
python常用数据结构字典梳理
更新时间:2022年08月26日 11:31:50 作者:小han的日常
这篇文章主要介绍了python常用数据结构字典梳理,文章围绕主题展开详细的内容介绍,具有一定的参考价值,需要的小伙伴可以参考一下
dict字典
字典定义与使用
字典的定义:
- 字典是无序的键值对集合
- 字典用大括号{}包围
- 每个键/值对之间用一个逗号分隔
- 各个键与值之间用一个冒号分隔
- 字典是动态的
字典使用:创建
创建字典:
- --使用大括号填充键值对
- --通过构造方法dict()
- --使用字典推导式
# 创建字典
# --使用大括号填充键值对
a = {"name": "happy", "age": 18}
print(type(a), a)
# --通过构造方法dict()
b = dict()
print(type(b), b)
c = dict([("name", "happy"), ("age", 18)])
print(type(c), c)
# --使用字典推导式
d = {i: j for i, j in [("name", "happy"), ("age", 18)]}
print(type(d), d)
字典使用:访问元素
访问元素:
- --与字典也支持支持中括号记法[key]
- --字典使用键来访问其关联的值
- --访问时对应的key必须要存在
# 访问元素
# --与字典也支持支持中括号记法[key]
# --字典使用键来访问其关联的值
# --访问时对应的key必须要存在
a = {"name": "happy", "age": 18}
print(a["name"])
字典使用:操作元素
语法:dict[key]=value
添加元素:
--键不存在
修改元素:
---键已存在
# 语法:dict[key]=value
# 添加元素
# --键不存在
# 修改元素
# ---键已存在
a = {"name": "happy", "age": 18}
a["name"] = "lucky"
print(a)
a["sex"] = "man"
print(a)
字典使用:嵌套字典
嵌套字典:字典的值可以是字典对象
# 嵌套字典
# 字典的值可以是字典对象
a = {'name': {'lucky': 5, "happy": 6}, 'age': 18, 'sex': 'man'}
print(a['name']["lucky"])
a['name']["lucky"] = 10
print(a)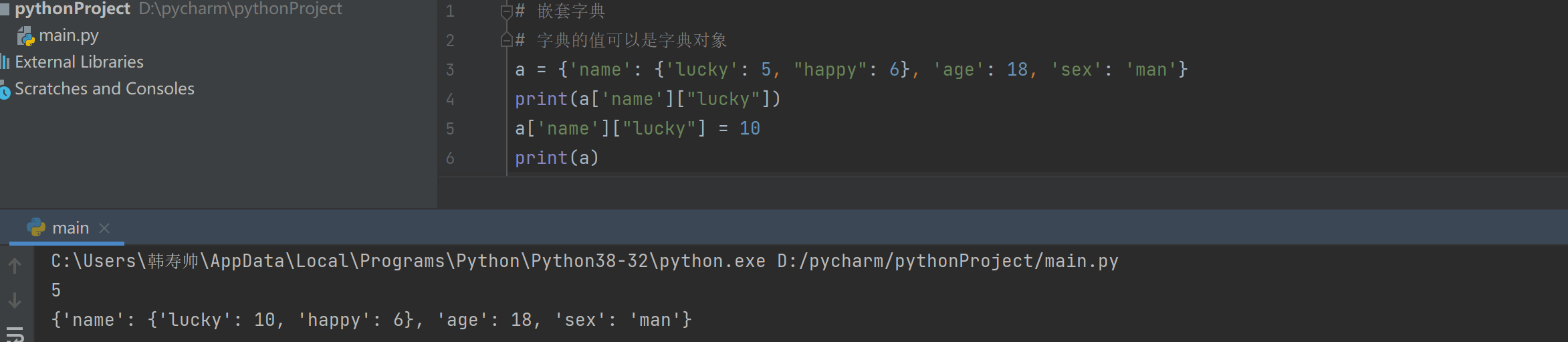
字典常用方法
- keys()
- keys()
返回由字典键组成的一个新视图对象
入参:无
返回
# 字典常用方法
# keys()
# 返回由字典键组成的一个新视图对象
# 入参:无
# 返回:
a = {'name': 'lucky', 'age': 18, 'sex': 'man'}
