
C#中的LINQ to Objects详解(1)
相关文章:
一、概述
LINQ to Objects (C#) | Microsoft 官方文档
“LINQ to Objects” 指直接将 LINQ 查询与任何 IEnumerable 或 IEnumerable 集合一起使用。
可以使用 LINQ 来查询任何可枚举的集合,例如 List、Array 或Dictionary<TKey,TValue>。 该集合可以是用户定义的集合,也可以是由 .NET Framework API 返回的集合。
“LINQ to Objects”表示一种新的处理集合的方法。 采用旧方法,必须编写指定如何从集合检索数据的复杂的 foreach 循环。 而采用 LINQ 方法,只需编写描述要检索的内容的声明性代码。
此外,LINQ 查询与传统 foreach 循环相比具有三大优势:
- 它们更简明、更易读,尤其在筛选多个条件时。
- 它们使用最少的应用程序代码提供强大的筛选、排序和分组功能。
- 无需修改或只需做很小的修改即可将它们移植到其他数据源。
二、 Linq to Objects中的延迟计算
Linq查询的延迟计算原理:通过给LINQ扩展方法传递方法委托,作为yield迭代器的主体,让遍历执行到MoveNext()时才执行耗时的指令。
1. Linq延迟计算的注意点
以下代码我们原本的期望结果是:删除掉字符串中所有的原音字母。但现在只删除’u’,因为item变量是循环外部声明的,同一个变量重复声明更新,所以当最后赋值时,item记录的是最后一个值为'u'。在foreach才真正执行Where查询。
IEnumerable<char> query = "Not what you might expect";
var item = 'a';
query = query.Where(c => c != item);
item = 'e';
query = query.Where(c => c != item);
item = 'i';
query = query.Where(c => c != item);
item = 'o';
query = query.Where(c => c != item);
item = 'u';
query = query.Where(c => c != item);
foreach (char c in query)
Console.Write(c); // 只删除了'u'----Not what yo might expect2. 整理Linq to Objects中运算符延迟计算特性
按字母顺序整理:
1、具有延迟计算的运算符
Cast,Concat,DefaultIfEmpty,Distinct,Except,GroupBy,GroupJoin,Intersect,Join,OfType,OrderBy,OrderByDescending ,Repeat,Reverse,Select,SelectMany,Skip,SkipWhile,Take,TakeWhile,ThenBy,ThenByDescending,Union,Where,Zip
2、立即执行的运算符
Aggregate,All,Any,Average,Contains,Count,ElementAt,ElementAtOrDefault,Empty,First,FirstOrDefault,Last,LastOrDefault ,LongCount,Max,Min,Range,SequenceEqual,Single,SingleOrDefault,Sum,ToArray,ToDictionary,ToList,ToLookup
注意:特殊的AsEnumerable运算符,用于处理LINQ to Entities操作远程数据源,将IQueryable远程数据立即转化为本地的IEnumerable集合。若AsEnumerable接收参数是IEnumerable内存集合则什么都不做。
三、LINQ 和字符串
LINQ 可用于查询和转换字符串和字符串集合。它对文本文件中的半结构化数据尤其有用。LINQ 查询可与传统的字符串函数和正则表达式结合使用。
例如:
- 可以使用 Split 或 Split 方法来创建字符串数组,然后可以使用 LINQ 来查询或修改此数组;
- 可以在 LINQ 查询的 where 子句中使用 IsMatch 方法;
- 可以使用 LINQ 来查询或修改由正则表达式返回的 MatchCollection 结果
1、查询文本块
实例1: 统计单词在字符串中出现的次数
请注意,若要执行计数,请先调用 Split 方法来创建词数组。Split 方法存在性能开销。如果对字符串执行的唯一操作是计数词,则应考虑改用 Matches 或 IndexOf 方法。
string text = @"Historically, the world of data and the world of objects" +
@" have not been well integrated. ";
string searchTerm = "data";
//字符串转换成数组
string[] source = text.Split(new char[] { '.', '?', '!', ' ', ';', ':', ',' }, StringSplitOptions.RemoveEmptyEntries);
// 创建查询,并忽略大小写比较
var matchQuery = from word in source
where word.ToLowerInvariant() == searchTerm.ToLowerInvariant()
select word;
// 统计匹配数量.
