
JAVA中的字符串常量池使用操作代码
前言
研究表明,Java堆中对象占据最大比重的就是字符串对象,所以弄清楚字符串知识很重要,本文主要重点聊聊字符串常量池。Java中的字符串常量池是Java堆中的一块特殊存储区域,用于存储字符串。它的实现是为了提高字符串操作的性能并节省内存。它也被称为String Intern Pool或String Constant Pool。那让我来看看究竟是怎么一回事吧。
理解字符串常量池
当您从在类中写一个字符串字面量时,JVM将首先检查该字符串是否已存在于字符串常量池中,如果存在,JVM 将返回对现有字符串对象的引用,而不是创建新对象。我们通过一个例子更好的来理解。
比如下面的代码:
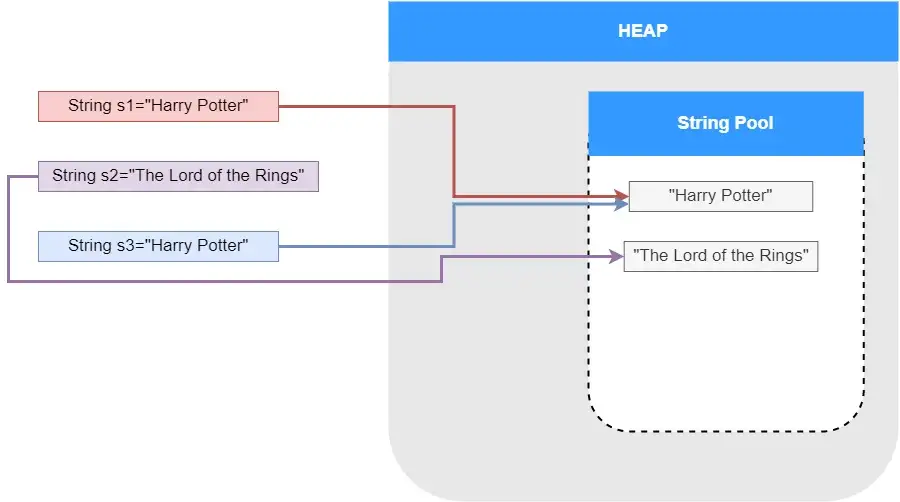
String s1 = "Harry Potter"; String s2 = "The Lord of the Rings"; String s3 = "Harry Potter";
在这段代码中,JVM 将创建一个值为“Harry Potter”的字符串对象,并将其存储在字符串常量池中。s1和s3都将是对该单个字符串对象的引用。
如果s2的字符串内容“The Lord of the Rings”不存在于池中,则在字符串池中生成一个新的字符串对象。
两种创建字符串方式
在 Java 编程语言中有两种创建 String 的方法。第一种方式是使用String Literal字符串字面量的方式,另一种方式是使用new关键字。他们创建的字符串对象是都在常量池中吗?
字符串字面量的方式创建
String s1 = "Harry Potter"; String s2 = "The Lord of the Rings"; String s3 = "Harry Potter";
new关键字创建
String s4 = new String("Harry Potter");
String s5 = new String("The Lord of the Rings");我们来比较下他们引用的是否是同一个对象:
s1==s3 //真 s1==s4 //假 s2==s5 //假
使用 == 运算符比较两个对象时,它会比较内存中的地址。

正如您在上面的图片和示例中看到的,每当我们使用new运算符创建字符串时,它都会在 Java 堆中创建一个新的字符串对象,并且不会检查该对象是否在字符串常量池中。
那么我现在有个问题,如果是字符串拼接的情况,又是怎么样的呢?
字符串拼接方式
前面讲清楚了通过直接用字面量的方式,也就是引号的方式和用new关键字创建字符串,他们创建出的字符串对象在堆中存储在不同的地方,那么我们现在来看看用+这个运算符拼接会怎么样。
例子1
public static void test1() {
// 都是常量,前端编译期会进行代码优化
// 通过idea直接看对应的反编译的class文件,会显示 String s1 = "abc"; 说明做了代码优化
String s1 = "a" + "b" + "c";
String s2 = "abc";
// true,有上述可知,s1和s2实际上指向字符串常量池中的同一个值
System.out.println(s1 == s2);
}常量与常量的拼接结果在常量池,原理是编译期优化。
例子2
public static void test5() {
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4); // true 编译期优化
System.out.println(s3 == s5); // false s1是变量,不能编译期优化
System.out.println(s3 == s6); // false s2是变量,不能编译期优化
System.out.println(s3 == s7); // false s1、s2都是变量
System.out.println(s5 == s6); // false s5、s6 不同的对象实例
System.out.println(s5 == s7); // false s5、s7 不同的对象实例
System.out.println(s6 == s7); // false s6、s7 不同的对象实例
}只要其中有一个是变量,结果就在堆中, 变量拼接的底层原理其实是StringBuilder。
例子3:
public void test6(){
String s0 = "beijing";
String s1 = "bei";
String s2 = "jing";
String s3 = s1 + s2;
System.out.println(s0 == s3); // false s3指向对象实例,s0指向字符串常量池中的"beijing"
String s7 = "shanxi";
final String s4 = "shan";
final String s5 = "xi";
String s6 = s4 + s5;
System.out.println(s6 == s7); // true s4和s5是final修饰的,编译期就能确定s6的值了
}- 不使用final修饰,即为变量。如s3行的s1和s2,会通过new StringBuilder进行拼接
- 使用final修饰,即为常量。会在编译器进行代码优化。
妙用String.intern() 方法
前面提到new关键字创建出来的字符串对象以及某些和变量进行拼接不会在字符串常量池中,而是直接在堆中新建了一个对象。这样不大好,做不到复用,节约不了空间。那有什么好办法呢?intern()就派上用场了,这个非常有用。
intern()方法的作用可以理解为主动将常量池中还没有的字符串对象放入池中,并返回此对象地址。
String s6 = new String("The Lord of the Rings").intern();
s2==s6 //真 s2==s5 //假
字符串常量池有多大?