print(a.keys())
print(list(a.keys()))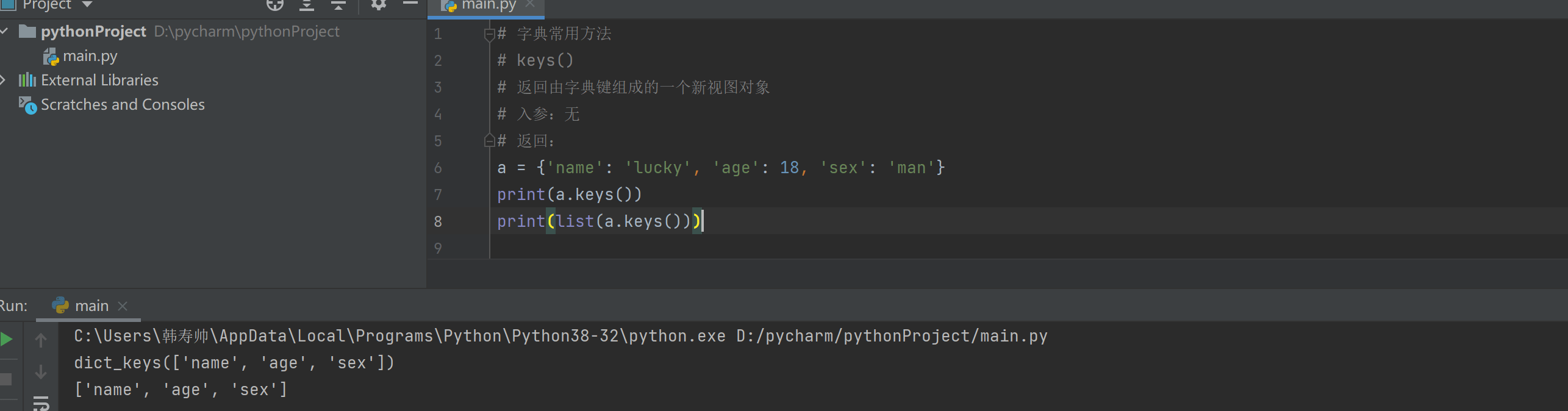
values()
values()
返回由字典值组成的一个新视图对象
入参:无
返回:
# values()
# 返回由字典值组成的一个新视图对象
# 入参:无
# 返回:
a = {'name': 'lucky', 'age': 18, 'sex': 'man'}
print(a.values())
print(list(a.values()))
items()
values()
返回由字典项((键,值)对)组成的一个新视图对象
入参:无
返回:
# items()
# 返回由字典项((键,值)对)组成的一个新视图对象
# 入参:无
# 返回
a = {'name': 'lucky', 'age': 18, 'sex': 'man'}
print(a.items())
print(list(a.items()))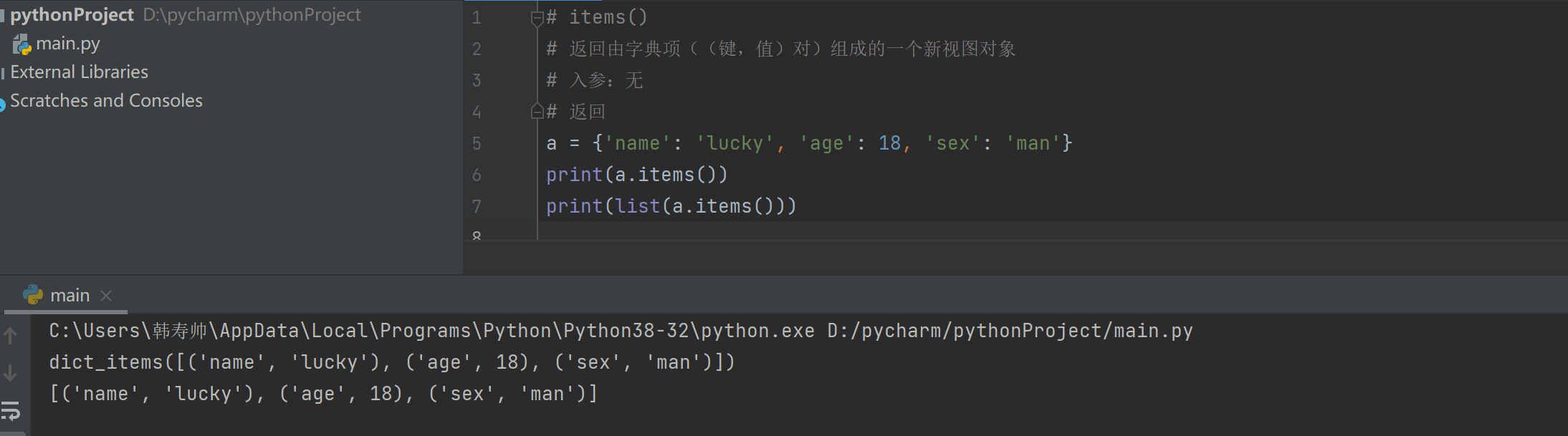
get()
get(key)
获取指定key关联的value值
入参:key:字典的键,必传
返回:
- --如果key存在于字典中,返回key关联的value值。
- --如果key不存在,则返回None
此方法的好处是无需担心key是否存在,永远都不会引发KeyError错误。
# get(key)
# 获取指定key关联的value值
# 入参:key:字典的键,必传
# 返回:
# --如果key存在于字典中,返回key关联的value值。
# --如果key不存在,则返回None
# 此方法的好处是无需担心key是否存在,永远都不会引发KeyError错误。
a = {'name': 'lucky', 'age': 18, 'sex': 'man'}
print(a.get("name"))
print(a.get("cc"))
update()
update(dict)
使用来自dict的键/值对更新字典,覆盖原有的键和值
入参:字典对象,必传
返回:None
# update(dict)
# 使用来自dict的键/值对更新字典,覆盖原有的键和值
# 入参:字典对象,必传
# 返回:None
a = {'name': 'lucky', 'age': 18, 'sex': 'man'}
a.update({'name': 'happy', 'cc': 18})
print(a)
pop()
pop(key)
删除指定key的键值对,并返回对应value值
入参:
key:必传
返回:
- --如果key存在于字典中,则将其移除并返回value值
- --如果key不存在与字典中,则会引发KeyError
