
MySQL order by与group by查询优化实现详解
前言
order by满足两种情况,会使用 index 方式排序:
- order by语句使用索引最左前列(最左匹配法则)
- where子句和order by子句条件列组合满足最左匹配法则(where条件使用索引的最左前缀为常量)
下面给出几个实例来说明,如下所示我们创建表并为其创建组合索引(c1,c2,c3)。
CREATE TABLE `testc` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `c1` varchar(100) DEFAULT NULL, `c2` varchar(100) DEFAULT NULL, `c3` varchar(100) DEFAULT NULL, `c4` varchar(100) DEFAULT NULL, `c5` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), KEY `testc_c1_IDX` (`c1`,`c2`,`c3`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
where与order by满足最左匹配法则
# c1 c2满足最左匹配法则 explain select * from testc where c1='a1' order by c2 # 与上面等价 explain select * from testc where c1='a1' order by c2,c3

key_len标明查找用到了索引 c1,Extra中是Using index condition 没有同时出现using where ,表明 c2 索引用来读取数据而非执行查找动作。
MySQL Innodb下的B+树本身就是多路平衡树,那么索引换句话就是排好序的快速查找数据结构。如果order by用到了索引且排序和索引次序一样,那么无疑效果是最好的。
中间断裂
如下所示,缺少了c2,order by不满足最左匹配法则。
explain select * from testc where c1='a1' order by c3
可以看到Extra中Using index condition; Using filesort说明虽然where可以用到索引(单独c1满足最左匹配),但是排序不满足,故而出现了filesort。

大哥不在
如下c1不在,那么很显然无论查找还是排序都用不到索引。
explain select * from testc where c2='a2' order by c3
这里Extra是Using where; Using filesort,说明通过where子句过滤结果,然后对结果进行文件排序。

范围失效
如下所示,中间c2是个范围搜索,那么其后索引将失效也就是order by c3无法与where连接满足最左匹配法则。
explain select * from testc where c1='a1' and c2 > 'a2' order by c3
如下图所示,这里type = range,ken_len表示用到了 c1,c2索引。Extra是Using index condition; Using filesort表示查询用到了索引但是无法利用索引完成的排序操作。

这种情况如何优化呢?order by c2,c3!这样就可以保证索引排序而不需要filesort。
explain select * from agriculture.testc where c1='a1' and c2 > 'a2' order by c2,c3

order by 次序相反
如下所示,order by的次序没有与索引次序保持一致。这里Extra为Using index condition; Using filesort。
explain select * from testc where c1='a1' order by c3,c2

覆盖索引
前面几个都是select *,这里查找索引列。
没有where,order by满足全值匹配,select查询的数据是索引列。
explain select c1 from testc order by c1, c2,c3
这里Extra中只有Using index;

没有where,order by 大哥丢失,select查询的数据是索引列。
explain select c1 from testc order by c2,c3
这里Extra中是Using index; Using filesort 。

这里Extra信息为Using where; Using index; Using filesort。
explain select c1 from testc where c1='a1' order by c3,c2

filesort的两种算法
filesort有两种机制:双路排序和单路排序。双路排序简单来讲就是两次扫描磁盘,最终得到数据。单路排序则是只需要读取一次,也就是一次磁盘IO。
双路排序
MySQL4.1之前是使用双路排序,读取行指针和order by列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出(可以理解为从磁盘读取排序字段,在buffer进行排序,然后再从磁盘读取其他字段)。
取一批数据要进行两次磁盘IO,这是很耗时的。故而在MySQL4.1之后,出现了第二种改进的算法,也就是单路排序。
单路排序
从磁盘读取查询需要的所有列,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输出。它的效率更快一点,避免了第二次读取数据,并且把随机IO变成了顺序IO。但是其会使用更多的空间,因为其缓存了数据在内存中。
单路的问题
可能取出的数据大小超过了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小…从而多次IO(可能比双路更多)。
可以尝试增大sort_buffer_size参数的设置或者max_length_for_sort_data参数的设置。
总结
order by时select * 是一个大忌,应该是查询需要的字段。
当query的字段大小总和小于max_length_for_sort_data而且排序字段不是text|blob类型时,会用改进后的算法–单路排序,否则使用双路排序。
两种算法的数据都有可能超出sort_buffer的容量,超出之后会创建tmp文件进行合并排序导致多次IO。尤其对于单路排序来说风险更大,所以需要适当调整sort_buffer的容量。
提高max_length_for_sort_data会增加使用单路排序算法的概率。但是如果设置的太高,数据总容量超过sort_buffer的概率就增大,明显症状是磁盘IO高,CPU使用率低。
group by
前面提到的规则针对group by均适用,group by 实质是先排序后分组,遵照索引建的最佳左前缀。当无法使用索引时,增大max_length_for_sort_data和sort_buffer参数的值。
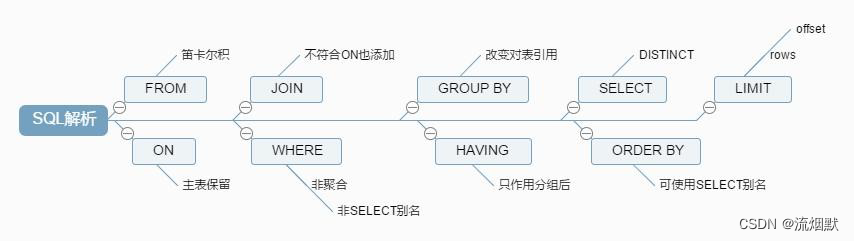
需要注意的是where优先级高于having,能写在where限定的条件尽量不要通过having。
到此这篇关于MySQL order by与group by查询优化实现详解的文章就介绍到这了,更多相关MySQL order by与group by内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