int wordCount = matchQuery.Count();
Console.WriteLine("{0} occurrences(s) of the search term \"{1}\" were found.", wordCount, searchTerm);
//1 occurrences(s) of the search term "data" were found.实例2: 在文本文件中,找出包含一组指定单词的的句子。
在此示例中,查询将返回包含单词“Historically,”、“data,”和“integrated”的句子。 虽然在此示例中搜索条件数组是硬编码的,但也可以在运行时动态填充此数组。
string text = @"Historically, the world of data and the world of objects " +
@"have not been well integrated. Programmers work in C# or Visual Basic " +
@"and also in SQL or XQuery. On the one side are concepts such as classes, " +
@"objects, fields, inheritance, and .NET Framework APIs. On the other side " +
@"are tables, columns, rows, nodes, and separate languages for dealing with " +
@"them. Data types often require translation between the two worlds; there are " +
@"different standard functions. Because the object world has no notion of query, a " +
@"query can only be represented as a string without compile-time type checking or " +
@"IntelliSense support in the IDE. Transferring data from SQL tables or XML trees to " +
@"objects in memory is often tedious and error-prone.";
// 将文本块切割成数组.
string[] sentences = text.Split(new char[] { '.', '?', '!' });
// 定义搜索条件,此列表可以运行时动态添加.
string[] wordsToMatch = { "Historically", "data", "integrated" };
// 去重,取交集后的数量对比
var sentenceQuery = from sentence in sentences
let w = sentence.Split(new char[] { '.', '?', '!', ' ', ';', ':', ',' }, StringSplitOptions.RemoveEmptyEntries)
where w.Distinct().Intersect(wordsToMatch).Count() == wordsToMatch.Count()
select sentence;
// 执行这个查询
foreach (string str in sentenceQuery)
{
Console.WriteLine(str);
}
//Historically, the world of data and the world of objects have not been well integrated查询运行时首先将文本拆分成句子,然后将句子拆分成包含每个单词的字符串数组。对于每个这样的数组,Distinct 方法移除所有重复的单词,然后查询对单词数组和 wordstoMatch 数组执行 Intersect 操作。如果交集的计数与 wordsToMatch 数组的计数相同,则在单词中找到了所有的单词,且返回原始句子。
在对 Split 的调用中,使用标点符号作为分隔符,以从字符串中移除标点符号。如果您没有这样做,则假如您有一个字符串“Historically,”,该字符串不会与 wordsToMatch 数组中的“Historically”相匹配。根据源文本中标点的类型,您可能必须使用其他分隔符。
实例3: 查询字符串中的字符
因为 String 类实现泛型 IEnumerable 接口,所以可以将任何字符串作为字符序列进行查询。但是,这不是 LINQ 的常见用法。若要执行复杂的模式匹配操作,请使用 Regex 类。
以下示例查询一个字符串以确定它所包含的数字数量。 请注意,在第一次执行此查询后将“重用”此查询。 这是可能的,因为查询本身并不存储任何实际的结果。
string aString = "ABCDE99F-J74-12-89A";
// 只选择数字的字符
IEnumerable<char> stringQuery =
from ch in aString
where Char.IsDigit(ch)
select ch;
// 执行这个查询
foreach (char c in stringQuery)
Console.Write(c + " ");
//9 9 7 4 1 2 8 9
// 对上面的查询调用Count方法
int count = stringQuery.Count();
Console.WriteLine("Count = {0}", count);
//Count = 8
// 选择第一个“-”之前的所有字符
IEnumerable<char> stringQuery2 = aString.TakeWhile(c => c != '-');
// 执行第二个查询
foreach (char c in stringQuery2)
Console.Write(c);
//ABCDE99F实例4:用正则表达式结合 LINQ 查询
此示例演示如何使用 Regex 类创建正则表达式以便在文本字符串中进行更复杂的匹配。使用 LINQ 查询可以方便地对您要用正则表达式搜索的文件进行准确筛选,以及对结果进行加工。
//根据不同版本的 vs 修改路径