# pop(key)
# 删除指定key的键值对,并返回对应value值
# 入参:
# key:必传
# 返回:
# --如果key存在于字典中,则将其移除并返回value值
# --如果key不存在与字典中,则会引发KeyError
a = {'name': 'lucky', 'age': 18, 'sex': 'man'}
print(a.pop("sex"))
print(a)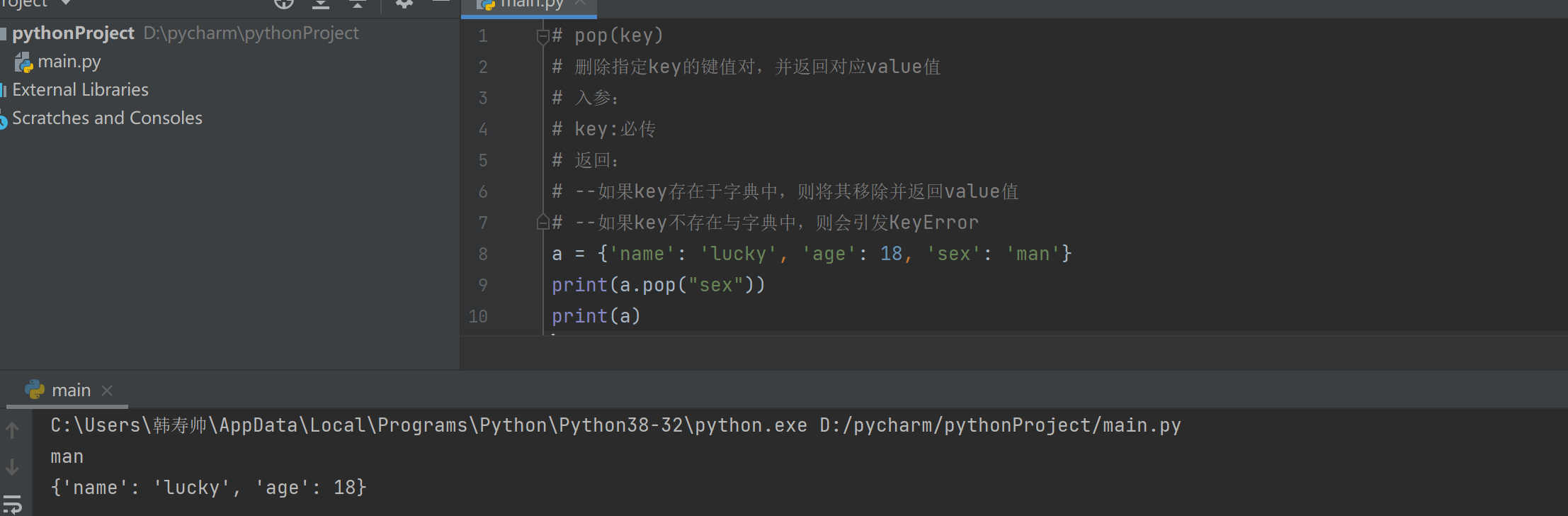
字典推导式
字典推导式:可以从任何以键值对作为元素的可迭代对象中构建出字典
实例:给定一个字典对象{"a":1,"b":2,"c":3},找出其中所有大于1的键值对,同时value值进行平方运算。
# 字典推导式:可以从任何以键值对作为元素的可迭代对象中构建出字典
# 实例:给定一个字典对象{"a":1,"b":2,"c":3},找出其中所有大于1的键值对,同时value值进行平方运算。
a = {"a": 1, "b": 2, "c": 3}
b = {i: j ** 2 for i, j in a.items() if j > 1}
print(b)
到此这篇关于python常用数据结构字典梳理的文章就介绍到这了,更多相关python 字典内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 YOLOV5模型配置文件存放在modules文件夹下,这里使用的是 yolov5s.yaml,下面这篇文章主要给大家介绍了关于yolov5模型配置yaml文件的相关资料,需要的朋友可以参考下2022-09-09
YOLOV5模型配置文件存放在modules文件夹下,这里使用的是 yolov5s.yaml,下面这篇文章主要给大家介绍了关于yolov5模型配置yaml文件的相关资料,需要的朋友可以参考下2022-09-09
Python使用BeautifulSoup爬取网页数据的操作步骤
在网络时代,数据是最宝贵的资源之一,而爬虫技术就是一种获取数据的重要手段,Python 作为一门高效、易学、易用的编程语言,自然成为了爬虫技术的首选语言之一,本文将介绍如何使用 BeautifulSoup 爬取网页数据,并提供详细的代码和注释,帮助读者快速上手2023-11-11 在本篇文章里小编给大家分享了关于python类属性的相关知识点,需要的朋友们可以参考学习下。2020-06-06
在本篇文章里小编给大家分享了关于python类属性的相关知识点,需要的朋友们可以参考学习下。2020-06-06 这篇文章主要给大家介绍了关于python学习之panda数据分析核心支持库的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-05-05
这篇文章主要给大家介绍了关于python学习之panda数据分析核心支持库的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-05-05 这篇文章主要介绍了Python中的pickle模块常用函数,pickle模块使用的数据格式是python专用的,能够把python对象直接保存到文件,而不需要转化为字符串,也不用底层的文件访问操作把它们写入到一个二进制文件中,需要的朋友可以参考下2023-09-09
