
MySQL 去重实例操作详解
前言
在 MySQL 中,最常见的去重方法有两个:使用 distinct 或使用 group by,那它们有什么区别呢?接下来我们一起来看。
1.创建测试数据
最终展现效果如下:

2.distinct 使用
distinct 基本语法如下:
SELECT DISTINCT column_name,column_name FROM table_name;
2.1 单列去重
我们先用 distinct 实现单列去重,根据 aid(文章 ID)去重,具体实现如下:
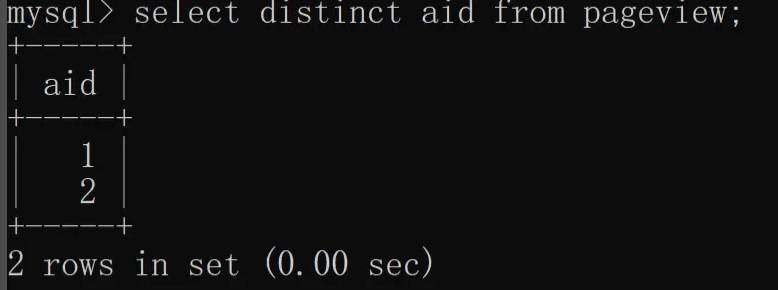
2.2 多列去重
除了单列去重之外,distinct 还支持多列(两列及以上)去重,我们根据 aid(文章 ID)和 uid(用户 ID)联合去重,具体实现如下:
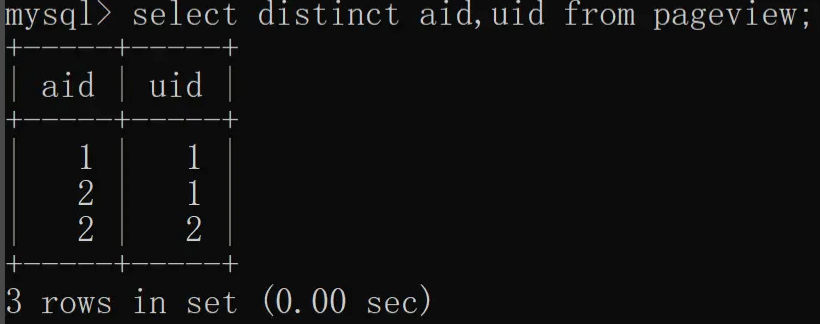
2.3 聚合函数+去重
使用 distinct + 聚合函数去重,计算 aid 去重之后的总条数,具体实现如下:

3.group by 使用
group by 基础语法如下:
SELECT column_name,column_name FROM table_name WHERE column_name operator value GROUP BY column_name
3.1 单列去重
根据 aid(文章 ID)去重,具体实现如下:

与 distinct 相比 group by 可以显示更多的列,而 distinct 只能展示去重的列。
3.2 多列去重
根据 aid(文章 ID)和 uid(用户 ID)联合去重,具体实现如下:
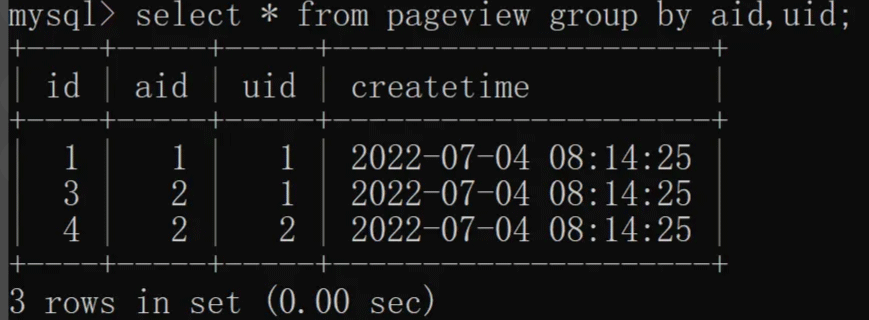
3.3 聚合函数 + group by
统计每个 aid 的总数量,SQL 实现如下:

从上述结果可以看出,使用 group by 和 distinct 加 count 的查询语义是完全不同的,distinct + count 统计的是去重之后的总数量,而 group by + count 统计的是分组之后的每组数据的总数。
4.distinct 和 group by 的区别
官方文档在描述 distinct 时提到:在大多数情况下 distinct 是特殊的 group by,如下图所示:

官方文档地址:但二者还是有一些细微的不同的,比如以下几个。
区别1:查询结果集不同
当使用 distinct 去重时,查询结果集中只有去重列信息,如下图所示:

当你试图添加非去重字段(查询)时,SQL 会报错如下图所示:

而使用 group by 排序可以查询一个或多个字段,如下图所示:

区别2:使用业务场景不同
统计去重之后的总数量需要使用 distinct,而统计分组明细,或在分组明细的基础上添加查询条件时,就得使用 group by 了。
使用 distinct 统计某列去重之后的总数量:

统计分组之后数量大于 2 的文章,就要使用 group by 了,如下图所示:

区别3:性能不同
如果去重的字段有索引,那么 group by 和 distinct 都可以使用索引,此情况它们的性能是相同的;而当去重的字段没有索引时,distinct 的性能就会高于 group by,因为在 MySQL 8.0 之前,group by 有一个隐藏的功能会进行默认的排序,这样就会触发 filesort 从而导致查询性能降低。
总结
大部分场景下 distinct 是特殊的 group by,但二者也有细微的区别,比如它们在查询结果集上、使用的具体业务场景上,以及性能上都是不同的。
到此这篇关于MySQL 去重实例操作详解的文章就介绍到这了,更多相关MySQL 去重内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 MySQL由于它本身的小巧和操作的高效, 在数据库应用中越来越多的被采用.我在开发一个P2P应用的时候曾经使用MySQL来保存P2P节点,由于P2P的应用中,结点数动辄上万个,而且节点变化频繁,因此一定要保持查询和插入的高效.以下是我在使用过程中做的提高效率的三个有效的尝试. 1. 使用statement进行绑定查询 2. 随机的获取记录 3. 使用连接池管理连接.2008-01-01
MySQL由于它本身的小巧和操作的高效, 在数据库应用中越来越多的被采用.我在开发一个P2P应用的时候曾经使用MySQL来保存P2P节点,由于P2P的应用中,结点数动辄上万个,而且节点变化频繁,因此一定要保持查询和插入的高效.以下是我在使用过程中做的提高效率的三个有效的尝试. 1. 使用statement进行绑定查询 2. 随机的获取记录 3. 使用连接池管理连接.2008-01-01
Ubuntu18.0.4下mysql 8.0.20 安装配置方法图文教程
这篇文章主要为大家详细介绍了Ubuntu18.0.4下mysql 8.0.19 安装配置方法图文教程,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2020-05-05 这篇文章主要为大家详细介绍了mysql5.7.19 winx64解压缩版安装配置教程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-07-07
这篇文章主要为大家详细介绍了mysql5.7.19 winx64解压缩版安装配置教程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-07-07 这篇文章主要给大家介绍了关于mysql存储过程教程之遍历多表记录后插入第三方表中的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面来一起看看吧2018-07-07
这篇文章主要给大家介绍了关于mysql存储过程教程之遍历多表记录后插入第三方表中的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面来一起看看吧2018-07-07 今天分享下自己对于Mysql存储过程的认识与了解,这里主要说说大家常用的游标加循环的嵌套使用2012-11-11
今天分享下自己对于Mysql存储过程的认识与了解,这里主要说说大家常用的游标加循环的嵌套使用2012-11-11 这篇文章主要介绍了MySql主从复制机制全面解析的相关资料,帮助大家更好的理解和学习使用MySQL数据库,感兴趣的朋友可以了解下2021-04-04
这篇文章主要介绍了MySql主从复制机制全面解析的相关资料,帮助大家更好的理解和学习使用MySQL数据库,感兴趣的朋友可以了解下2021-04-04 这篇文章主要介绍了sysbench-0.4.12编译安装和CPU测试例子分享,本文还包含安装过程中的错误及解决方法,使用时的错误和解决方法,需要的朋友可以参考下2014-07-07
这篇文章主要介绍了sysbench-0.4.12编译安装和CPU测试例子分享,本文还包含安装过程中的错误及解决方法,使用时的错误和解决方法,需要的朋友可以参考下2014-07-07 这篇文章主要介绍了使用RPM包安装MySQL 5.7.18的教程,需要的朋友可以参考下2017-04-04
这篇文章主要介绍了使用RPM包安装MySQL 5.7.18的教程,需要的朋友可以参考下2017-04-04 这篇文章主要为大家分享了mysql 8.0.16 安装配置方法图文教程,具有一定的参考价值,感兴趣的朋友可以参考一下2019-05-05
这篇文章主要为大家分享了mysql 8.0.16 安装配置方法图文教程,具有一定的参考价值,感兴趣的朋友可以参考一下2019-05-05 MySQL是一个需要账户名密码登录的数据库,登陆后使用,它提供了一个默认的root账号,下面这篇文章主要给大家介绍了关于MySQL命令行登入的两种方式,需要的朋友可以参考下2023-04-04
MySQL是一个需要账户名密码登录的数据库,登陆后使用,它提供了一个默认的root账号,下面这篇文章主要给大家介绍了关于MySQL命令行登入的两种方式,需要的朋友可以参考下2023-04-04










最新评论