string startFolder = @"C:\Program Files (x86)\Microsoft Visual Studio 11.0\";
IEnumerable fileList = Directory.GetFiles(startFolder, "*.*", SearchOption.AllDirectories).Select(p => new System.IO.FileInfo(p));
//创建正则表达式来寻找所有的"Visual"
Regex searchTerm = new Regex(@"Visual (Basic|C#|C\+\+|Studio)");
//搜索每一个“.htm”文件
//通过 where 找到匹配项
//注意:select 中的变量要求显示声明其类型,因为 MatchCollection 不是泛型 IEnumerable 集合
var queryMatchingFiles =
from file in fileList
where file.Extension == ".htm"
let fileText = File.ReadAllText(file.FullName)
let matches = searchTerm.Matches(fileText)
where matches.Count > 0
select new
{
name = file.FullName,
matchedValues = from Match match in matches
select match.Value
};
foreach (var v in queryMatchingFiles)
{
//修剪匹配找到的文件中的路径
string s = v.name.Substring(startFolder.Length - 1);
Console.WriteLine(s);
//输出找到的匹配值
foreach (var v2 in v.matchedValues)
{
Console.WriteLine(" " + v2);
}
}
//\professional\2052\License.htm
// Visual Studio
// Visual Studio
// Visual Studio
//\VB\VBWizards\FrameSetTemplates\1033\BanToc.htm
// Visual Studio还可以查询由 RegEx 搜索返回的 MatchCollection 对象。在此示例中,结果中仅生成每个匹配项的值。但也可使用 LINQ 对该集合执行各种筛选、排序和分组操作。
【注意】由于 MatchCollection 是非泛型 IEnumerable 集合,因此必须显式声明查询中的范围变量的类型。
2、查询文本格式的半结构化数据
许多不同类型的文本文件都包含一系列行,通常具有类似的格式设置,例如制表符分隔或逗号分隔的文件或固定长度的行。
将此类文本文件读入内存后,可以使用 LINQ 来查询和/或修改其中的行。 LINQ 查询还简化了合并来自多个源的数据的任务。
实例1、如何查找两个集合间的差异
此示例演示如何使用 LINQ 对两个字符串列表进行比较,并输出那些位于 names1.txt 中但不在 names2.txt 中的行。
names1.txt
Bankov, Peter
Holm, Michael
Garcia, Hugo
Potra, Cristina
Noriega, Fabricio
Aw, Kam Foo
Beebe, Ann
Toyoshima, Tim
Guy, Wey Yuan
Garcia, Debra
names2.txt
Liu, Jinghao
Bankov, Peter
Holm, Michael
Garcia, Hugo
Beebe, Ann
Gilchrist, Beth
Myrcha, Jacek
Giakoumakis, Leo
McLin, Nkenge
El Yassir, Mehdi
代码:
//创建数据源
var names1Text = File.ReadAllLines(@"names1.txt");
var names2Text = File.ReadAllLines(@"names2.txt");
//创建查询,这里必须使用方法语法
var query = names1Text.Except(names2Text);
//执行查询
Console.WriteLine("The following lines are in names1.txt but not names2.txt");
foreach (var name in query)
{
Console.WriteLine(name);
}
【注意】某些类型的查询操作(如 Except、Distinct、Union 和 Concat)只能用基于方法的语法表示。
实例2: 根据某字段进行排序或过滤文本行
下面的示例演示如何按结构化文本(如逗号分隔值)行中的任意字段对该文本行进行排序。可在运行时动态指定该字段。此示例还演示如何从方法返回查询变量。
scores.csv:假定 scores.csv 中的字段表示学生的 ID 号,后面跟四个测验分数。
111, 97, 92, 81, 60
112, 75, 84, 91, 39
113, 88, 94, 65, 91
114, 97, 89, 85, 82
115, 35, 72, 91, 70
116, 99, 86, 90, 94
117, 93, 92, 80, 87
118, 92, 90, 83, 78
119, 68, 79, 88, 92
120, 99, 82, 81, 79
121, 96, 85, 91, 60
122, 94, 92, 91, 91
// 创建数据源
string[] scores = System.IO.File.ReadAllLines(@"scores.csv");
// 可以改为 0~4 的任意值
int sortField = 1;
Console.WriteLine("Sorted highest to lowest by field [{0}]:", sortField);
//演示从方法返回查询,这里执行查询
foreach (string str in RunQuery(scores, sortField))
{
Console.WriteLine(str);
}
// Keep the console window open in debug mode.