关于字符串常量池究竟有多大,我也说不上来,但是讲清楚它底层的数据结构,也许你就明白了。
字符串常量池是一个固定大小的HashTable,哈希表,默认值大小长度是1009。如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降。
使用-XX:StringTablesize可设置StringTable的长度
- 在jdk6中
StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快。StringTable Size设置没有要求 - 在jdk7中,StringTable的长度默认值是
60013,StringTable Size设置没有要求
● 在jdk8中,设置StringTable长度的话,1009是可以设置的最小值
字符串常量池的优缺点
字符串池的优点
- 提高性能。由于 JVM 可以返回对现有字符串对象的引用而不是创建新对象,因此使用字符串池时字符串操作更快。
- 共享字符串,节省内存。字符串池允许您在不同的变量和对象之间共享字符串,通过避免创建不必要的字符串对象来帮助节省内存。
字符串池的缺点
- 它有可能导致性能下降。从池中检索字符串需要搜索池中的所有字符串,这可能比简单地创建一个新的字符串对象要慢。如果程序创建和丢弃大量字符串,则尤其如此,因为每次使用字符串时都需要搜索字符串池。
总结
其实在 Java 7 之前,JVM将 Java String Pool 放置在PermGen空间中,它具有固定大小——它不能在运行时扩展,也不符合垃圾回收的条件。在PermGen(而不是堆)中驻留字符串的风险是,如果我们驻留太多字符串,我们可能会从 JVM 得到一个OutOfMemory错误。从 Java 7 开始,Java String Pool存放在Heap空间,由 JVM进行垃圾回收。这种方法的优点是降低了OutOfMemory错误的风险,因为未引用的字符串将从池中删除,从而释放内存。
现在通过本文的学习,你该知道如何更好的创建字符串对象了吧。
到此这篇关于JAVA中的字符串常量池的文章就介绍到这了,更多相关java字符串常量池内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章
 这篇文章主要介绍了java应用cpu占用过高问题分析及解决方法,具有一定参考价值,需要的朋友可以参考下。2017-09-09
这篇文章主要介绍了java应用cpu占用过高问题分析及解决方法,具有一定参考价值,需要的朋友可以参考下。2017-09-09 这篇文章主要介绍了java8 stream排序以及自定义比较器方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-03-03
这篇文章主要介绍了java8 stream排序以及自定义比较器方式,具有很好的参考价值,希望对大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教2023-03-03
springboot配置多数据源的实例(MongoDB主从)
下面小编就为大家分享一篇springboot配置多数据源的实例(MongoDB主从),具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2017-12-12 这篇文章主要介绍了JMagick实现基本图像处理的类,实例分析了java图像处理的相关技巧,需要的朋友可以参考下2015-06-06
这篇文章主要介绍了JMagick实现基本图像处理的类,实例分析了java图像处理的相关技巧,需要的朋友可以参考下2015-06-06 FreeMarker是一款模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本的通用工具。本文将根据Freemarker模板实现生成Word文件,需要的可以参考一下2022-09-09
FreeMarker是一款模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本的通用工具。本文将根据Freemarker模板实现生成Word文件,需要的可以参考一下2022-09-09 这篇文章主要介绍了在SpringBoot中验证用户上传的图片资源,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-09-09
这篇文章主要介绍了在SpringBoot中验证用户上传的图片资源,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下2021-09-09 快速排序是通过一趟排序将要排序的数据分割为独立的两个部分,一部分的所有数据比另外一部分的所有数据要小,然后按照此方法对这两部分分别进行快速排序,整个过程可以递归进行,以此达到整个数据变成有序序列。本文通过示例讲解了快速排序的实现,需要的可以参考一下2022-11-11
快速排序是通过一趟排序将要排序的数据分割为独立的两个部分,一部分的所有数据比另外一部分的所有数据要小,然后按照此方法对这两部分分别进行快速排序,整个过程可以递归进行,以此达到整个数据变成有序序列。本文通过示例讲解了快速排序的实现,需要的可以参考一下2022-11-11 这篇文章主要介绍了java分布式面试系统限流最佳实践场景分析解答,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪2022-03-03
这篇文章主要介绍了java分布式面试系统限流最佳实践场景分析解答,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪2022-03-03
Java Stream对象并行处理方法parallel()代码示例
在Java中Stream是一种用于处理集合数据的流式操作API,它提供了一种简洁、灵活、高效的方式来对集合进行各种操作,下面这篇文章主要给大家介绍了关于Java Stream对象并行处理方法parallel()的相关资料,需要的朋友可以参考下2023-11-11 本文主要介绍了Mybatis-Plus 动态表名的实践,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2024-08-08
本文主要介绍了Mybatis-Plus 动态表名的实践,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧2024-08-08










最新评论