
mysql删除重复记录并且只保留一条的实现方法
更新时间:2023年01月04日 08:32:32 作者:jerry-89
本文主要介绍了mysql删除重复记录并且只保留一条的实现方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
准备的测试表结构及数据
插入的数据中A,B,E存在重复数据,C没有重复记录
CREATE TABLE `tab` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of tab
-- ----------------------------
INSERT INTO `tab` VALUES ('1', 'A');
INSERT INTO `tab` VALUES ('2', 'A');
INSERT INTO `tab` VALUES ('3', 'A');
INSERT INTO `tab` VALUES ('4', 'B');
INSERT INTO `tab` VALUES ('5', 'B');
INSERT INTO `tab` VALUES ('6', 'C');
INSERT INTO `tab` VALUES ('7', 'B');
INSERT INTO `tab` VALUES ('8', 'B');
INSERT INTO `tab` VALUES ('9', 'B');
INSERT INTO `tab` VALUES ('10', 'E');
INSERT INTO `tab` VALUES ('11', 'E');
INSERT INTO `tab` VALUES ('12', 'E');使用HAVING关键字筛选出表中重复数据
SELECT `name`,COUNT(1) FROM TAB GROUP BY `name` HAVING COUNT(1) >1
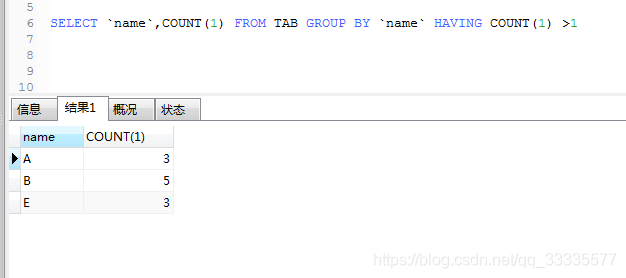
可以通过分组语句从每种重复数据中都拿出一条标识
SELECT `name`,id FROM TAB GROUP BY `name` HAVING COUNT(1) >1
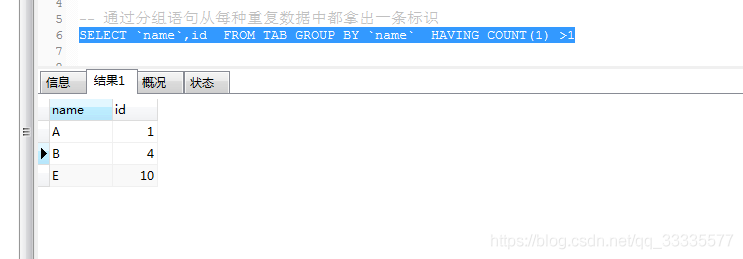
删除重复记录并且只保留一条 [留意SQL注释]
DELETE from tab where
-- 删除所有的重复时间 Begin --
`name` in (
SELECT * from (SELECT `name`FROM TAB GROUP BY `name` HAVING COUNT(1) >1) tmp2
)
-- 删除所有的重复时间 END --
-- 但一些特定ID的记录不进行删除 Begin --
AND
id NOT in(
select id from (
SELECT `name`,id FROM TAB GROUP BY `name` HAVING COUNT(1) >1
) tmp1
)
-- 但一些特定ID的记录不进行删除 END --
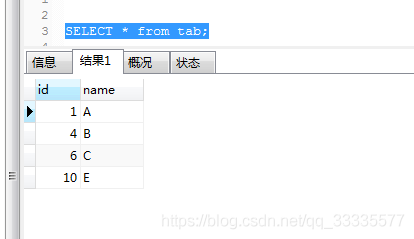
执行后最终结果
方法二
MySql如何删除所有多余的重复数据
方法一查询出的所有多余的重复记录:
方法二查询出的所有多余的重复记录(与方法一的结果相同):
方法三查询出的所有多余的重复记录:这里方法三因为用了MAX()方法(也可改用MIN()),查询结果记录的id不太一样,但也可以被视为重复多余的数据,关键是你希望选择保留哪一条记录而已。
MySql如何删除所有多余的重复数据 需要处理的数据,如:
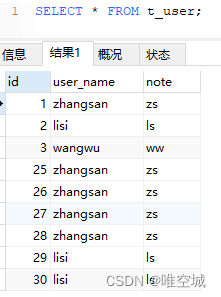
出现重复的数据,如:
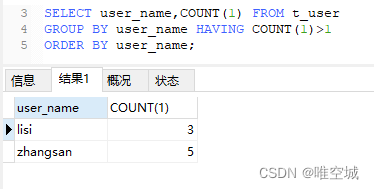
先用SELECT查询看看结果:
-- 方法一 SELECT * FROM t_user WHERE user_name IN ( SELECT user_name FROM t_user GROUP BY user_name HAVING COUNT(1)>1 ) AND id NOT IN ( SELECT MIN(id) FROM t_user GROUP BY user_name HAVING COUNT(1)>1 )
