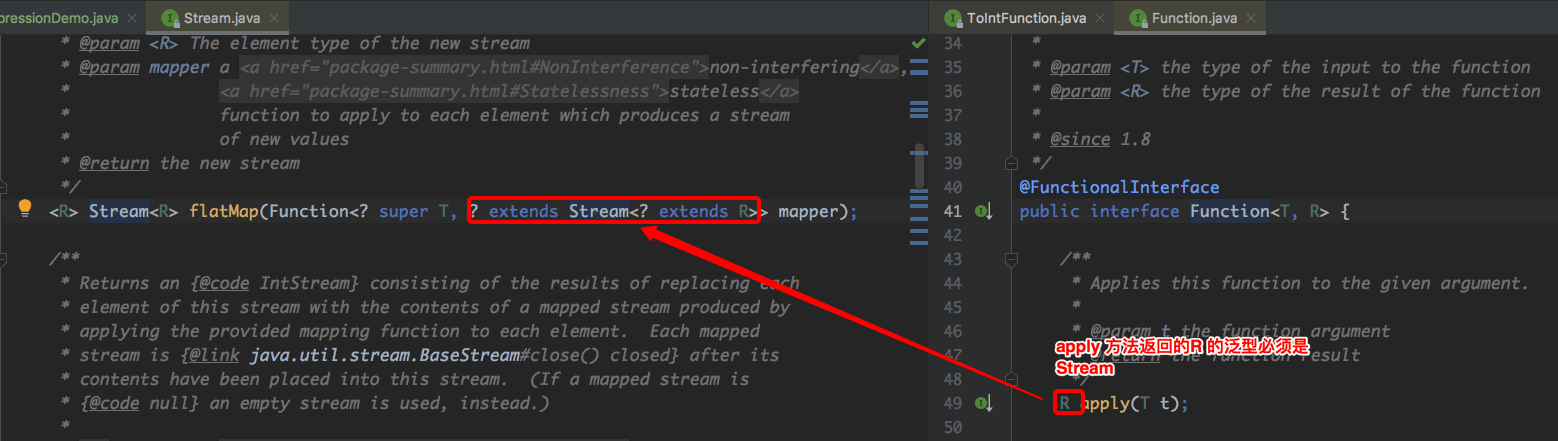
写了一个 demo,如下:
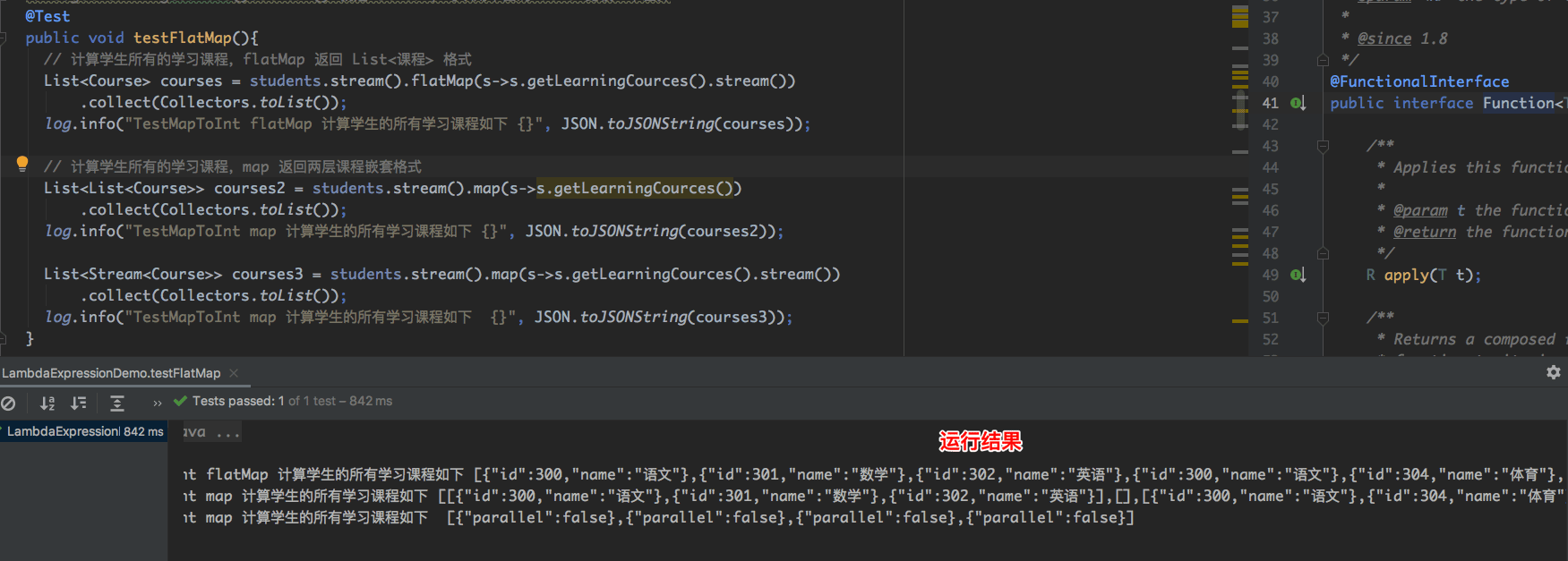
public void testFlatMap(){
// 计算学生所有的学习课程,flatMap 返回 List<课程> 格式
List<Course> courses = students.stream().flatMap(s->s.getLearningCources().stream())
.collect(Collectors.toList());
log.info("TestMapToInt flatMap 计算学生的所有学习课程如下 {}", JSON.toJSONString(courses));
// 计算学生所有的学习课程,map 返回两层课程嵌套格式
List<List<Course>> courses2 = students.stream().map(s->s.getLearningCources())
.collect(Collectors.toList());
log.info("TestMapToInt map 计算学生的所有学习课程如下 {}", JSON.toJSONString(courses2));
List<Stream<Course>> courses3 = students.stream().map(s->s.getLearningCources().stream())
.collect(Collectors.toList());
log.info("TestMapToInt map 计算学生的所有学习课程如下 {}", JSON.toJSONString(courses3));
}运行结果如下:
2.5、distinct
distinct 方法有去重的功能,我们写了一个 demo,如下:
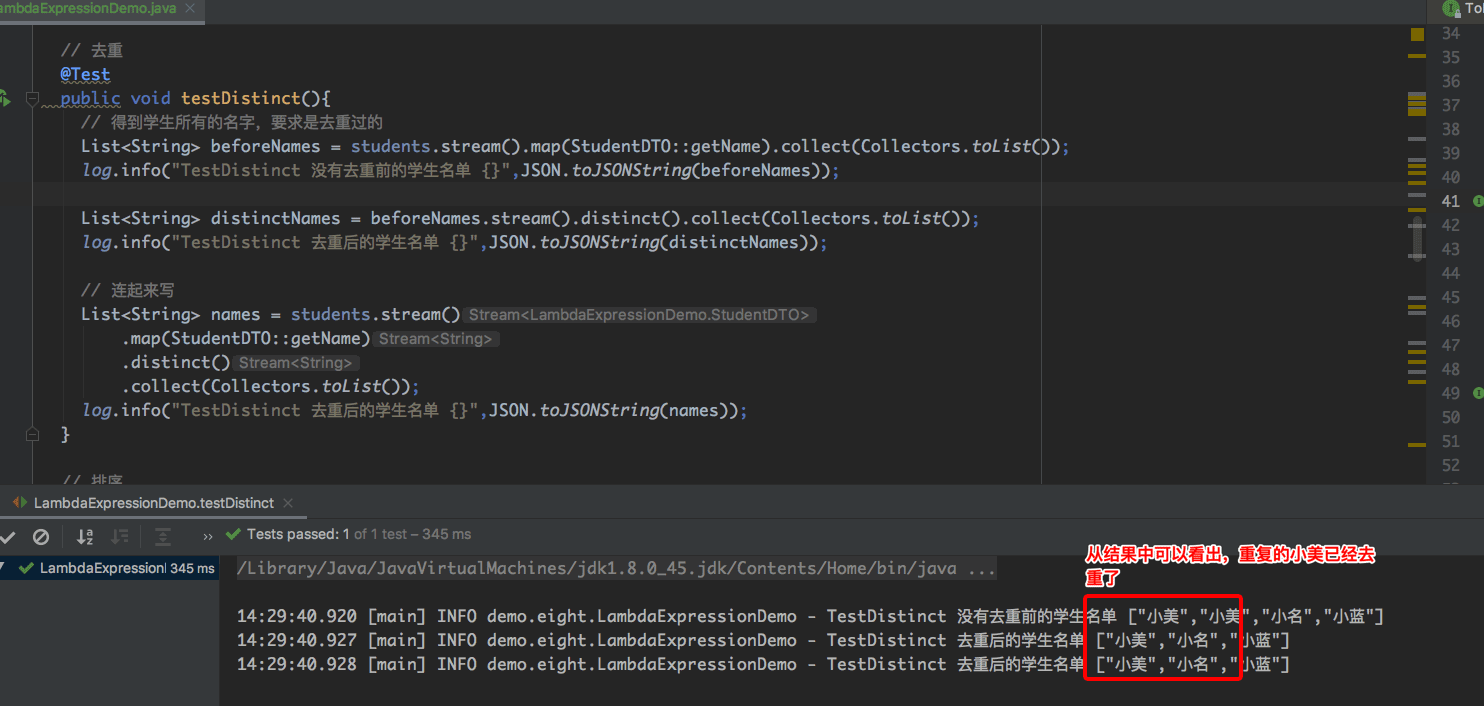
public void testDistinct(){
// 得到学生所有的名字,要求是去重过的
List<String> beforeNames = students.stream().map(StudentDTO::getName).collect(Collectors.toList());
log.info("TestDistinct 没有去重前的学生名单 {}",JSON.toJSONString(beforeNames));
List<String> distinctNames = beforeNames.stream().distinct().collect(Collectors.toList());