MySQL 5.7增强版Semisync Replication性能优化
这篇文章主要介绍了MySQL 5.7增强版Semisync Replication性能优化,本文着重讲解支持发送binlog和接受ack的异步化、支持在事务commit前等待ACK两项内容,需要的朋友可以参考下2015-05-05 今天想提到的是线上一个4G的RDS实例,发生了OOM(out of memory)的问题,MySQL进程被直接Kill掉了。在解释这个问题的时候,我们首先需要从Linux系统内存分配策略讲起2016-07-07
今天想提到的是线上一个4G的RDS实例,发生了OOM(out of memory)的问题,MySQL进程被直接Kill掉了。在解释这个问题的时候,我们首先需要从Linux系统内存分配策略讲起2016-07-07 这篇文章主要介绍了mysql索引基数概念与用法,结合实例形式分析了mysql索引基数的相关概念、原理、操作命令及相关使用技巧,需要的朋友可以参考下2019-03-03
这篇文章主要介绍了mysql索引基数概念与用法,结合实例形式分析了mysql索引基数的相关概念、原理、操作命令及相关使用技巧,需要的朋友可以参考下2019-03-03 这篇文章主要给大家介绍了关于MySQL中表的几种连接方式,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-11-11
这篇文章主要给大家介绍了关于MySQL中表的几种连接方式,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2020-11-11 在 MySQL 中,默认情况下表名是大小写敏感的,本文主要介绍了MySQL忽略表名大小写的2种方法实现,具有一定的参考价值,感兴趣的可以了解一下2024-03-03
在 MySQL 中,默认情况下表名是大小写敏感的,本文主要介绍了MySQL忽略表名大小写的2种方法实现,具有一定的参考价值,感兴趣的可以了解一下2024-03-03 写程序的人往往需要分析所写的SQL语句是否已经优化过了,服务器的响应时间有多快,所以下面这篇文章主要给大家介绍了关于Mysql中如何查看Sql语句的执行时间的相关资料,需要的朋友可以参考下2021-12-12
写程序的人往往需要分析所写的SQL语句是否已经优化过了,服务器的响应时间有多快,所以下面这篇文章主要给大家介绍了关于Mysql中如何查看Sql语句的执行时间的相关资料,需要的朋友可以参考下2021-12-12 MySQL Workbench提供DBAs和developers一个集成工具环境,方便管理mysql数据库,这里简单介绍下MySQL Workbench使用方法,需要的朋友可以参考下2014-03-03
MySQL Workbench提供DBAs和developers一个集成工具环境,方便管理mysql数据库,这里简单介绍下MySQL Workbench使用方法,需要的朋友可以参考下2014-03-03 这篇文章主要给大家介绍了关于MySQL中":="和"="区别的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用MySQL具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-08-08
这篇文章主要给大家介绍了关于MySQL中":="和"="区别的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用MySQL具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧2019-08-08 之前安装过MYSQL好像不用手动启动服务,具体也忘记了,但我上回给公司安装的那个是要手动安装服务的,如果mysql刚刚安装不能用,可能是服务没有安装2014-03-03
之前安装过MYSQL好像不用手动启动服务,具体也忘记了,但我上回给公司安装的那个是要手动安装服务的,如果mysql刚刚安装不能用,可能是服务没有安装2014-03-03 这篇文章主要介绍了如何修改Linux服务器中的MySQL数据库密码问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-06-06
这篇文章主要介绍了如何修改Linux服务器中的MySQL数据库密码问题,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-06-06










最新评论