
Python实现爬取房源信息的示例详解
前言
最近由于工作突然变动,新的办公地点离现在的住处很远,必须要换房子租了。
我坐上中介的小电驴,开始探索城市各处的陌生角落。
在各个租房app之间周转的过程中,我属实有些焦头烂额,因为效率真的很低下:
首先,因为跟女友住在一起,需要同时考虑两人的上班路程,但各平台按通勤时长找房的功能都比较鸡肋,有的平台不支持同时选择多个地点,有的平台只能机械的取到离各个地点通勤时长相同的点,满足不了使用需求。
其次,站在一个租房人的立场,租房平台实在太多了,并且各平台筛选和排序逻辑都不太一致,导致很难将相似房源的信息进行横向比较。
但是没有关系,作为一名程序员,当然要用程序员的方法来解决问题了。于是,昨晚我用一个python脚本,获取了某租房平台上海地区的所有房源信息,一共2w多条:
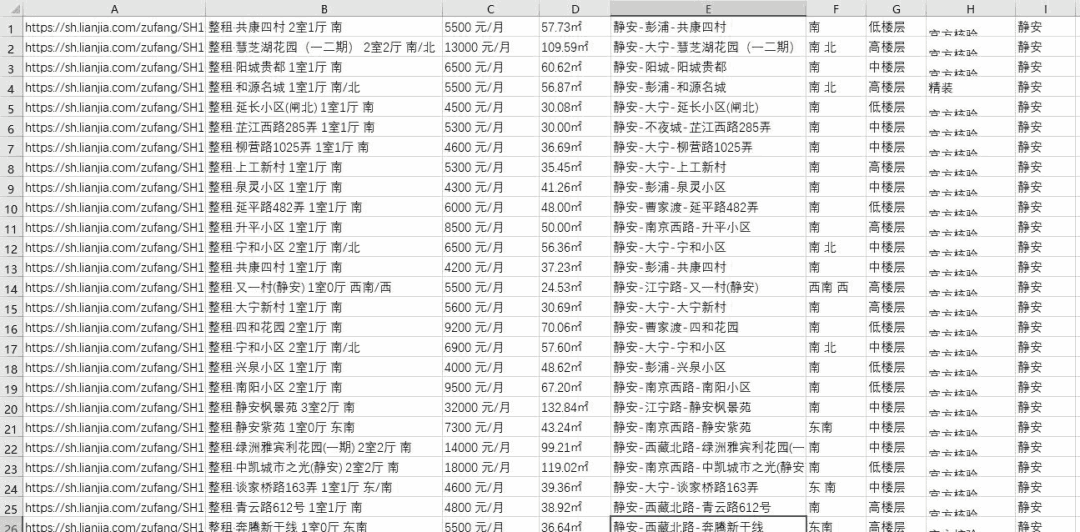
下面就把本次爬数据的整个过程分享给大家。
分析页面,寻找切入点
首先进入该平台的租房页面,可以看到,主页上的房源列表里已经包括了我们所需要的大部分信息,并且这些信息都能直接从dom中获取到,因此考虑直接通过模拟请求来收集网页数据。

因此接下来就要考虑怎么获取url了。通过观察我们发现,该地区一共有2w套以上的房源,而通过网页只能访问到前100页的数据,每页显示数量上限是30条,算下来就是一共3k条,无法获取到全部信息。

不过我们可以通过添加筛选条件来解决这个问题。在筛选项中选择“静安”,进入到如下的url:
https://sh.lianjia.com/zufang/jingan/