log.info("TestDistinct 去重后的学生名单 {}",JSON.toJSONString(distinctNames));
// 连起来写
List<String> names = students.stream()
.map(StudentDTO::getName)
.distinct()
.collect(Collectors.toList());
log.info("TestDistinct 去重后的学生名单 {}",JSON.toJSONString(names));
}运行结果如下:
2.6、Sorted
Sorted 方法提供了排序的功能,并且允许我们自定义排序,demo 如下:
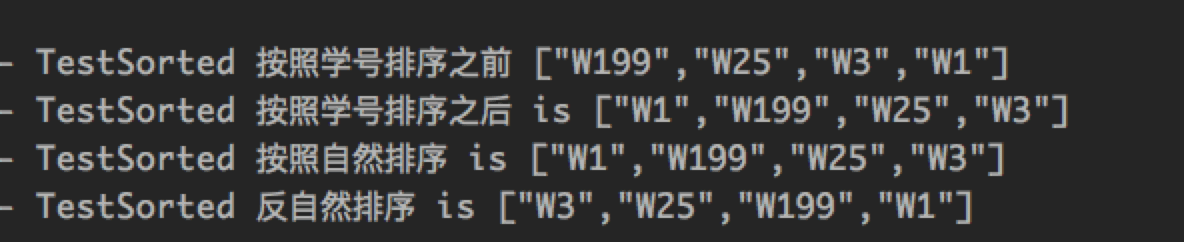
public void testSorted(){
// 学生按照学号排序
List<String> beforeCodes = students.stream().map(StudentDTO::getCode).collect(Collectors.toList());
log.info("TestSorted 按照学号排序之前 {}",JSON.toJSONString(beforeCodes));
List<String> sortedCodes = beforeCodes.stream().sorted().collect(Collectors.toList());
log.info("TestSorted 按照学号排序之后 is {}",JSON.toJSONString(sortedCodes));
// 直接连起来写
List<String> codes = students.stream()
.map(StudentDTO::getCode)
// 等同于 .sorted(Comparator.naturalOrder()) 自然排序
.sorted()
.collect(Collectors.toList());
log.info("TestSorted 自然排序 is {}",JSON.toJSONString(codes));
// 自定义排序器
List<String> codes2 = students.stream()
.map(StudentDTO::getCode)
// 反自然排序
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
log.info("TestSorted 反自然排序 is {}",JSON.toJSONString(codes2));
}运行结果如下:
2.7、peek
peek 方法很简单,我们在 peek 方法里面做任意没有返回值的事情,比如打印日志,如下:
students.stream().map(StudentDTO::getCode)