Console.WriteLine("Press any key to exit");
// 返回查询变量,非查询结果
static IEnumerable<string> RunQuery(IEnumerable<string> source, int num)
{
// 分割字符串来排序
var scoreQuery = from line in source
let fields = line.Split(',')
orderby fields[num] descending
select line;
return scoreQuery;
}
/* Output (if sortField == 1):
Sorted highest to lowest by field [1]:
116, 99, 86, 90, 94
120, 99, 82, 81, 79
111, 97, 92, 81, 60
114, 97, 89, 85, 82
121, 96, 85, 91, 60
122, 94, 92, 91, 91
117, 93, 92, 80, 87
118, 92, 90, 83, 78
113, 88, 94, 65, 91
112, 75, 84, 91, 39
119, 68, 79, 88, 92
115, 35, 72, 91, 70
*/实例3、如何对一个分割的文件的字段重新排序
逗号分隔值 (CSV) 文件是一种文本文件,通常用于存储电子表格数据或其他由行和列表示的表格数据。通过使用 Split 方法分隔字段,可以非常轻松地使用 LINQ 来查询和操作 CSV 文件。事实上,可以使用此技术来重新排列任何结构化文本行部分;此技术不局限于 CSV 文件。
在下面的示例中,假定有三列分别代表学生的“姓氏”、“名字”和“ID”。这些字段基于学生的姓氏按字母顺序排列。查询生成一个新序列,其中首先出现的是 ID 列,后面的第二列组合了学生的名字和姓氏。根据 ID 字段重新排列各行。结果保存到新文件,但不修改原始数据。
spreadsheet1.csv
Adams,Terry,120
Fakhouri,Fadi,116
Feng,Hanying,117
Garcia,Cesar,114
Garcia,Debra,115
Garcia,Hugo,118
Mortensen,Sven,113
O'Donnell,Claire,112
Omelchenko,Svetlana,111
Tucker,Lance,119
Tucker,Michael,122
Zabokritski,Eugene,121
代码
//数据源
var lines = File.ReadAllLines(@"spreadsheet1.csv");
//将旧数据的第2列的字段放到第一位,逆向结合第0列和第1列的字段
var query = from line in lines
let t = line.Split(',')
orderby t[2]
select $"{t[2]}, {t[1]} {t[0]}";
foreach (var q in query)
{
Console.WriteLine(q);
}
//写入文件
File.WriteAllLines("spreadsheet2.csv", query);
实例4、如何组合和比较字符串集合
此示例演示如何合并包含文本行的文件,然后排序结果。具体来说,此示例演示如何对两组文本行执行简单的串联、联合和交集。
names1.txt
Bankov, Peter
Holm, Michael
Garcia, Hugo
Potra, Cristina
Noriega, Fabricio
Aw, Kam Foo
Beebe, Ann
Toyoshima, Tim
Guy, Wey Yuan
Garcia, Debra
names2.txt
Liu, Jinghao
Bankov, Peter
Holm, Michael
Garcia, Hugo
Beebe, Ann
Gilchrist, Beth
Myrcha, Jacek
Giakoumakis, Leo
McLin, Nkenge
El Yassir, Mehdi
代码:
var names1Text = File.ReadAllLines(@"names1.txt");
var names2Text = File.ReadAllLines(@"names2.txt");
//简单连接,并排序。重复保存。
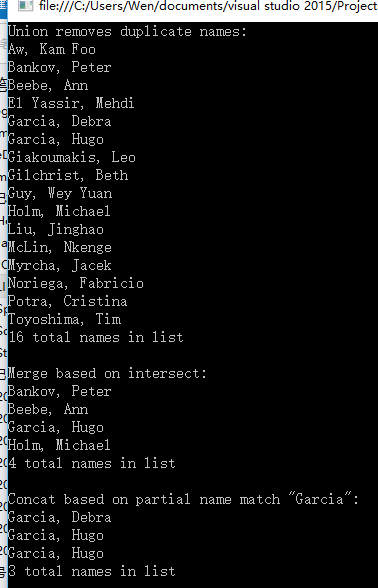
var concatQuery = names1Text.Concat(names2Text).OrderBy(x => x);
OutputQueryResult(concatQuery, "Simple concatenate and sort. Duplicates are preserved:");
//基于默认字符串比较器连接,并删除重复。
var unionQuery = names1Text.Union(names2Text).OrderBy(x => x);
OutputQueryResult(unionQuery, "Union removes duplicate names:");
//查找在两个文件中出现的名称
