
Kotlin coroutineContext源码层深入分析
1.CoroutineContext
表示一个元素或者是元素集合的接口。它有一个Key(索引)的Element实例集合,每一个Element的实例也是一个CoroutineContext,即集合中每个元素也是集合。
如下图所示,CoroutineContext的常见官方实现有以下几种(少见的或者自定义的实现就不列举,以后再聊):
- Job:协程实例,控制协程生命周期(new、acruve、completing、conpleted、cancelling、cancelled)。
- CoroutineDIspatcher:协程调度器,给指定线程分发协程任务(IO、Default、Main、Unconfined)。
- CoroutineName:协程名称,用于定义协程的名称,调试打印信息使用。
- CoroutineExceptionHandler:协程异常处理器,用于处理未捕获的异常。

2.Element的作用
Element类也是继承自CoroutineContext接口的,该类的作用是给子类保留一个Key成员变量,用于在集合查询的时候可以快速查找到目标coroutineContext,Key成员变量是一个泛型变量,每个继承自Element的子类都会去覆盖实现Key成员变量(一般是使用子类自己去覆盖Key),就比如拿最简单的CoroutineName类来举例子:
public data class CoroutineName(
/**
* User-defined coroutine name.
*/
val name: String
) : AbstractCoroutineContextElement(CoroutineName) {
/**
* Key for [CoroutineName] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<CoroutineName>
/**
* Returns a string representation of the object.
*/
override fun toString(): String = "CoroutineName($name)"
}
@SinceKotlin("1.3")
public abstract class AbstractCoroutineContextElement(public override val key: Key<*>) : Element
/**
* Key for the elements of [CoroutineContext]. [E] is a type of element with this key.
*/
public interface Key<E : Element>
/**
* An element of the [CoroutineContext]. An element of the coroutine context is a singleton context by itself.
*/
public interface Element : CoroutineContext {
/**
* A key of this coroutine context element.
*/
public val key: Key<*>
public override operator fun <E : Element> get(key: Key<E>): E? =
@Suppress("UNCHECKED_CAST")
if (this.key == key) this as E else null
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(initial, this)
public override fun minusKey(key: Key<*>): CoroutineContext =
if (this.key == key) EmptyCoroutineContext else this
}上面的CoroutineName构造函数定义为
public data class CoroutineName(
/**
* User-defined coroutine name.
*/
val name: String
) : AbstractCoroutineContextElement(CoroutineName)
父类构造函数中传递的参数是CoroutineName,但是我们发现CoroutineName也不是Key接口public interface Key<E : Element>的实现,为啥可以这样直接传递呢?但是我们仔细看发现CoroutineName类定义了伴生对象: public companion object Key : CoroutineContext.Key<CoroutineName>,在kotlin中伴生对象是可以直接省略 类.companion.调用方式的,CoroutineName类也就代表着伴生对象,所以可以直接作为CoroutineName父类构造函数的参数,神奇的kotlin语法搞得我一愣一愣的。
类似的还有Job,CoroutineDIspatcher,CoroutineExceptionHandler的成员变量Key的覆盖实现:
//Job
public interface Job : CoroutineContext.Element {
/**
* Key for [Job] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<Job> { //省略 }
//省略
}
//CoroutineExceptionHandler
public interface CoroutineExceptionHandler : CoroutineContext.Element {
/**
* Key for [CoroutineExceptionHandler] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<CoroutineExceptionHandler>
//省略
}
// CoroutineDIspatcher
@SinceKotlin("1.3")
public interface ContinuationInterceptor : CoroutineContext.Element {
/**
* The key that defines *the* context interceptor.
*/
companion object Key : CoroutineContext.Key<ContinuationInterceptor>
}3.CoroutineContext相关的操作符原理解析
CoroutineContext的操作符??有点莫名其妙的感觉,仅仅凭借我的直觉的话很难理解,但是平常使用协程的过程中,我们经常会使用这些相关的操作符,比如 +,[]等等符号,下面代码示例:
val comb = Job() + CoroutineName("")
val cName = comb[CoroutineName]
上面的+代表两个coroutineContext合并到集合中,这里的集合实际上是一个链表,后面会讲到。
上面的[]代表着从集合中索引出CoroutineName类型的CoroutineContext,这里也可以看出来仅仅通过key就查找出元素和map很相似,那么可以知道value是唯一的。key都是coroutineContext子类作为泛型类型的,具有唯一性,那也可以间接推断出上面+操作其实也会覆盖拥有相同key的value的值。
还有其他操作函数:fold展开操作, minusKey删除集合中存在的元素。
还有一个问题就是,这个集合到底是什么类型的集合,已经如何管理的,我们来一一解答:
3.1.什么类型的集合
CoroutineConetxt集合是链表结构的集合,是一个从本节点开始,向左遍历parent节点的一个链表,节点的都是CoroutineContext的子类,分为Element,CombinedContext,EmptyCoroutineContext三种。
有以下代码作为举例:
val scope = CoroutineScope(CoroutineName("") + Job() + CoroutineExceptionHandler{<!--{C}%3C!%2D%2D%20%2D%2D%3E--> _, _ -> } + Dispatchers.Default)假如CoroutineScope自己的coroutineContext变量集合中是包含CoroutineName,Job,CoroutineExceptionHanlder,CoroutineDIspatcher四种上下文的,那么他们组成的集合结构可能就会是下图所示的链表结构,