.peek(s -> log.info("当前循环的学号是{}",s))
.collect(Collectors.toList());2.8、limit
limit 方法会限制输出值个数,入参是限制的个数大小,demo 如下:
public void testLimit(){
List<String> beforeCodes = students.stream().map(StudentDTO::getCode).collect(Collectors.toList());
log.info("TestLimit 限制之前学生的学号为 {}",JSON.toJSONString(beforeCodes));
List<String> limitCodes = beforeCodes.stream()
.limit(2L)
.collect(Collectors.toList());
log.info("TestLimit 限制最大限制 2 个学生的学号 {}",JSON.toJSONString(limitCodes));
// 直接连起来写
List<String> codes = students.stream()
.map(StudentDTO::getCode)
.limit(2L)
.collect(Collectors.toList());
log.info("TestLimit 限制最大限制 2 个学生的学号 {}",JSON.toJSONString(codes));
}输出结果如下:

2.9、reduce
reduce 方法允许我们在循环里面叠加计算值,我们写了 demo 如下:
public void testReduce(){
// 计算一下学生的总分数
Double sum = students.stream()
.map(StudentDTO::getScope)
// scope1 和 scope2 表示循环中的前后两个数
.reduce((scope1,scope2) -> scope1+scope2)
.orElse(0D);
log.info("总成绩为 {}",sum);
Double sum1 = students.stream()
.map(StudentDTO::getScope)
// 第一个参数表示成绩的基数,会从 100 开始加
.reduce(100D,(scope1,scope2) -> scope1+scope2);
log.info("总成绩为 {}",sum1);
}运行结果如下:

第二个计算出来的总成绩多了 100,是因为第二个例子中 reduce 是从基数 100 开始累加的。
2.10、findFirst
findFirst 表示匹配到第一个满足条件的值就返回,demo 如下:
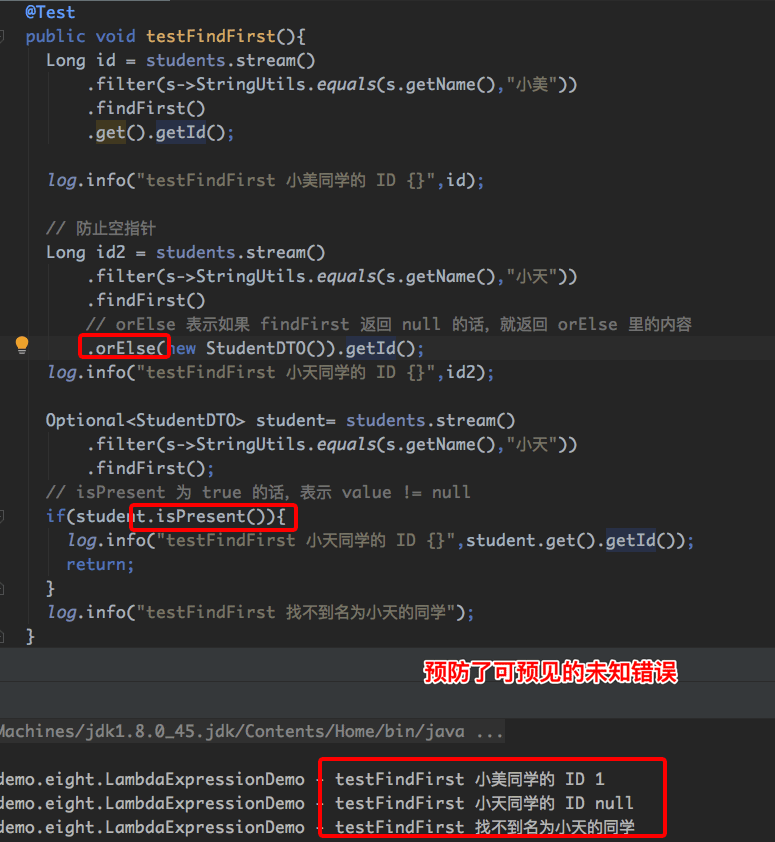
// 找到第一个叫小美同学的 ID
@Test
public void testFindFirst(){
Long id = students.stream()
.filter(s->StringUtils.equals(s.getName(),"小美"))
// 同学中有两个叫小美的,这里匹配到第一个就返回
.findFirst()
.get().getId();
log.info("testFindFirst 小美同学的 ID {}",id);
// 防止空指针
Long id2 = students.stream()
.filter(s->StringUtils.equals(s.getName(),"小天"))
.findFirst()
// orElse 表示如果 findFirst 返回 null 的话,就返回 orElse 里的内容
.orElse(new StudentDTO()).getId();
log.info("testFindFirst 小天同学的 ID {}",id2);
Optional<StudentDTO> student= students.stream()
.filter(s->StringUtils.equals(s.getName(),"小天"))
.findFirst();
// isPresent 为 true 的话,表示 value != null,即 student.get() != null
if(student.isPresent()){
log.info("testFindFirst 小天同学的 ID {}",student.get().getId());
return;
}
log.info("testFindFirst 找不到名为小天的同学");
}运行结果如下:
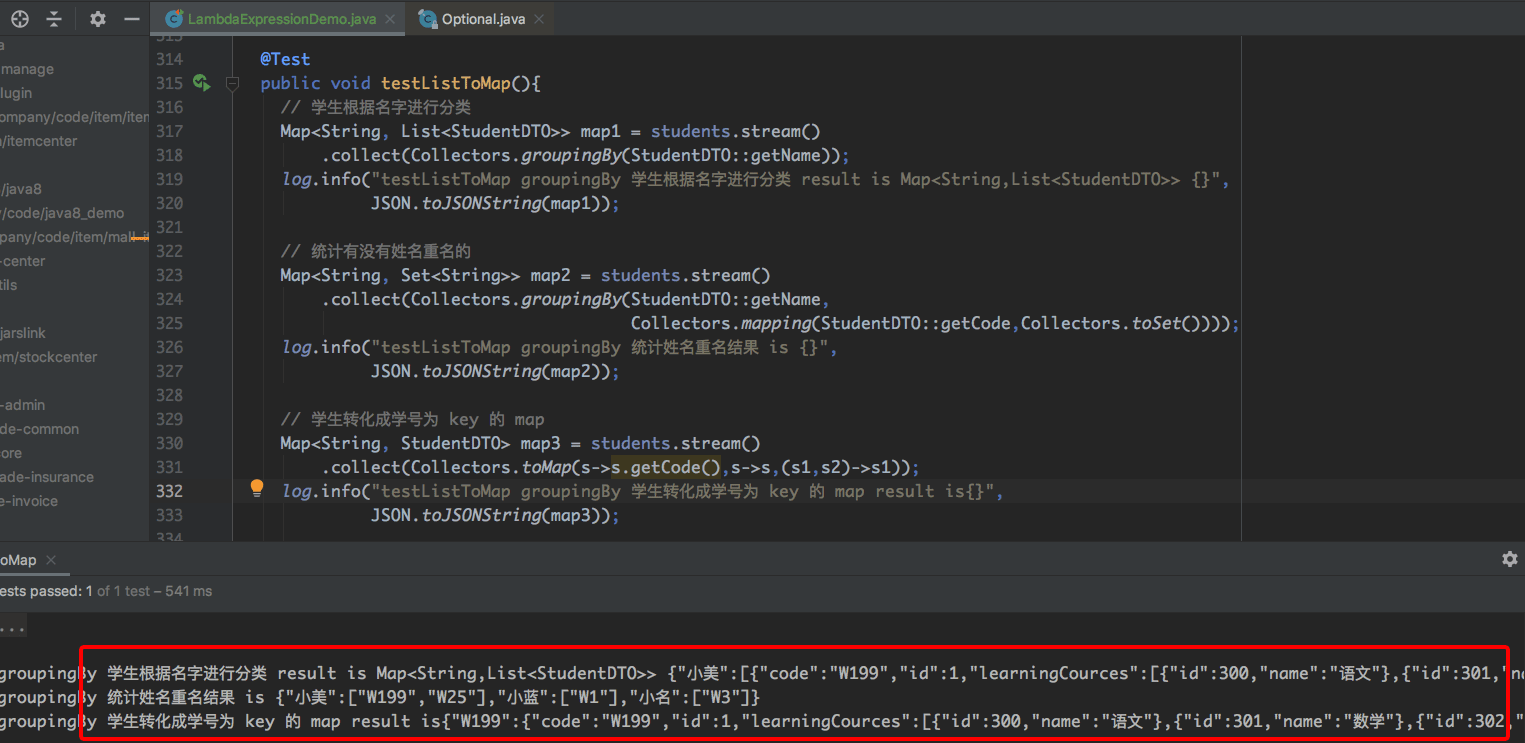
2.11、groupingBy && toMap
groupingBy 是能够根据字段进行分组,toMap 是把 List 的数据格式转化成 Map 的格式,我们写了一个 demo,如下:
@Test
public void testListToMap(){
// 学生根据名字进行分类
Map<String, List<StudentDTO>> map1 = students.stream()
.collect(Collectors.groupingBy(StudentDTO::getName));
log.info("testListToMap groupingBy 学生根据名字进行分类 result is Map<String,List<StudentDTO>> {}",
JSON.toJSONString(map1));