方法一查询出的所有多余的重复记录:
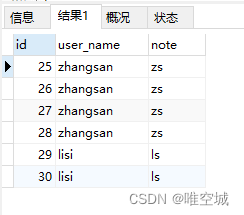
-- 方法二 SELECT * FROM t_user WHERE id NOT IN ( SELECT MIN(id) FROM t_user GROUP BY user_name )
方法二查询出的所有多余的重复记录(与方法一的结果相同):
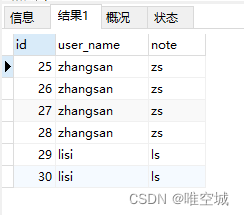
-- 方法三 SELECT * FROM t_user AS t1 WHERE t1.id <> ( SELECT MAX(t2.id) FROM t_user AS t2 WHERE t1.user_name=t2.user_name )
方法三查询出的所有多余的重复记录:
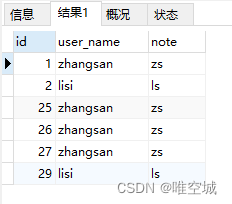
这里方法三因为用了MAX()方法(也可改用MIN()),查询结果记录的id不太一样,但也可以被视为重复多余的数据,关键是你希望选择保留哪一条记录而已。
下面是对上面的SELECT语句稍作修改并加入了DELETE
-- 方法一(笨方法但容易理解)
DELETE FROM t_user WHERE user_name IN (
SELECT t1.user_name FROM (
-- 查询出所有重复的user_name
SELECT user_name FROM t_user GROUP BY user_name HAVING COUNT(1)>1
) t1
)
AND id NOT IN (
SELECT t2.min_id FROM (
-- 查询出所有重复的记录并各自只取其中一条(MIN(id)或MAX(id)都可以)
SELECT MIN(id) AS min_id FROM t_user GROUP BY user_name HAVING COUNT(1)>1
) t2
)
-- 方法二(推荐方法也容易理解)
DELETE FROM t_user WHERE id NOT IN (
SELECT t.min_id FROM (
-- 过滤出重复多余的数据,比如,如果所有记录中存在1条记录是user_name=zhangsan的,那么就取出它;
-- 如果所有记录中存在多条记录是user_name=lisi的,那么只取其中1条,其他的不查询出来
SELECT MIN(id) AS min_id FROM t_user GROUP BY user_name
) t
)
-- 方法三(推荐方法但不太容易理解)
DELETE FROM t_user WHERE id IN (
SELECT t.id FROM (
-- 1. 关于所有存在相同user_name的记录,只查询出(保留)重复记录中的1条,假设这样查询出来的集合为A集合。
-- 2. 在所有记录中,只要id不在A集合中的,都把它们查询出来
SELECT t1.id FROM t_user AS t1 WHERE t1.id <> (SELECT MAX(t2.id) FROM t_user AS t2 WHERE t1.user_name=t2.user_name)
) t
)
-- 或
DELETE FROM t_user t1
WHERE t1.id <> (
SELECT t2.max_id FROM (
SELECT MAX(t3.id) AS max_id FROM t_user t3 WHERE t1.user_name=t3.user_name
) t2
)最后删除成功之后,显示数据已经没有重复的了
参考:
如何实现 MySQL 中通过SQL语句删除重复记录并且只保留一条记录
到此这篇关于mysql删除重复记录并且只保留一条的实现方法的文章就介绍到这了,更多相关mysql删除重复记录 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
