
python读取eml文件并用正则表达式匹配邮箱的代码
今天接到一个需求有一个同事离职了,但是留下了非常多(2W多封)的邮件,我需要将他的邮件进行分类,只要邮件中以@xxx.com结尾的存放在文件夹中(下图名叫【是】的文件夹),否则放在另一个文件夹中(下图名叫【否】的文件夹)。 目录结构
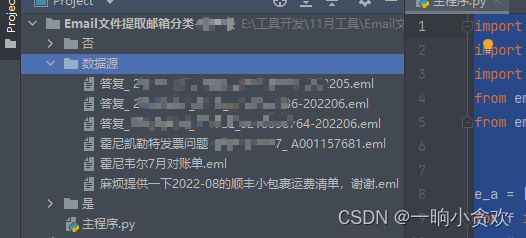
代码注意事项
import email(我发现是内置模块,不用安装) 下面是注意事项(就当是注释吧!!!!) 1、提取包含一下后缀的邮箱,我用了split(“@”),所以不用写 @e_a = [‘Honeywell.com’, ‘honeywell.com’, ‘garrettmotion.com’, ‘HONEYWELL.COM’, ‘resideo.com’]
2、提取,收件人、发件人、抄送人的邮箱(这个是可以不写的,但是我这个代码是借鉴的,没找到提取全部内容的函数,只找到提取内容的函数,所以加上了下面的代码)fjr = email.utils.parseaddr(msg.get(“from”))[1]
3、将eml文件内容与收件人、发件人、抄送人拼接,并且加 " " 间隔,不加会有些小问题
sjr = email.utils.parseaddr(msg.get(‘to’))[1]
csr = email.utils.parseaddr(msg.get(‘cc’))[1]
print(“发件人”, fjr)
print(“收件人”, sjr)
print(“抄送人”, csr)text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
4、正则匹配邮箱prog = re.compile(r’[a-zA-Z0-9_.±]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+')
5、移动文件 os.remove()
res = prog.findall(text)
完整代码
import email
import os
import re
from email import policy
from email.parser import BytesParser
e_a = ['Honeywell.com', 'honeywell.com', 'garrettmotion.com', 'HONEYWELL.COM', 'resideo.com']
for f in os.listdir("./数据源/"):
# print(f)
text = ""
with open("./数据源/" + f, 'rb') as fp:
msg = BytesParser(policy=policy.default).parse(fp)
fjr = email.utils.parseaddr(msg.get("from"))[1]
sjr = email.utils.parseaddr(msg.get('to'))[1]
csr = email.utils.parseaddr(msg.get('cc'))[1]
print("发件人", fjr)
print("收件人", sjr)
print("抄送人", csr)
if msg.get_body(preferencelist=('plain'))==None:
text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
else:
text = msg.get_body(preferencelist=('plain')).get_content()
text = text + " " + fjr + " " + " " + " " + " " + sjr + " " + " " + csr
# print(text)
prog = re.compile(r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+')
res = prog.findall(text)
for e in res:
res1 = e.split("@")[1]
if res1 in e_a:
print(f, "在")
ori = "./数据源/" + f
now = "./是/" + f
os.rename(ori, now)
break
else:
ori = "./数据源/" + f
now = "./否/" + f
os.rename(ori, now)
print(f, "不在")下面看看python正则表达式匹配邮箱
下面来看看python验证邮箱模式的例子。
(首先还是把环境列出来)
环境:python 2.7.10
1. 一次匹配多个邮箱的情况
下面的例子中:邮箱中可以出现 数字、大小写字母、下划线、和横线(-)
# -*- coding:utf-8 -*-
# 邮箱格式-正则表达式匹配
import re
# 一次匹配多个邮箱
str1 = 'aaf ssa@ss.net asdf asdb@163.com.cn asdf ss-a@ss.net asdf asdd.cba@163.com afdsaf'
reg_str1 = r'([\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+)'
mod = re.compile(reg_str1)
items = mod.findall(str1)
for item in items:
print item结果输出:

2. 一次匹配一个
这种情况,常见在登录界面用户名为邮箱时, 此时一个字符串只有一个 邮箱
# 只匹配一个
str2 = 'ssa_a-c@ss.net.cn'
reg_str2 = r'(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)'
mod = re.compile(reg_str2)
items = mod.findall(str2)
for item in items:
print item结果输出:
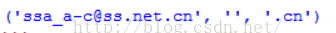
到此这篇关于python读取eml文件并用正则匹配邮箱的文章就介绍到这了,更多相关python读取eml文件内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

使用numpngw和matplotlib生成png动画的示例代码
这篇文章主要介绍了使用numpngw和matplotlib生成png动画的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2021-01-01 在本篇文章里小编给大家分享了关于python打开文件的方式,需要的朋友们可以学习参考下。2020-06-06
在本篇文章里小编给大家分享了关于python打开文件的方式,需要的朋友们可以学习参考下。2020-06-06 这篇文章主要给大家详细介绍了python中子类如何继承父类的__init__方法,文中给出了详细的示例代码,相信对大家的理解和学习具有一定参考价值,有需要的朋友们下面来跟着小编一起学习学习吧。2016-12-12
这篇文章主要给大家详细介绍了python中子类如何继承父类的__init__方法,文中给出了详细的示例代码,相信对大家的理解和学习具有一定参考价值,有需要的朋友们下面来跟着小编一起学习学习吧。2016-12-12 在本篇文章里小编给大家分享的是一篇关于Flask中jinja2的继承实现方法及实例,有兴趣的朋友们可以学习下。2021-03-03
在本篇文章里小编给大家分享的是一篇关于Flask中jinja2的继承实现方法及实例,有兴趣的朋友们可以学习下。2021-03-03 图像增广算法在计算机视觉领域扮演着至关重要的角色,本文将着重介绍图像增广算法中的三个关键方面:图像旋转、图像亮度调整以及图像裁剪与拼接,感兴趣的可以了解一下2023-05-05
图像增广算法在计算机视觉领域扮演着至关重要的角色,本文将着重介绍图像增广算法中的三个关键方面:图像旋转、图像亮度调整以及图像裁剪与拼接,感兴趣的可以了解一下2023-05-05
python通过socket实现多个连接并实现ssh功能详解
这篇文章主要介绍了python通过socket实现多个连接并实现ssh功能详解,具有一定参考价值,需要的朋友可以了解下。2017-11-11 这篇文章主要介绍了PyTorch中Tensor的维度变换实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-08-08
这篇文章主要介绍了PyTorch中Tensor的维度变换实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2019-08-08 这篇文章主要介绍了python机器学习darts时间序列预测和分析使用实例探索,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-01-01
这篇文章主要介绍了python机器学习darts时间序列预测和分析使用实例探索,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2024-01-01 这篇文章主要介绍了python3.x中提取中文的正则表达式的书写,需要的朋友可以参考下2019-07-07
这篇文章主要介绍了python3.x中提取中文的正则表达式的书写,需要的朋友可以参考下2019-07-07 这篇文章主要介绍了python 矢量数据转栅格数据代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09
这篇文章主要介绍了python 矢量数据转栅格数据代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2019-09-09










最新评论