可以看到该地区一共有2k多套房源,数据页数为75,每页30条,理论上可以访问到所有的数据。所以可以通过分别获取各区房源数据的方法,得到该市所有的数据。
https://sh.lianjia.com/zufang/jingan/pg2/
点击第二页按钮后,进入到了上面的url,可以发现只要修改pg后面的数字,就能进入到对应的页数。
不过这里发现一个问题,相同的页数每次访问得到的数据是不一样的,这样会导致收集到的数据出现重复。所以我们点击排序条件中的“最新上架",进入到如下链接:
https://sh.lianjia.com/zufang/jingan/pg2rco11/
用这种排序方式获得的数据次序是稳定的,至此我们的思路便有了:首先分别访问每个小地区的第一页,然后通过第一页获取当前地区的最大页数,然后访问模拟请求访问每一页获取所有数据。
爬取数据
有了思路之后就要动手写代码了,首先我们要收集包含所有的链接,代码如下:
# 所有小地区对应的标识
list=['jingan','xuhui','huangpu','changning','putuo','pudong','baoshan','hongkou','yangpu','minhang','jinshan','jiading','chongming','fengxian','songjiang','qingpu']
# 存放所有链接
urls = []
for a in list:
urls.append('https://sh.lianjia.com/zufang/{}/pg1rco11/'.format(a))
# 设置请求头,避免ip被ban
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36'}
# 获取当前小地区第1页的dom信息
res = requests.get('https://sh.lianjia.com/zufang/{}/pg1rco11/'.format(a), headers=headers)
content = res.text
soup = BeautifulSoup(content, 'html.parser')
# 获取当前页面的最大页数
page_num = int(soup.find('div', attrs={'class': 'content__pg'}).attrs['data-totalpage'])
for i in range(2,page_num+1):
# 将所有链接保存到urls中
urls.append('https://sh.lianjia.com/zufang/{}/pg{}rco11/'.format(a,i))
之后,我们要逐一处理上一步得到的urls,获取链接内的数据,代码如下:
num=1
for url in urls:
print("正在处理第{}页数据...".format(str(num)))
res1 = requests.get(url, headers=headers)
content1 = res1.text
soup1 = BeautifulSoup(content1, 'html.parser')
infos = soup1.find('div', {'class': 'content__list'}).find_all('div', {'class': 'content__list--item'})
整理数据,导出文件
通过对页面结构的观察,我们能得到每个元素存储的位置,找到对应的页面元素,就能获取到我们需要的信息了。