这篇文章主要介绍了Python中的pickle模块常用函数,pickle模块使用的数据格式是python专用的,能够把python对象直接保存到文件,而不需要转化为字符串,也不用底层的文件访问操作把它们写入到一个二进制文件中,需要的朋友可以参考下2023-09-09 这篇文章主要介绍了Python的Urllib库的基本使用教程,是用Python编写爬虫的必备知识,需要的朋友可以参考下2015-04-04
这篇文章主要介绍了Python的Urllib库的基本使用教程,是用Python编写爬虫的必备知识,需要的朋友可以参考下2015-04-04 int(M)拆分来说,int是代表整型数据那,么中间的M应该是代表多少位了,后来查mysql手册也得知了我的理解是正确的,下面这篇文章小编就来举例详细说明。 文中介绍的很详细,相信对大家的理解和学习很有帮助,有需要的朋友们下面就来学习学习吧。2016-11-11
int(M)拆分来说,int是代表整型数据那,么中间的M应该是代表多少位了,后来查mysql手册也得知了我的理解是正确的,下面这篇文章小编就来举例详细说明。 文中介绍的很详细,相信对大家的理解和学习很有帮助,有需要的朋友们下面就来学习学习吧。2016-11-11
对python xlrd读取datetime类型数据的方法详解
今天小编就为大家分享一篇对python xlrd读取datetime类型数据的方法详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2018-12-12 今天小编就为大家分享一篇django和vue实现数据交互的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08
今天小编就为大家分享一篇django和vue实现数据交互的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2019-08-08 os 模块是 Python中的一个内置模块,也是 Python中整理文件和目录最为常用的模块。sys 模块主要负责与 Python 解释器进行交互,该模块提供了一系列用于控制 Python 运行时环境的不同部分(函数和变量等)。本文主要来聊聊这两个模块的使用,希望对大家有所帮助2023-02-02
os 模块是 Python中的一个内置模块,也是 Python中整理文件和目录最为常用的模块。sys 模块主要负责与 Python 解释器进行交互,该模块提供了一系列用于控制 Python 运行时环境的不同部分(函数和变量等)。本文主要来聊聊这两个模块的使用,希望对大家有所帮助2023-02-02










最新评论