相关文章

windows下mysql 5.7.20 安装配置方法图文教程
这篇文章主要为大家详细介绍了windows下mysql 5.7.20 安装配置方法图文教程,具有一定的参考价值,感兴趣的小伙伴们可以参考一下2018-09-09 当涉及到大量数据时,对于 ORDER BY 操作,可以考虑为相应的列添加索引,如果不使用索引,mysql会使用filesort来进行排序,这篇文章主要介绍了mysql order by 排序原理,需要的朋友可以参考下2024-02-02
当涉及到大量数据时,对于 ORDER BY 操作,可以考虑为相应的列添加索引,如果不使用索引,mysql会使用filesort来进行排序,这篇文章主要介绍了mysql order by 排序原理,需要的朋友可以参考下2024-02-02 在实际开发中,每条数据的创建时间和修改时间,尽量不需要应用程序去记录,而由数据库获取当前时间自动记录创建时间,本文主要介绍了java实现mysql自动更新创建时间与更新时间的两种方式,感兴趣的可以了解一下2024-01-01
在实际开发中,每条数据的创建时间和修改时间,尽量不需要应用程序去记录,而由数据库获取当前时间自动记录创建时间,本文主要介绍了java实现mysql自动更新创建时间与更新时间的两种方式,感兴趣的可以了解一下2024-01-01 本文给大家讲解的是mysql数据库InnoDB类型,在update表的时候出现死锁现象的原因及解决办法,有需要的小伙伴可以参考下。2016-03-03
本文给大家讲解的是mysql数据库InnoDB类型,在update表的时候出现死锁现象的原因及解决办法,有需要的小伙伴可以参考下。2016-03-03 这篇文章主要介绍了mysql 实现设置多个主键的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-02-02
这篇文章主要介绍了mysql 实现设置多个主键的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧2021-02-02 MySQL锁是操作MySQL数据库时常用的一种机制。MySQL锁可以保证多个用户在同时执行读写操作时,能够互相协同、避免数据出现不一致或者读写冲突等问题。本篇文章将详细介绍MySQL锁的基本知识和具体应用2023-03-03
MySQL锁是操作MySQL数据库时常用的一种机制。MySQL锁可以保证多个用户在同时执行读写操作时,能够互相协同、避免数据出现不一致或者读写冲突等问题。本篇文章将详细介绍MySQL锁的基本知识和具体应用2023-03-03 这篇文章主要介绍了详解MySQL导出指定表中的数据的实例的相关资料,希望通过本文能帮助到大家,需要的朋友可以参考下2017-09-09
这篇文章主要介绍了详解MySQL导出指定表中的数据的实例的相关资料,希望通过本文能帮助到大家,需要的朋友可以参考下2017-09-09 这篇文章主要介绍了mysql添加索引反而速度变慢的问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-01-01
这篇文章主要介绍了mysql添加索引反而速度变慢的问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教2024-01-01 本篇文章是对Mysql中OPTIMIZE TABLE的作用进行了详细的分析介绍,需要的朋友参考下2013-06-06
本篇文章是对Mysql中OPTIMIZE TABLE的作用进行了详细的分析介绍,需要的朋友参考下2013-06-06 这篇文章主要为大家介绍了MySQL如何使用离线模式维护服务器,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-10-10
这篇文章主要为大家介绍了MySQL如何使用离线模式维护服务器,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪2023-10-10










最新评论