// 统计姓名重名的学生有哪些
Map<String, Set<String>> map2 = students.stream()
.collect(Collectors.groupingBy(StudentDTO::getName,
Collectors.mapping(StudentDTO::getCode,Collectors.toSet())));
log.info("testListToMap groupingBy 统计姓名重名结果 is {}",
JSON.toJSONString(map2));
// 学生转化成学号为 key 的 map
Map<String, StudentDTO> map3 = students.stream()
//第一个入参表示 map 中 key 的取值
//第二个入参表示 map 中 value 的取值
//第三个入参表示,如果前后的 key 是相同的,是覆盖还是不覆盖,(s1,s2)->s1 表示不覆盖,(s1,s2)->s2 表示覆盖
.collect(Collectors.toMap(s->s.getCode(),s->s,(s1,s2)->s1));
log.info("testListToMap groupingBy 学生转化成学号为 key 的 map result is{}",
JSON.toJSONString(map3));
}运行结果如下:
3、总结
本文我们介绍了 12 种 Lambda 表达式常用的方法,大家可以找到 LambdaExpressionDemo 类,自己 debug 下,这样你在工作中遇到复杂数据结构转化时,肯定会得心应手了,希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要为大家详细介绍了一行java代码实现高斯模糊效果,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-07-07
这篇文章主要为大家详细介绍了一行java代码实现高斯模糊效果,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-07-07 这篇文章主要介绍了Netty4之如何实现HTTP请求、响应问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-04-04
这篇文章主要介绍了Netty4之如何实现HTTP请求、响应问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-04-04 这篇文章主要介绍了 Mybatis开发环境搭建实现数据的增删改查功能,非常不错,具有参考借鉴价值,需要的朋友可以参考下2017-03-03