var intersectQuery = names1Text.Intersect(names2Text).OrderBy(x => x);
OutputQueryResult(intersectQuery, "Merge based on intersect:");
//在每个列表中找到匹配的字段。使用 concat 将两个结果合并,然后使用默认的字符串比较器进行排序
const string nameMatch = "Garcia";
var matchQuery1 = from name in names1Text
let t = name.Split(',')
where t[0] == nameMatch
select name;
var matchQuery2 = from name in names2Text
let t = name.Split(',')
where t[0] == nameMatch
select name;
var temp = matchQuery1.Concat(matchQuery2).OrderBy(x => x);
OutputQueryResult(temp, $"Concat based on partial name match \"{nameMatch}\":");
private static void OutputQueryResult(IEnumerable<string> querys, string title)
{
Console.WriteLine(Environment.NewLine + title);
foreach (var query in querys)
{
Console.WriteLine(query);
}
Console.WriteLine($"{querys.Count()} total names in list");
}
实例5:从多个源填充对象集合
不要尝试将内存中的数据或文件系统中的数据与仍在数据库中的数据相联接。此种跨域联接会生成未定义的结果,因为数据库查询和其他类型的源定义联接运算的方式可能不同。另外,如果数据库中的数据量足够大,则存在此类运算引发内存不足异常的风险。
若要将数据库数据与内存中的数据相联接,请首先对数据库查询调用 ToList 或 ToArray,然后对返回的集合执行联接。
//每行 names.csv 包含姓氏,名字,和身份证号,以逗号分隔。例如,Omelchenko,Svetlana,111
var names = File.ReadAllLines(@"names.csv");
//每行 scores.csv 包括身份证号码和四个测试评分,以逗号分隔。例如,111,97,92,81,60
var scores = File.ReadAllLines(@"scores.csv");
//使用一个匿名的类型合并数据源。
//【注意】动态创建一个 int 的考试成绩成员列表。
//跳过分割字符串中的第一项,因为它是学生的身份证,不是一个考试成绩
var students = from name in names
let t = name.Split(',')
from score in scores
let t2 = score.Split(',')
where t[2] == t2[0]
select new
{
FirstName = t[0],
LastName = t[1],
ID = Convert.ToInt32(t[2]),
ExamScores = (from scoreAsText in t2.Skip(1)
select Convert.ToInt32(scoreAsText)).ToList()
};
//显示每个学生的名字和考试平均成绩。
foreach (var student in students)
{
Console.WriteLine(
$"The average score of {student.FirstName} {student.LastName} is {student.ExamScores.Average()}.");
}
实例6、如何向不同的文件中加入内容
此示例演示如何联接两个逗号分隔文件中的数据,这两个文件共享一个用作匹配键的共同值。如果您必须将两个电子表格的数据或一个电子表格和一个其他格式的文件的数据组合为一个新文件,则此技术很有用。还可以修改此示例以适合任意种类的结构化文本。
names.csv:此文件表示一个电子表格。该电子表格包含学生的姓氏、名字和学生 ID。
Omelchenko,Svetlana,111
O'Donnell,Claire,112
Mortensen,Sven,113
Garcia,Cesar,114
Garcia,Debra,115
Fakhouri,Fadi,116
Feng,Hanying,117
Garcia,Hugo,118
Tucker,Lance,119
Adams,Terry,120
Zabokritski,Eugene,121
Tucker,Michael,122
scores.csv:此文件表示电子表格数据。第 1 列是学生的 ID,第 2 至 5 列是测验分数。
111, 97, 92, 81, 60
112, 75, 84, 91, 39
113, 88, 94, 65, 91
114, 97, 89, 85, 82
115, 35, 72, 91, 70
116, 99, 86, 90, 94