这里附上完整的代码,感兴趣的朋友可以根据自己的需要,替换掉链接中的地区标识和小地区的标识,就能够获取到自己所在地区的信息了。其他租房平台的爬取方式大都类似,就不再赘述了。
import time, re, csv, requests
import codecs
from bs4 import BeautifulSoup
print("****处理开始****")
with open(r'..\sh.csv', 'wb+')as fp:
fp.write(codecs.BOM_UTF8)
f = open(r'..\sh.csv','w+',newline='', encoding='utf-8')
writer = csv.writer(f)
urls = []
# 所有小地区对应的标识
list=['jingan','xuhui','huangpu','changning','putuo','pudong','baoshan','hongkou','yangpu','minhang','jinshan','jiading','chongming','fengxian','songjiang','qingpu']
# 存放所有链接
urls = []
for a in list:
urls.append('https://sh.lianjia.com/zufang/{}/pg1rco11/'.format(a))
# 设置请求头,避免ip被ban
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36'}
# 获取当前小地区第1页的dom信息
res = requests.get('https://sh.lianjia.com/zufang/{}/pg1rco11/'.format(a), headers=headers)
content = res.text
soup = BeautifulSoup(content, 'html.parser')
# 获取当前页面的最大页数
page_num = int(soup.find('div', attrs={'class': 'content__pg'}).attrs['data-totalpage'])
for i in range(2,page_num+1):
# 将所有链接保存到urls中
urls.append('https://sh.lianjia.com/zufang/{}/pg{}rco11/'.format(a,i))
num=1
for url in urls:
# 模拟请求
print("正在处理第{}页数据...".format(str(num)))
res1 = requests.get(url, headers=headers)
content1 = res1.text
soup1 = BeautifulSoup(content1, 'html.parser')
# 读取页面中数据
infos = soup1.find('div', {'class': 'content__list'}).find_all('div', {'class': 'content__list--item'})
# 数据处理
for info in infos:
house_url = 'https://sh.lianjia.com' + info.a['href']
title = info.find('p', {'class': 'content__list--item--title'}).find('a').get_text().strip()
group = title.split()[0][3:]
price = info.find('span', {'class': 'content__list--item-price'}).get_text()
tag = info.find('p', {'class': 'content__list--item--bottom oneline'}).get_text()
mixed = info.find('p', {'class': 'content__list--item--des'}).get_text()
mix = re.split(r'/', mixed)
address = mix[0].strip()
area = mix[1].strip()
door_orientation = mix[2].strip()
style = mix[-1].strip()
region = re.split(r'-', address)[0]
writer.writerow((house_url, title, group, price, area, address, door_orientation, style, tag, region))
time.sleep(0)
print("第{}页数据处理完毕,共{}条数据。".format(str(num), len(infos)))
num+=1
f.close()
print("****全部完成****")
经过一番操作,我们获取到了当地各租房平台完整的房源信息。至此,我们已经可以通过一些基本的筛选方式,获取自己需要的数据了。
到此这篇关于Python实现爬取房源信息的示例详解的文章就介绍到这了,更多相关Python爬取房源信息内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 python中有一个非常有用的语法叫做生成器,所利用到的关键字就是yield。接下来脚本之家小编给大家带来了Python中的yield关键字详细解析,感兴趣的朋友参考下吧2018-01-01
python中有一个非常有用的语法叫做生成器,所利用到的关键字就是yield。接下来脚本之家小编给大家带来了Python中的yield关键字详细解析,感兴趣的朋友参考下吧2018-01-01 imap-tools模块是python的第三方扩展, 它使用标准库imaplib,并将常见的邮件处理事件封装,邮件处理起来代码短,下面给大家介绍下python使用imap-tools模块下载邮件中的附件示例代码,感兴趣的朋友一起看看吧2021-12-12
imap-tools模块是python的第三方扩展, 它使用标准库imaplib,并将常见的邮件处理事件封装,邮件处理起来代码短,下面给大家介绍下python使用imap-tools模块下载邮件中的附件示例代码,感兴趣的朋友一起看看吧2021-12-12 这篇文章主要介绍了python 判断是否为正小数和正整数的实例的相关资料,这里提供实例,实例注释说明很清楚,需要的朋友可以参考下2017-07-07
这篇文章主要介绍了python 判断是否为正小数和正整数的实例的相关资料,这里提供实例,实例注释说明很清楚,需要的朋友可以参考下2017-07-07 这篇文章主要介绍了python批量生成本地ip地址的方法,实例分析了Python实现生成本地IP地址并绑定到网卡上的技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-03-03
这篇文章主要介绍了python批量生成本地ip地址的方法,实例分析了Python实现生成本地IP地址并绑定到网卡上的技巧,具有一定参考借鉴价值,需要的朋友可以参考下2015-03-03 这篇文章主要介绍了OpenCV制作图像Mask,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-09-09
这篇文章主要介绍了OpenCV制作图像Mask,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-09-09
Python多线程操作之互斥锁、递归锁、信号量、事件实例详解
这篇文章主要介绍了Python多线程操作之互斥锁、递归锁、信号量、事件,结合实例形式详细分析了Python多线程操作互斥锁、递归锁、信号量、事件相关概念、原理、用法与操作注意事项,需要的朋友可以参考下2020-03-03 这篇文章主要介绍了python 实现ping测试延迟的两种方法,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-12-12
这篇文章主要介绍了python 实现ping测试延迟的两种方法,帮助大家更好的理解和使用python,感兴趣的朋友可以了解下2020-12-12 这篇文章主要介绍了利用pygame完成动画精灵和碰撞检测,代码详细,内容丰富,对于想要学习pygame的朋友来讲是一个不错的练习,需要的朋友可以参考下2023-01-01
这篇文章主要介绍了利用pygame完成动画精灵和碰撞检测,代码详细,内容丰富,对于想要学习pygame的朋友来讲是一个不错的练习,需要的朋友可以参考下2023-01-01 这篇文章主要介绍了基于Python词云分析政府工作报告关键词,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06
这篇文章主要介绍了基于Python词云分析政府工作报告关键词,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-06-06 这篇文章主要给大家介绍了关于如何利用Python批量处理多个txt文本的方法,文中通过实例代码介绍的非常详细,对大家的学习或工作有一定的帮助,需要的朋友可以参考下2023-10-10
这篇文章主要给大家介绍了关于如何利用Python批量处理多个txt文本的方法,文中通过实例代码介绍的非常详细,对大家的学习或工作有一定的帮助,需要的朋友可以参考下2023-10-10










最新评论