这篇文章主要介绍了 Mybatis开发环境搭建实现数据的增删改查功能,非常不错,具有参考借鉴价值,需要的朋友可以参考下2017-03-03
springboot执行延时任务之DelayQueue的使用详解
DelayQueue是一个无界阻塞队列,只有在延迟期满时,才能从中提取元素。这篇文章主要介绍了springboot执行延时任务-DelayQueue的使用,需要的朋友可以参考下2019-12-12 这篇文章主要介绍了Java基于正则表达式实现xml文件的解析功能,结合实例形式分析了java使用正则表达式针对xml文件节点的相关操作技巧,需要的朋友可以参考下2017-08-08
这篇文章主要介绍了Java基于正则表达式实现xml文件的解析功能,结合实例形式分析了java使用正则表达式针对xml文件节点的相关操作技巧,需要的朋友可以参考下2017-08-08
MyBatis映射文件中parameterType与resultType的用法详解
MyBatis中的ParameterType指的是SQL语句中的参数类型,即传入SQL语句中的参数的类型,下面这篇文章主要给大家介绍了关于MyBatis映射文件中parameterType与resultType用法的相关资料,需要的朋友可以参考下2023-04-04 这篇文章主要介绍了java poi导入纯数字等格式问题及解决,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-03-03
这篇文章主要介绍了java poi导入纯数字等格式问题及解决,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-03-03
基于Java中的StringTokenizer类详解(推荐)
下面小编就为大家带来一篇基于Java中的StringTokenizer类详解(推荐)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧2017-05-05
解决CollectionUtils.isNotEmpty()不存在的问题
这篇文章主要介绍了解决CollectionUtils.isNotEmpty()不存在的问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2022-02-02 这篇文章主要为大家详细介绍了Java实现Excel批量导入数据,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-08-08
这篇文章主要为大家详细介绍了Java实现Excel批量导入数据,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-08-08










最新评论