117, 93, 92, 80, 87
118, 92, 90, 83, 78
119, 68, 79, 88, 92
120, 99, 82, 81, 79
121, 96, 85, 91, 60
122, 94, 92, 91, 91
代码:
var names = File.ReadAllLines(@"names.csv");
var scores = File.ReadAllLines(@"scores.csv");
//Name: Last[0], First[1], ID[2]
// Omelchenko, Svetlana, 11
//Score: StudentID[0], Exam1[1] Exam2[2], Exam3[3], Exam4[4]
// 111, 97, 92, 81, 60
//该查询基于 id 连接两个不同的电子表格
var query = from name in names
let t1 = name.Split(',')
from score in scores
let t2 = score.Split(',')
where t1[2] == t2[0]
orderby t1[0]
select $"{t1[0]},{t2[1]},{t2[2]},{t2[3]},{t2[4]}";
//输出
OutputQueryResult(query, "Merge two spreadsheets:");
private static void OutputQueryResult(IEnumerable<string> querys, string title)
{
Console.WriteLine(Environment.NewLine + title);
foreach (var query in querys)
{
Console.WriteLine(query);
}
Console.WriteLine($"{querys.Count()} total names in list");
}
实例7:如何使用 group 将一个文件拆分成多个文件
此示例演示一种进行以下操作的方法:合并两个文件的内容,然后创建一组以新方式组织数据的新文件。
name1.txt
Bankov, Peter
Holm, Michael
Garcia, Hugo
Potra, Cristina
Noriega, Fabricio
Aw, Kam Foo
Beebe, Ann
Toyoshima, Tim
Guy, Wey Yuan
Garcia, Debra
name2.text
Liu, Jinghao
Bankov, Peter
Holm, Michael
Garcia, Hugo
Beebe, Ann
Gilchrist, Beth
Myrcha, Jacek
Giakoumakis, Leo
McLin, Nkenge
El Yassir, Mehdi
name2.txt
Liu, Jinghao
Bankov, Peter
Holm, Michael
Garcia, Hugo
Beebe, Ann
Gilchrist, Beth
Myrcha, Jacek
Giakoumakis, Leo
McLin, Nkenge
El Yassir, Mehdi
代码:
var fileA = File.ReadAllLines(@"names1.txt");
var fileB = File.ReadAllLines(@"names2.txt");
//并集:连接并删除重复的名字
var mergeQuery = fileA.Union(fileB);
//根据姓氏的首字母对姓名进行分组
var query = from name in mergeQuery
let t = name.Split(',')
group name by t[0][0] into g
orderby g.Key
select g;
//为创建的每个组创建一个新文件,请注意,需要使用嵌套的foreach循环来访问每个组的单个项。
foreach (var g in query)
{
var fileName = @"testFile_" + g.Key + ".txt";
Console.WriteLine(g.Key + ":");
//写入文件
using (var sw = new StreamWriter(fileName))
{
foreach (var name in g)
{
sw.WriteLine(name);
Console.WriteLine(" " + name);
}
}
}
对于与数据文件位于同一文件夹中的每个组,程序将为这些组编写单独的文件。
实例8、如何计算一个 CSV 文本文件中的列值
此示例演示如何对 .csv 文件的列执行诸如 Sum、Average、Min 和 Max 等聚合计算。此处所示的示例原则可以应用于其他类型的结构化文本。
scores.csv
111, 97, 92, 81, 60
112, 75, 84, 91, 39
113, 88, 94, 65, 91
114, 97, 89, 85, 82
115, 35, 72, 91, 70
116, 99, 86, 90, 94
117, 93, 92, 80, 87
118, 92, 90, 83, 78
119, 68, 79, 88, 92