使用scope查找对应的Job的话直接调用scope[Job]方法,替代Job的话调用 scope + Job(),看源码就是使用scope的上下文集合替换Job
public operator fun CoroutineScope.plus(context: CoroutineContext): CoroutineScope =
ContextScope(coroutineContext + context)
为啥是链表结构的集合呢,接下来直接看源码就知道了。
3.2.如何管理
我们集合的链表结构,每个节点都是CombinedContext类型,里面包含了element,left两个成员变量,left指向链表的左边,element表示当前节点的上下文元素(一般是job,name,handler,dispatcher四种),链表的最左端节点一定是Element元素
Element
主要实现在combinedContext,Element元素的方法实现比较简单,不单独列举。
combinedContext
构造函数
@SinceKotlin("1.3")
internal class CombinedContext(
private val left: CoroutineContext,
private val element: Element
) : CoroutineContext, Serializable {
get函数:
//Element
public override operator fun <E : Element> get(key: Key<E>): E? =
@Suppress("UNCHECKED_CAST")
if (this.key == key) this as E else null
//CombinedContext
override fun <E : Element> get(key: Key<E>): E? {
var cur = this
while (true) {
cur.element[key]?.let { return it }
val next = cur.left
if (next is CombinedContext) {
cur = next
} else {
return next[key]
}
}
}在代码中一般不会使用get方法,而是使用context[key]来代替,类似于map集合的查询。上下文是Element类型,key是对应类型那么返回当前Element,不是当前类型,返回null;上下文是CombinedContext类型,指针cur指向当前节点,while循环开始,当前的element元素的key查找到了,那么就返回当前combinedContext,如果没找到,那么将指针指向left节点,如果left节点是combinedContext类型,那么重复上述操作,如果是Element类型直接判断是否可以查找到key值。那么从这里看出链表的最左端元素一定是Element节点。
contain函数
private fun contains(element: Element): Boolean =
get(element.key) == element
private fun containsAll(context: CombinedContext): Boolean {
var cur = context
while (true) {
if (!contains(cur.element)) return false
val next = cur.left
if (next is CombinedContext) {
cur = next
} else {
return contains(next as Element)
}
}
}类似于get操作,contains函数直接调用get方法来判断元素是不是和传入参数相等。
containAll函数就是遍历参数的链表节点是不是都包含在当前链表中。
fold函数
//coroutineContext
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
从表面意思就是展开操作,第一个入参 CoroutineContext,第二个入参 lambda表达式 用表达式的两个参数CoroutineContext, Element 返回一个新的 CoroutineContext:
operation :(R , Element) -> R
Job.fold(CoroutineName("测试"),{ coroutineContext , element ->
TODO("return new CoroutineContext")
}) //example
//Element
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(initial, this)
作为receiver的上下文是Element,调用fold的话,是让ELement和入参的CoroutineContext作为lambda表达式 的两个参数调用该lambda表达式返回结果。
MainScope().coroutineContext.fold(Job(),{ coroutineContext , element ->
TODO("return new CoroutineContext")
}) //example
//CombinedContext
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(left.fold(initial, operation), element)
作为receiver的上下文是CombinedContext,调用fold的话,是让left深度递归调用fold函数,一直到链表的最左端节点,我们知道链表的最左端节点一定是Element,那么根据上面的代码,Element的fold函数内调用operation返回一个CoroutineContext后,递归回溯到上一层,继续调用operation返回一个CoroutineContext,继续回溯,一直回溯到开始调用MainScope().coroutineContext.fold(Job的地方。如下图所示:

minusKey函数
该函数的意思是从上下文集合中删除key对应的上下文。
//Element
public override fun minusKey(key: Key<*>): CoroutineContext =
if (this.key == key) EmptyCoroutineContext else this
接收者receiver是Element类型的话,如果入参key和receiver是相等的话,那么返回EmptyCoroutineContext空上下文,否则返回receiver本身。(可见找到得到key的话会返回空上下文,找不到的话返回本身)
//CombinedContext
public override fun minusKey(key: Key<*>): CoroutineContext {
element[key]?.let { return left }
val newLeft = left.minusKey(key)
return when {
newLeft === left -> this
newLeft === EmptyCoroutineContext -> element
else -> CombinedContext(newLeft, element)
}
}
接收者receiver是CombinedContext类型的话,
- element[key]不为空说明当前节点就是要找的节点,直接返回该节点的left节点(代表着把当前节点跳过,也就是移除该节点)。
- element[key]为空那么说明当前节点不是要找的节点,需要向链表的左端left去寻找目标,深度递归遍历
left.minusKey(key),返回的newLeft有三种情况: - newLeft === left,在左边找不到目标Key(根据Element.minusKey函数发现,返回的是this的话就是key没有匹配到),从该节点到左端节点都可以返回。
- newLeft === EmptyCoroutineContext ,在左边找到了目标key(根据Element.minusKey函数发现,返回的是EmptyCoroutineContext 的话key匹配到了Element),找到了目标那么需要将目标跳过,那么从本节点开始返回,左边节点需要跳过移除,该节点就成了链表的最左端节点Element。
- 不是上述的情况,那么就是newLeft是触发了1.或者4.情况,返回的是left的element元素,或者是本节点的left节点跳过了,返回的是left.left节点,这样将newLeft和本节点的element构造出新的CombinedContext节点。
上述操作,都只是在链表上跳过节点,然后将跳过的节点左节点left和右节点创建新的CombinedContext,产生一个新的链表出来。
操作例子:
删除最左端节点

删除中间节点:

结论:minusKey的操作只是将原始链表集合中排除某一个节点,然后复制一个链表返回,所以并不会影响原始集合
plus函数
该函数重写+操作符,函数定义operator fun plus(context: CoroutineContext): CoroutineContext ,作用是对上下文集合进行添加(相同会覆盖)指定上下文操作。这个函数只有CoroutineContext实现了,代码如下:
/**
* Returns a context containing elements from this context and elements from other [context].
* The elements from this context with the same key as in the other one are dropped.
*/
public operator fun plus(context: CoroutineContext): CoroutineContext =
if (context === EmptyCoroutineContext) this else // fast path -- avoid lambda creation
context.fold(this) { acc, element ->
val removed = acc.minusKey(element.key)
if (removed === EmptyCoroutineContext) element else {
// make sure interceptor is always last in the context (and thus is fast to get when present)
val interceptor = removed[ContinuationInterceptor]
if (interceptor == null) CombinedContext(removed, element) else {
val left = removed.minusKey(ContinuationInterceptor)
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}入参如果是EmptyContext,那么直接返回;不是空的话,对入参进行fold操作,上面讲了fold操作是将context链表展开,从链表最左端开始向context回溯调用fold函数的入参lambda表达式。那么我们就知道了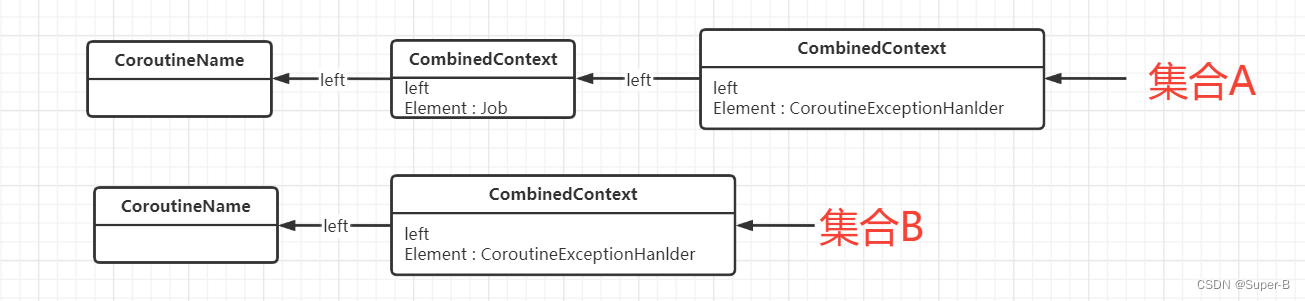 是如何操作的了,首先B作为plus的入参,那么B先展开到B链表结构的最左端,然后执行lambda操作{ acc, element -> ... }, 这个lambda里面
第一步
context.fold(this) { acc, element ->
acc.minusKey(Element.Key)
// ...
}
//CombineContext的实现
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(left.fold(initial, operation), element)根据CombineContext的实现,知道lambda的acc参数是A (CombineContext),element参数是B(CombineContext)的fold递归的当前位置的element的元素,acc.minusKey(Element.Key)所做的事情就是移除A (CombineContext)链表中的B(CombineContext)的element元素。
第二步
if (removed === EmptyCoroutineContext) element else {
// make sure interceptor is always last in the context (and thus is fast to get when present)
val interceptor = removed[ContinuationInterceptor]
// ...
}
第一步移除掉element之后,判断剩余的removed链表是不是empty的,如果为空,返回B(CombineContext)的fold递归位置的element元素;不为空,接着从removed链表中获取ContinuationInterceptor上下文(也就是dispatcher)。
第三步
if (interceptor == null) CombinedContext(removed, element) else {
val left = removed.minusKey(ContinuationInterceptor)
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
CombinedContext(CombinedContext(left, element), interceptor)
}
获取的interceptor为空,那将element和removed链表构造出一个新的CombinedContext节点返回;如果不为空,从removed链表中移除interceptor返回一个不包含interceptor的链表left;移除后left链表为空,那么将element和interceptor构造出一个新的CombinedContext节点返回;left链表不为空,那么将left, element构造出一个新的CombinedContext节点,将新的CombinedContext节点和interceptor早构造出一个新的节点返回。
每一层递归fold操作结束后,返回一个新的context给上一层继续递归,直到结束为止。
操作例子图如下:
有如下两个集合A (CombineContext) + B(CombineContext):

第一次递归回溯:

第二次递归回溯:

回溯深度取决于入参B的链表长度,B有多长回溯就会发生几次,这里没有加入interceptor上下文元素,减少画图复杂度。
plus操作结论:
1.发现每次返回节点的时候,都会将interceptor移除后,放到节点的最右边的位置,可以知道interceptor一定在链表的头部;
2.lambda表达式中,一定会先移除掉相同key的上下文元素,然后用后加入的element和left链表新建一个CombinedContext节点插入到头部
3.plus操作会覆盖掉有相同key的上下文元素
4.验证以及总结
经过对上面的源码的分析,可以推断出一些上下文元素的操作符操作后,集合的元素排列状态。比如下面操作:
private fun test() {
val coroutineContext = Job() + CoroutineName("name1") + Dispatchers.IO + CoroutineExceptionHandler{ c,e -> }
Log.i(TAG, "coroutineContext $coroutineContext")
val newContext = coroutineContext + SupervisorJob()
Log.i(TAG, "newContext $newContext")
val newContext2 = newContext + (Job() + CoroutineName("name2"))
Log.i(TAG, "newContext2 $newContext2")
Log.i(TAG, "newContext2[CoroutineName] ${newContext2[CoroutineName]}")
}打印的日志如下:
I/MainActivity: coroutineContext [
JobImpl{Active}@b32c44,
CoroutineName(name1),
com.meeting.kotlinapplication.MainActivity$test$$inlined$CoroutineExceptionHandler$1@45ec12d,
Dispatchers.IO
]I/MainActivity: newContext [
CoroutineName(name1),
com.meeting.kotlinapplication.MainActivity$test$$inlined$CoroutineExceptionHandler$1@45ec12d,
SupervisorJobImpl{Active}@1022662,
Dispatchers.IO
]
I/MainActivity: newContext2 [
com.meeting.kotlinapplication.MainActivity$test$$inlined$CoroutineExceptionHandler$1@45ec12d,
JobImpl{Active}@76863f3,
CoroutineName(name2),
Dispatchers.IO
]I/MainActivity: newContext2[CoroutineName] CoroutineName(name2)
I/MainActivity: coroutineContext [
JobImpl{Active}@b32c44,
CoroutineName(name1),
com.meeting.kotlinapplication.MainActivity$test$$inlined$CoroutineExceptionHandler$1@45ec12d,
Dispatchers.IO
]
可以看出来:
1. Dispatchers元素一定是在链表的头部;
2. 重复key的元素会被后加入的元素覆盖,集合中不存在重复key的元素;
3. +操作后返回新的链表集合,不会影响原始集合链表结构
上面总结的这些性质,可以很好的为job协程的父子关系,子job继承父job的上下文集合这些特性,下一篇我将讲解 协程Job父子关系的原理。
到此这篇关于Kotlin coroutineContext源码层深入分析的文章就介绍到这了,更多相关Kotlin coroutineContext内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了Android TextView字体颜色设置方法,结合实例形式总结分析了Android开发中TextView设置字体颜色的常用技巧,需要的朋友可以参考下2016-02-02
这篇文章主要介绍了Android TextView字体颜色设置方法,结合实例形式总结分析了Android开发中TextView设置字体颜色的常用技巧,需要的朋友可以参考下2016-02-02 本文通过实例代码给大家介绍了Android自定义dialog 自下往上弹出效果,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友参考下吧2018-08-08
本文通过实例代码给大家介绍了Android自定义dialog 自下往上弹出效果,代码简单易懂,非常不错,具有一定的参考借鉴价值,需要的朋友参考下吧2018-08-08
android 自定义ScrollView实现背景图片伸缩的实现代码及思路
本文纯属个人见解,是对前面学习的总结,如有描述不正确的地方还请高手指正~,首先还是按照通例给大家看下示例.2013-05-05
Android中使用Handler及Countdowntimer实现包含倒计时的闪屏页面
这篇文章主要介绍了Android中使用Handler及Countdowntimer实现包含倒计时的闪屏页面,非常不错,具有参考借鉴价值,需要的朋友可以参考下2017-03-03 这篇文章主要为大家详细介绍了Android实现底部支付弹窗效果的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-01-01
这篇文章主要为大家详细介绍了Android实现底部支付弹窗效果的相关资料,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2017-01-01
Android学习笔记之ActionBar Item用法分析
这篇文章主要介绍了Android学习笔记之ActionBar Item用法,结合实例形式分析了ActionBar Item的具体功能与相关使用技巧,需要的朋友可以参考下2017-05-05 在Android应用开发中,有时候需要引导用户到特定的系统设置页面,例如Wi-Fi开关设置页,可以通过隐式Intent来实现这一功能,以下是详细的步骤以及相关的Kotlin代码示例,需要的朋友可以参考下2024-09-09
在Android应用开发中,有时候需要引导用户到特定的系统设置页面,例如Wi-Fi开关设置页,可以通过隐式Intent来实现这一功能,以下是详细的步骤以及相关的Kotlin代码示例,需要的朋友可以参考下2024-09-09 这篇文章主要介绍了Android内存溢出及内存泄漏原因解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-08-08
这篇文章主要介绍了Android内存溢出及内存泄漏原因解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下2020-08-08 这篇文章主要给大家介绍了关于Android中利用zxing实现自己的二维码扫描识别的相关资料,文中通过图文介绍的非常详细,对大家学习或者使用zxing具有一定的参考学习价值,需要的朋友们下面来一起看看吧。2017-09-09
这篇文章主要给大家介绍了关于Android中利用zxing实现自己的二维码扫描识别的相关资料,文中通过图文介绍的非常详细,对大家学习或者使用zxing具有一定的参考学习价值,需要的朋友们下面来一起看看吧。2017-09-09 这篇文章主要给大家总结介绍了关于Android中传值Intent与Bundle的关系,文中通过示例代码以及图文介绍的非常详细,对各位Android开发者们具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧<BR>2022-11-11
这篇文章主要给大家总结介绍了关于Android中传值Intent与Bundle的关系,文中通过示例代码以及图文介绍的非常详细,对各位Android开发者们具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧<BR>2022-11-11










最新评论