120, 99, 82, 81, 79
121, 96, 85, 91, 60
122, 94, 92, 91, 91
scores.csv:假定第一列表示学员 ID,后面几列表示四次考试的分数。
var scores = File.ReadAllLines(@"scores.csv");
//指定要计算的列
const int examNum = 3;
//scores.csv 格式:
//Student ID Exam#1 Exam#2 Exam#3 Exam#4
//111, 97, 92, 81, 60
//+1 表示跳过第一列
//计算单一列
SingleColumn(scores, examNum + 1);
Console.WriteLine();
//计算多列
MultiColumns(scores);
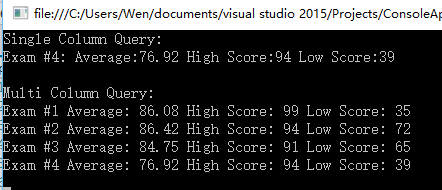
private static void SingleColumn(IEnumerable<string> strs, int examNum)
{
Console.WriteLine("Single Column Query:");
//查询分两步:
// 1.分割字符串
// 2.对要计算的列的值转换为 int
var query = from str in strs
let t = str.Split(',')
select Convert.ToInt32(t[examNum]);
//对指定的列进行统计
var average = query.Average();
var max = query.Max();
var min = query.Min();
Console.WriteLine($"Exam #{examNum}: Average:{average:##.##} High Score:{max} Low Score:{min}");
}
private static void MultiColumns(IEnumerable<string> strs)
{
Console.WriteLine("Multi Column Query:");
//查询步骤:
// 1.分割字符串
// 2.跳过 id 列(第一列)
// 3.将当前行的每个评分都转换成 int,并选择整个序列作为一行结果。
var query = from str in strs
let t1 = str.Split(',')
let t2 = t1.Skip(1)
select (from t in t2
select Convert.ToInt32(t));
//执行查询并缓存结果以提高性能
var results = query.ToList();
//找出结果的列数
var count = results[0].Count();
//执行统计
//为每一列分数的循环执行一次循环
for (var i = 0; i < count; i++)
{
var query2 = from result in results
select result.ElementAt(i);
var average = query2.Average();
var max = query2.Max();
var min = query2.Min();
//+1 因为 #1 表示第一次考试
Console.WriteLine($"Exam #{i + 1} Average: {average:##.##} High Score: {max} Low Score: {min}");
}
}
查询的工作原理是使用 Split 方法将每一行文本转换为数组。每个数组元素表示一列。最后,每一列中的文本都转换为其数字表示形式。如果文件是制表符分隔文件,只需将 Split 方法中的参数更新为 \t。
实例9、从 CSV 文件生成 XML
下面的代码对字符串数组执行 LINQ 查询。
该查询使用 let 子句将每个字符串分隔成字段数组。
// Create the text file.
string csvString = @"GREAL,Great Lakes Food Market,Howard Snyder,Marketing Manager,(503) 555-7555,2732 Baker Blvd.,Eugene,OR,97403,USA
HUNGC,Hungry Coyote Import Store,Yoshi Latimer,Sales Representative,(503) 555-6874,City Center Plaza 516 Main St.,Elgin,OR,97827,USA
LAZYK,Lazy K Kountry Store,John Steel,Marketing Manager,(509) 555-7969,12 Orchestra Terrace,Walla Walla,WA,99362,USA
LETSS,Let's Stop N Shop,Jaime Yorres,Owner,(415) 555-5938,87 Polk St. Suite 5,San Francisco,CA,94117,USA";
File.WriteAllText("cust.csv", csvString);
// Read into an array of strings.
string[] source = File.ReadAllLines("cust.csv");
XElement cust = new XElement("Root",
from str in source
let fields = str.Split(',')
select new XElement("Customer",
new XAttribute("CustomerID", fields[0]),
new XElement("CompanyName", fields[1]),
new XElement("ContactName", fields[2]),
new XElement("ContactTitle", fields[3]),
new XElement("Phone", fields[4]),
new XElement("FullAddress",
new XElement("Address", fields[5]),
new XElement("City", fields[6]),
new XElement("Region", fields[7]),
new XElement("PostalCode", fields[8]),
new XElement("Country", fields[9])
)
)
);
Console.WriteLine(cust);到此这篇关于C#中LINQ to Objects的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
相关文章
 这篇文章介绍了C#开发Winform实现文件操作的案例,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-04-04
这篇文章介绍了C#开发Winform实现文件操作的案例,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-04-04 CsvHelper 是一个用于读写 CSV 文件的.NET库,极其快速,灵活且易于使用,CsvHelper 建立在.NET Standard 2.0 之上,几乎可以在任何地方运行,本文给大家介绍了C#使用csvhelper实现csv的基本操作,需要的朋友可以参考下2024-07-07
CsvHelper 是一个用于读写 CSV 文件的.NET库,极其快速,灵活且易于使用,CsvHelper 建立在.NET Standard 2.0 之上,几乎可以在任何地方运行,本文给大家介绍了C#使用csvhelper实现csv的基本操作,需要的朋友可以参考下2024-07-07 这篇文章主要介绍了C#使用Socket实现通信的方法示例,文章按照 Socket 的 创建、连接、传输数据、释放资源的过程来写,给出方法、参数的详细信息,文中有详细的代码示例供大家参考,需要的朋友可以参考下2024-06-06
这篇文章主要介绍了C#使用Socket实现通信的方法示例,文章按照 Socket 的 创建、连接、传输数据、释放资源的过程来写,给出方法、参数的详细信息,文中有详细的代码示例供大家参考,需要的朋友可以参考下2024-06-06 这篇文章介绍了C#8.0的新语法using declaration,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-07-07
这篇文章介绍了C#8.0的新语法using declaration,文中通过示例代码介绍的非常详细。对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2022-07-07 这篇文章主要介绍了C# PropertyGrid使用案例详解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下2021-08-08
这篇文章主要介绍了C# PropertyGrid使用案例详解,本篇文章通过简要的案例,讲解了该项技术的了解与使用,以下就是详细内容,需要的朋友可以参考下2021-08-08 这篇文章主要为大家详细介绍了C#实现较为实用SQLhelper的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-10-10
这篇文章主要为大家详细介绍了C#实现较为实用SQLhelper的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2016-10-10 这篇文章主要介绍了详解如何在C#中使用投影(Projection),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-01-01
这篇文章主要介绍了详解如何在C#中使用投影(Projection),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-01-01 这篇文章主要介绍了C#中数组段用法,实例分析了C#数组段的定义、功能及使用方法,需要的朋友可以参考下2015-05-05
这篇文章主要介绍了C#中数组段用法,实例分析了C#数组段的定义、功能及使用方法,需要的朋友可以参考下2015-05-05 C#标识符还是比较常见的东西,这里我们主要介绍C#标识符中的用法,包括介绍 static 的方法和bool 的形参等方面2014-01-01
C#标识符还是比较常见的东西,这里我们主要介绍C#标识符中的用法,包括介绍 static 的方法和bool 的形参等方面2014-01-01 这篇文章主要为大家详细介绍了C#实现简易计算器,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-07-07
这篇文章主要为大家详细介绍了C#实现简易计算器,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2021-07-07










最新评论